



































In this blog, we will take an in-depth look at fuzzy matching, the go-to approach for data deduplication and record linkage. We will cover:
- What is Fuzzy Matching?
- Why Do Businesses Need Fuzzy Matching?
- Example of a Real-World Fuzzy Matching Scenario
- Fuzzy Matching Techniques
- Pros and Cons of Fuzzy Matching
- How to Minimize False Positives and Negatives
- Fuzzy Matching Scripts vs Fuzzy Matching Software: Which is Better?
- How to Run Fuzzy Matching in DataMatch Enterprise
What is Fuzzy Matching?
Rather than flagging records as a ‘match’ or ‘non-match’, fuzzy matching identifies the likelihood that two records are a true match based on whether they agree or disagree on the various identifiers.
The identifiers or parameters you choose here and the weight you assign forms the basis of fuzzy matching. If the parameters are too broad, you will find more matches, true, but you will also invariably increase the chances of ‘false positives’. These are pairs that are identified by your algorithm or fuzzy matching software of choice as a match, but upon manual review, you will find that your approach identified a false positive.
Consider the strings “Kent” and “10th”. While there is clearly no match here, popular fuzzy matching algorithms still rate these two strings nearly 50% similar, based as character count and phonetic match. Check for yourself.
False positives are one of the biggest issues with fuzzy matching. The more efficient the system you’re using, the fewer the false positives. An efficient system will identify:
- Acronyms
- name reversal
- name variations
- phonetic spellings
- deliberate misspellings
- inadvertent misspellings
- abbreviations e.g. ‘Ltd’ instead of ‘Limited’
- insertion/removal of punctuation, spaces, special characters
- different spelling of names e.g. ‘Elisabeth’ or ‘Elizabeth’, ‘Jon’ instead of ‘John’
- shortened names e.g. ‘Elizabeth’ matches with ‘Betty’, ‘Beth’, ‘Elisa’, ‘Elsa’, ‘Beth’ etc.
And many other variations.
Why Do Businesses Need Fuzzy Matching?
Research reveals that 94% of businesses admit to having duplicate data, and the majority of these duplicates are non-exact matches and therefore usually remain undetected. Fuzzy matching software helps you make those connections automatically using sophisticated proprietary matching logic, regardless of spelling errors, unstandardized data, or incomplete information.
But it’s not just about deduplication. From a strategic perspective, fuzzy matching comes into play when you’re conducting record linkage or entity resolution. We touched upon this briefly in the previous section too; the fuzzy matching approach is invaluable when creating a Single Source of Truth for business analytics or building a foundation for Master Data Management (MDM), helping organizations integrate data from dozens of different sources across the enterprise while ensuring accuracy and minimizing manual review. See how a major healthcare provider was able to save hundreds of man-hours annually.
Here are some ways that fuzzy matching is used to improve the bottom-line:
- Realize a Single Customer View
- Work with Clean Data You Can Trust
- Prepare Data for Business Intelligence
- Enhance the Accuracy of Your Data for Operational Efficiency
- Enrich Data for Deeper Insights
- Ensure Better Compliance
- Refine Customer Segmentation
- Improve Fraud Prevention
Learn more about the benefits of fuzzy matching.
Establishing data quality standards for business success
Download this whitepaper and learn the struggle of hosting data in Salesforce, Fusion, Excel, and other asset management systems, and how data quality is the key factor to business success.
DownloadExample of a Real-World Fuzzy Matching Scenario
The following example shows how record linkage techniques can be used to detect fraud, waste or abuse of federal government programs. Here, two databases were merged to get information not previously available from a single database.
A database consisting of records on 40,000 airplane pilots licensed by the U.S. Federal Aviation Administration (FAA) and residing in Northern California was matched to a database consisting of individuals receiving disability payments from the Social Security Administration. Forty pilots whose records turned up on both databases were arrested.
A prosecutor in the U.S. Attorney’s Office in Fresno, California stated, according to an AP report:
“There was probably criminal wrongdoing.” The pilots were either lying to the FAA or wrongfully receiving benefits. The pilots claimed to be medically fit to fly airplanes. However, they may have been flying with debilitating illnesses that should have kept them grounded, ranging from schizophrenia and bipolar disorder to drug and alcohol addiction and heart conditions.”
At least twelve of these individuals “had commercial or airline transport licenses,” the report stated. The FAA revoked 14 pilots’ licenses. The other pilots were found to be lying about having illnesses in order to collect Social Security payments.
