





























Last Updated on Januar 1, 2026
Namens- und Adressdaten sind von entscheidender Bedeutung, wenn es darum geht, den Markt und die Kunden eines Unternehmens genau zu bestimmen und damit auch die Positionierung des Produkts. Banken, Gesundheitsdienstleister und andere Institutionen führen beispielsweise routinemäßig Datenbereinigungen durch (z. B. Profilerstellung, Datenzusammenführung und -bereinigung), um Namens- und Adressfelder zu aktualisieren und Anomalien zu beseitigen, die durch manuelle Eingabe, mangelnde Standardisierung und Systemfehler entstanden sind.
Fehlende Angaben, Rechtschreib- und Zeichensetzungsfehler sind jedoch nur eine Seite des Problems der schlechten Datenqualität. Doppelte Namensfelder, inkonsistente Feldformate und abgekürzte Adressinformationen können sich als eine weitaus komplexere Herausforderung erweisen.
Daher kann eine Datenbereinigung, die aus ausgeklügelten Umwandlungen von Namen und Adressformaten besteht, eine weitaus bessere Alternative zur Verbesserung der allgemeinen Datenintegrität sein. Schauen wir uns an, wie Data Ladder’s DataMatch Enterprise dies ermöglicht.
Was ist Data Scrubbing?
Laut Techopedia bezieht sich Data Scrubbing auf das „Verfahren zur Änderung oder Entfernung unvollständiger, falscher, ungenau formatierter oder sich wiederholender Daten in einer Datenbank“ – alles Fehler, die den Zustand der Unternehmensdaten beeinträchtigen können.
Data Scrubbing wird austauschbar mit Datenbereinigung verwendet. Obwohl ersteres mehr mit der Einstellung von Validierungsprüfungen und dem Entfernen von Duplikaten zu tun hat, haben beide das Endziel, Datenanomalien zum Zwecke der Datengenauigkeit zu entfernen.
Normalerweise können Unternehmen mit Data Scrubbing die folgenden Arten von schlechten Daten erkennen und bereinigen:
- Allgemeine und grundlegende Fehler: Diese Fehler können sich in den Datenbanken der Unternehmen einschleichen, meist aufgrund von manuellen Eingabefehlern. Rechtschreib- oder Tippfehler („Johnn“ vs. „John“), Fehler in der Schreibweise („JOHN“, „john“ oder „jOHN“), Zeichensetzungsfehler („OConnor“ vs. „O’Connor“) fallen alle unter diese Kategorie.
- Doppelte Daten: Es kann zu doppelten Einträgen kommen, weil die Felder für Textnamen und Adressen nicht ordnungsgemäß validiert wurden. Ein gängiges Beispiel ist, dass ein Unternehmen über mehrere unterschiedliche Quellen verfügt, von denen jede eine eindeutige Version desselben Namens oder Adressdatensatzes erfasst.
- Inkonsistente Daten: Hierbei handelt es sich um Formatfehler in Form von fehlenden wesentlichen Informationen oder vertauschten Daten. So kann z. B. „Avenue street“ als „Ave St“ erfasst werden, oder es fehlen ganz die sekundären Adressdaten. Beispiele für vertauschte Daten oder falsche Datenformate können sein: „Smith John“ oder „Mr. Smith“ anstelle von „John Smith“, „68 Bridge Street, CT 06078, Suite 307“ anstelle von „68 Bridge Street, Suite 307, Suffield, Connecticut, 06078“.
DataMatch Enterprise’s Name und Adresse Transformationen
Das Auffinden und Entfernen von doppelten und redundanten Daten ist ein wesentlicher Bestandteil des Data-Scrubbing-Prozesses. Aber wie stellen Sie sicher, dass jeder Abgleich von Namens- und Adressfeldern (insbesondere bei unterschiedlichen Datenquellen) auf einer gleichartigen Basis erfolgt, um falsch positive und negative Ergebnisse zu minimieren?