The quality of the linkage of the files was highly dependent on the quality of the names and addresses of the licensed pilots within both of the files being linked. The detection of the fraud was also dependent on the completeness and accuracy of the information in a particular Social Security Administration database.
See how companies in your vertical are using fuzzy matching today.
Fuzzy Matching Techniques
Now you know what fuzzy matching is and the many different ways you can use it to grow your business. Question is, how do you about implementing fuzzy matching processes in your organization?
Here’s a list of the various fuzzy matching techniques that are in use today:
- Levenshtein Distance (or Edit Distance)
- Damerau-Levenshtein Distance
- Jaro-Winkler Distance
- Keyboard Distance
- Kullback-Leibler Distance
- Jaccard Index
- Metaphone 3
- Name Variant
- Syllable Alignment
- Acronym
Get more information on fuzzy matching algorithms.
Pros and Cons of Fuzzy Matching
Since fuzzy matching is based on probabilistic approach to identifying matches, it can offer a wide range of benefits such as:
· Higher matching accuracy: fuzzy matching proves to be a far more accurate method of finding matching across two or more datasets. Unlike deterministic matching that determines matches on a 0 or 1 basis, fuzzy matching can detect variations that lie between 0 and 1 basis on a given matching threshold.
· Provides solutions to complex data: fuzzy logic also enables users to find matches by linking records that consist of slight variations in the form of spelling, casing, and formatting errors, null values, etc., making it better-suited for real-world applications where typos, system errors, and other data errors can occur. This also includes dynamic data that become obsolete or must be updated constantly such as job title and email address.
· Easily configurable to effect false positives: when the number of false positives need to be lowered or increased to suit business requirements, users can easily adjust the matching threshold to manipulate the results or have more matches for manual inspection. This gives users added flexibility when tailoring fuzzy logic algorithms to specific matching requirements.
· Better suited to finding matches without a consistent unique identifier: having unique identifier data, such as SSN or date of birth, is critical for finding matches across disparate data sources in the case of deterministic matching. However, using a statistical analysis approach, fuzzy matching can help find duplicates even without consistent identifier data.
However, fuzzy matching is not without limitations. These include:
· Can incorrectly link different entities: despite the configurability available in fuzzy matching, high false positives due to incorrect linkage of seemingly similar. But different entities can lead to more time spent on manually checking duplicates against unique identifiers.
· Difficult to scale across larger datasets: fuzzy logic can be difficult to scale across millions of data points especially in the case of disparate data sources.
· Can require considerable testing for validation: the rules defined in the algorithms must be constantly refined and tested to ensure it is able to run matches with high accuracy.
How to Minimize False Positives and Negatives
We have discussed false positives in the previous section briefly. While they make matching more difficult by adding manual review time to the process. They’re not a genuine risk to the business because the system will flag false positives based on the overall match score. Let’s take a look at ‘false negatives’ now. This refers to matches that are missed altogether by the system: not just a low match score, but an absence of match score. This leads to a serious risk for the business as false negatives are never reviewed because no one knows they exist. Factors that commonly lead to false negatives include:
- Lack of relevant data
- Significant errors in data entry
- System limitations
- Match criterion is too narrow
- Inappropriate level of fuzzy matching
The most effective method to minimize both false positives and negatives is to profile and clean the data sources separately before you conduct matching. Leading data matching solution providers typically bundle a data profiler that quickly provides enough metadata to construct a cogent profile analysis of data quality, as in missing values, lack of standardization, any other discrepancies in your data. By profiling your data, you can quickly quantify the scope and depth of the primary project, whether it’s Master Data Management, matching, cleansing, deduplication, or standardization.
Once you’ve profiled your data, you will know exactly which business rules to apply to clean and standardize your data most efficiently. You will also be able to quickly recognize and fill missing values, perhaps by purchasing 3rd party data.
Cleaner, more complete data reduces false positives and negatives significantly by increasing match accuracy because your data is now standardized. The fuzzy matching algorithms you use, the matching criteria you define, the weight you assign to different parameters, the way you combine different algorithms and assign priority. These are all important factors in minimizing false positives and negatives too. But none of these are going to help much if you haven’t profiled and cleaned your data first. See how DataMatch Enterprise has helped 4,000+ customers in over 40 countries clean, deduplicate, and link their data efficiently.
Fuzzy Matching Scripts vs. Fuzzy Matching Software: Which is Better?
Fuzzy Matching Scripts
Fuzzy logic can easily be applied from manual coding scripts that are available in various programming languages and applications. Some of these include:
· Python: Python libraries such as FuzzyWuzzy can be used to run string matching in an easy and intuitive method. Using the Python Record Linkage Tookit, users can run several indexing methods including sorted neighborhood and blocking and identify duplicates using FuzzyWuzzy. Although Python is easy to use, it can be slower to run matches than other methods.
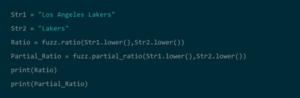
Source: DataCamp
· Java: Java includes several string similarity algorithms such as the java-string-similarity package that consists of algorithms such as Levenshtein, Jaccard Index, and Jaro-Wrinkler. Alternatively, the python algorithm FuzzyWuzzy can be utilized within Java to run matches. Here is an example below:

Source: GitHub
· Excel: The Fuzzy Look-up add-in can be utilized to run fuzzy matching between two datasets. The add-in has a simple interface including the option to select the output columns as wells as number of matches and similarity threshold. However, functionality can also give high false positives as it may not properly identify duplicates. An example of this is ‘ATT CORP’ and ‘AT&T Inc.’
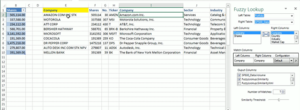
Source: Mr.Excel.com
Fuzzy Matching Software
On the other hand, fuzzy matching software is equipped with one or several fuzzy logic algorithms, along with exact and phonetic matching. To identify and match records across millions of data points from multiple and disparate data sources including relational databases, web applications, and CRMs.
Fuzzy matching tools come with prebuilt data quality functions such as data profiling and data cleansing and standardization transformations. To efficiently refine and improve the accuracy of matches between two or more datasets.
Unlike matching scripts, such tools are far easier to deploy and run matches owing to a point-and-click interface.
Which is Better?
Choosing either of the two approaches comes down to the following factors:
Time
Matching scripts have the benefit of being easy to deploy at users’ convenience. However, the constant refinement and testing needed to ensure its efficiency. Especially across hundreds and thousands of records, can involve weeks if not months of work. In scenarios where duplicates and matches have to be found more quickly to meet tight project deadlines. A fuzzy matching tool proves to be far more reliable and convenient in running matches across very large datasets within a days or a few hours’ worth of time.
Cost
Manual coding scripts are inexpensive to use in comparison with matching tools provided that the number of records is small. For datasets comprising of millions or billions of records, however, the cost of using scripts can far outweigh those of matching tools considering the time and resources used to cater to the
Scalability
Fuzzy logic scripts tend to work better for a few thousand records. Where the variations in data are not too many otherwise the rules can fall apart and require more refinement, making it difficult to scale.
A fuzzy matching tool whereas comes equipped with the capacity to run matches against millions of data points within a few hours as well as batch and real-time automation capabilities to minimize repetitive tasks and man-hours.
Complexity of Data
Users may want to find matches or duplicates across a few thousand records. In contrast, federal agencies, public institutions, and companies often have non-homogenous datasets from multiple sources – Excel, CSV, relational databases, legacy mainframe data, and Hadoop-based repositories. For this, a dedicated matching tool can be more adept in ingesting all relevant sources, profile all known data quality issues and remove them using out-of-the-box cleansing transformations.
In the case of manual coding scripts, on the other hand, users have to write multiple complex fuzzy logic rules to account for the disparity in data and its anomalies – making it highly tedious and time-intensive.
The definitive buyer’s guide to data quality tools
Download this guide to find out which factors you should consider while choosing a data quality solution for your specific business use case.
DownloadIt Made Easy, Fast, and Laser-Focused on Driving Business Value
Traditionally, fuzzy matching has been considered a complex, arcane art, where project costs are typically in the hundreds of thousands of dollars, taking months, if not years, to deliver tangible ROI. And even then, security, scalability, and accuracy concerns remain. That is no longer the case with modern data quality software. Based on decades of research and 4,000+ deployments across more than 40 countries, DataMatch Enterprise is a highly visual data cleansing application specifically designed to resolve data quality issues. The platform leverages multiple proprietary and standard algorithms to identify phonetic, fuzzy, miskeyed, abbreviated, and domain-specific variations.
Build scalable configurations for deduplication & record linkage, suppression, enhancement, extraction, and standardization of business and customer data and create a Single Source of Truth to maximize the impact of your data across the enterprise.