Schließlich kann es viele Fälle von scheinbar unterschiedlichen Namen und Adressen in mehr als einer Datenquelle geben, bei denen es sich um eine Dublette handeln kann oder auch nicht. Nehmen wir das folgende Beispiel mit drei Datensätzen: Quelle A, Quelle B und Quelle C.
Quelle A
| Vorname | Mittlerer Name | Nachname | Adresse | Staat |
|---|---|---|---|---|
| Michael | Keith | Andrews | Suite # 35, Avenue Street | NY |
Quelle B
| Name | Straße Nummer | Staat |
|---|---|---|
| Mike | 123 Ave St. | NY |
Quelle C
| Name | Straße Nummer | Postleitzahl |
|---|---|---|
| Herr Andrews | Haus 35, 123 NY | 10001 |
Jede Datenquelle hat ein anderes Format für die Erfassung von Namen und Adressen. Wenn man sich diese Quellen ansieht, könnte man meinen, dass Michael Keith Andrews, Mike und Mr. Andrews auf den ersten Blick drei verschiedene Personen sind. Bei näherer Betrachtung ist es jedoch wahrscheinlich, dass es sich um ein und dieselbe Person handelt und dass drei verschiedene Varianten in mehreren Quellen verzeichnet wurden. Um herauszufinden, ob es doppelte und redundante Daten in vielen Datenquellen gibt, sollten die unterschiedlichen Feldformate standardisiert werden, um einen leichteren Abgleich zu ermöglichen (siehe unten).
| Datenquelle | Vorsilbe | Vorname | Mittlerer Name | Nachname | Adresse 1 | Adresse 2 | Staat | Postleitzahl |
|---|---|---|---|---|---|---|---|---|
| A | Michael | Keith | Andrews | Alleestraße | Suite 35 | NY | ||
| B | Mike | 123 Ave St. | NY | |||||
| C | Herr | Andrews | 123 | Suite 35 | NY | 10001 |
Wenn wir die Daten im obigen Format anordnen, können wir sagen, dass es sich mit hoher Wahrscheinlichkeit bei allen drei Personen um dieselbe Person handelt.
Wie funktioniert es?
DataMatch Enterprise ist mit integrierten Datentransformationen ausgestattet, die inkonsistente Namens- und Adressfeldformate korrigieren. Wenn Sie auf eine der ausgewählten Transformationen aus dem unten gezeigten Dropdown-Menü klicken, kann Datamatch Enterprise die ausgewählten Felder automatisch in kleinere Inkremente anordnen, um sicherzustellen, dass die Formate übereinstimmen.
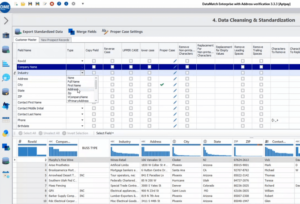
Auf diese Weise können die Datensätze leicht miteinander verglichen und die entsprechenden Abgleichsregeln (z. B. unscharfer, phonetischer oder exakter Abgleich) für die Entitätsauflösung, Deduplizierung und Stammdatenanreicherung definiert werden.
Ändern von Namensfeldern
Um Namensfelder umzuwandeln, wählen Sie die Registerkarte der Datenquelle („Neue Interessentendatensätze“), die Sie importiert haben, bewegen Sie den Mauszeiger über das Feld „Typ“ neben dem Namensfeld („Kontaktname“) und wählen Sie „Vollständiger Name“ aus der Dropdown-Liste.
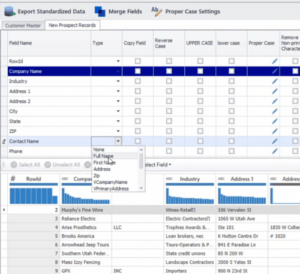
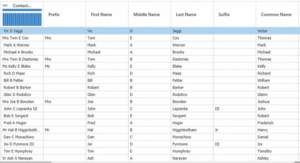
Sobald die Umwandlung wirksam wird, werden die Einträge im Feld „Kontaktname“ in Präfix, Vorname, zweiter Vorname, Nachname, Suffix und Common Name geordnet, wie in Abbildung 4 dargestellt. Das Feld für den gemeinsamen Namen wird von der DataMatch Enterprise-eigenen Spitznamenbibliothek generiert und ist eine zusätzliche Funktion zur Verbesserung der Verbindungen zwischen Spitznamen und gemeinsamen Namen (z.B. Vic als Victor, Tom als Thomas).
Ändern von Adressfeldern
Sie können auch die Transformation „Adresse“ verwenden, um Adressfelder in Adresse 1 und Adresse 2, Stadt, Bundesland und andere Inkremente aufzuteilen. Wie bei der Umwandlung von „Vollständiger Name“ können Sie auf „Adresse“ klicken, um die Änderungen zu übernehmen.

Wenn Sie auf die Transformation klicken, werden die Daten von Adresse 1 in verschiedene andere Unterfelder aufgeteilt, wie in Abbildung 6 dargestellt.
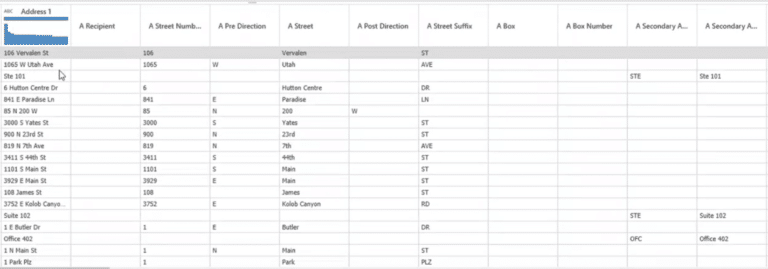
Sie können dann die relevanten Felder für Ihr neues benutzerdefiniertes Adressfeld auswählen, indem Sie die Option „Felder zusammenführen“ verwenden. Sie können zum Beispiel eine Hausnummer, eine Straße und eine Postleitzahl auswählen und ein neues Adressfeld erstellen.
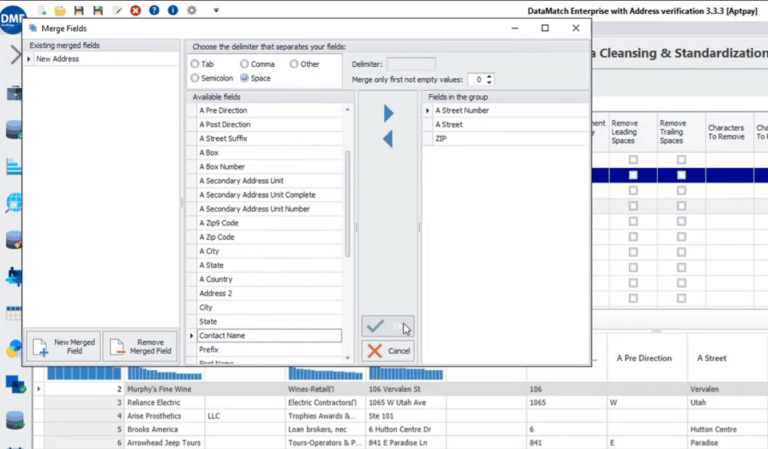
Abgleich und Deduplizierung
Nach der Standardisierung der Felder nach einem bestimmten Format können wir jedes Feld genauer zuordnen, um eine höhere Trefferquote zu erzielen und falsch positive und negative Ergebnisse zu minimieren. Anhand des oben erwähnten Beispiels der Namensfelder in Abbildung 4 können wir entscheiden, Vornamen mit Vornamen und Nachnamen mit Nachnamen in den beiden Datenquellen mithilfe von Fuzzy Matching wie folgt abzugleichen:

Die Übereinstimmungen werden dann zu separaten Gruppen-IDs kombiniert, und die sich daraus ergebenden Übereinstimmungsergebnisse können verwendet werden, um doppelte und goldene Datensätze zu identifizieren.

Schlussfolgerung
Es ist unvermeidlich, dass Namens- und Adressfelder in Datenbanken, Excel-Dateien, Unternehmensanwendungen usw. in unterschiedlichen Formaten vorliegen. Unternehmen wie Banken, Gesundheitsdienstleister und andere Institutionen können es sich nicht leisten, die kleinste Diskrepanz in den Formaten zu übersehen, die sich negativ auf die Genauigkeit des Abgleichs und der Deduplizierung auswirkt.
Um diese Herausforderung zu meistern, können Unternehmen mit den Namens- und Adressfeldtransformationen von DataMatch Enterprise ähnliche Zuordnungen sicherstellen und redundante oder doppelte Einträge leicht erkennen, um ihre Datenintegrität zu maximieren.
Für weitere Informationen über DataMatch Enterprise’s Data Scrubbing Lösungen, klicken Sie hier.

Wie die besten Fuzzy-Matching-Lösungen funktionieren: Kombination von bewährten und eigenen Algorithmen
Starten Sie noch heute Ihren kostenlosen Test