How to Run It in DataMatch Enterprise
Running fuzzy matching in DataMatch Enterprise is a simple, step-by-step process comprising of the following:
- Data Import
- Data Profiling
- Data Cleansing and Standardization
- Match Configuration
- Match Definitions and
- Match Results
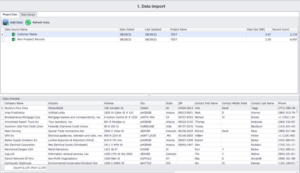
Firstly, we import the datasets we will use to find matches and use the data preview option to glance through the records. In our example, these are ‘Customer Master’ and ‘New Prospect Records’ as shown below.
Secondly, we move on to the Data Profile module to identify all kinds of statistical data anomalies, errors, and potential problem areas that would need to be fixed or refined before moving on to any matching.
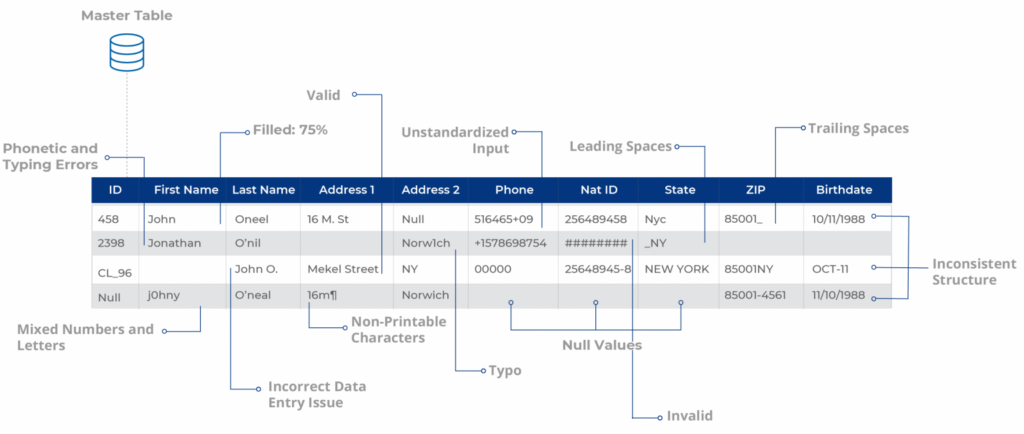
As shown below, the New Prospect Records dataset is profiled in terms of valid and invalid records, null values, distinct, numbers only, letters only, leading spaces, punctuation errors, and much more.
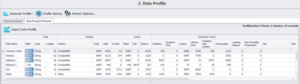
Once we have profiled, we proceed to the data cleansing and standardization module where we fix casing errors, remove trailing and leading spaces, replace zeros with Os and vice versa and parse fields like name and address into multiple smaller increments.
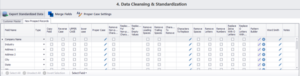
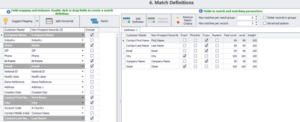
After refining our data, we select the type of match configuration we need for our matching activity: All, Between, Within, or None. For our example, we will select Between to find matches only across the two datasets.

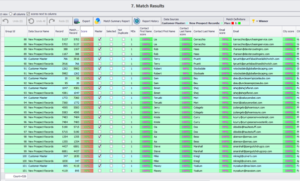
In Match Definitions, we will select the match definition or match criteria and ‘Fuzzy’ (depending on our use-case) as set the match threshold level at ‘90’ and use ‘Exact’ match for fields City and State and then click on ‘Match’.
Based on our match definition, dataset, and extent of cleansing and standardization. We get 526 matches each with a corresponding match score from 100% and below. Should we need more false positives to inspect manually, users can easily go back and lower the threshold level.
For more information on how you can deploy fuzzy matching in DataMatch Enterprise for your business use-case, contact us today.
Getting Started with DataMatch Enterprise
Download this guide to find out the vast library of features that DME offers and how you can achieve optimal results and get the most out of your data with DataMatch Enterprise.
DownloadCompanies need the best-in-class tools to process this data and make sense out of it. This white paper will explore the challenges of matching. How different types of matching algorithms work, and how best-in-class software uses these algorithms to achieve data matching goals.
How best-in class fuzzy matching solutions work
Read this whitepaper to explore the challenges of matching, how different types of matching algorithms, how a best-in-class software uses these algorithms to achieve data matching goals.
Download


