































Last Updated on December 9, 2025
Name and address data is critical to determining the accuracy of a company’s market and customers, and subsequently, their product positioning. Banks, healthcare providers and other institutions, for instance, perform data scrubbing activities routinely (e.g., profiling, data merging and cleansing) to update name and address fields and remove anomalies arising from manual entry, lack of standardization, and system errors.
However, missing, spelling, casing or punctuation errors are only one side to the bad data quality problem. Duplicate name fields, inconsistent field formats, and abbreviated address information can prove to be a far complex challenge.
Hence, data scrubbing consisting of sophisticated name and address format transformations can be a far better alternative to improve overall data integrity. Let us look at how Data Ladder’s DataMatch Enterprise enables this.
What is Data Scrubbing?
According to Techopedia, data scrubbing refers to the “procedure of modifying or removing incomplete, incorrect, inaccurately formatted, or repeated data in a database” – all errors that can adversely compromise the health of company data.
Data scrubbing is used interchangeably with data cleansing. Although the former has more to do with setting validation checks and removing duplicates, both have the end goal of removing data anomalies for data accuracy purposes.
Usually, data scrubbing allows companies to detect and scrub the following types of bad data:
- General and basic errors: these errors can creep inside company databases mostly due to manual entry mistakes. Misspellings or typos (‘Johnn’ vs. ‘John’), casing errors (‘JOHN’, ‘john’, or ‘jOHN’), punctuation errors (‘OConnor’ vs. ‘O’Connor’) all come under this category.
- Duplicate data: duplicate entries can exist due to a lack of proper validation of text name and address fields. A common example is when a company has multiple disparate sources, each recording a unique version of the same name or address record.
- Inconsistent data: these are format errors that are in the form of missing essential information or transposed data. For example, ‘Avenue street’ can be recorded as ‘Ave St’ or miss out secondary address data entirely. Transposed data or wrong data format examples can include: ‘Smith John’ or ‘Mr. Smith’ instead of ‘John Smith’, ’68 Bridge Street, CT 06078, Suite 307’ instead of ’68 Bridge Street, Suite 307, Suffield, Connecticut, 06078’.
DataMatch Enterprise’s Name and Address Transformations
Finding and removing duplicate and redundant data is an integral part of the data scrubbing process. But how do you make sure that any matching of name and address fields (especially across disparate data sources) is done on a like-with-like basis to minimize false positives and negatives?
After all, there can be many instances of seemingly different names and address in more than one data source that may or may not be a duplicate. Take the following example of three datasets: Source A, Source B, and Source C.
Source A
| First Name | Middle Name | Last Name | Address | State |
|---|---|---|---|---|
| Michael | Keith | Andrews | Suite # 35, Avenue Street | NY |
Source B
| Name | Street Number | State |
|---|---|---|
| Mike | 123 Ave St. | NY |
Source C
| Name | Street Number | Zip Code |
|---|---|---|
| Mr. Andrews | House 35, 123 NY | 10001 |
Each data source has a different format for recording names and addresses. Looking at these sources, it may seem that Michael Keith Andrews, Mike, and Mr. Andrews are three different persons at first glance. But upon close inspection, it is likely that there are all the same person and that three different variations have been recorded on multiple sources.So here’s the key question: how will you identify which names should match and which don’t? To find if there are duplicate and redundant data across many data sources, the varying field formats should be standardized to enable easier matching as shown below.
| Data Source | Prefix | First Name | Middle Name | Last Name | Address 1 | Address 2 | State | Zip Code |
|---|---|---|---|---|---|---|---|---|
| A | Michael | Keith | Andrews | Avenue Street | Suite 35 | NY | ||
| B | Mike | 123 Ave St. | NY | |||||
| C | Mr. | Andrews | 123 | Suite 35 | NY | 10001 |
By arranging the data in the above format, we can say that there is a high likelihood that all of the three entities are the same person.
How Does it Work?
DataMatch Enterprise comes equipped with built-in data transformations to correct inconsistent name and address field formats. Upon clicking any of the chosen transformations from the drop-down menu shown below, Datamatch Enterprise can automatically arrange the chosen fields into smaller increments to ensure the formats are in conformity.
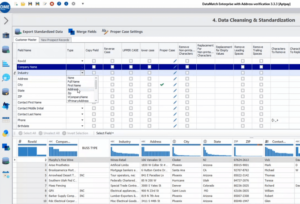
By doing so, the records can then easily be compared with one another and the appropriate matching rules (e.g., fuzzy, phonetic, or exact matching) be defined for entity resolution, deduplication, and master data enrichment purposes.
Modifying Name Fields
To transform name fields, select the data source tab (‘New Prospect Records’) you have imported, hover over the ‘Type’ field next to the name field (‘Contact Name’) and choose ‘Full Name’ from the drop-down list.
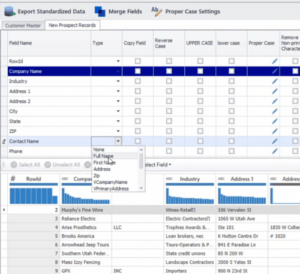
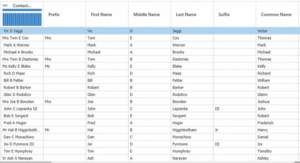
Once the transformation takes effect, the entries in the ‘Contact Name’ field are then arranged into prefix, first name, middle name, last name, suffix, and common name as shown in Figure 4. The common name field is generated by DataMatch Enterprise’s proprietary nickname library and is an additional feature to improve links between the nickname and common name (e.g. Vic as Victor, Tom as Thomas).
Modifying Address Fields
You can also use the ‘Address’ transformation to split address fields into Address 1 and Address 2, city, state and other increments. Like the ‘Full Name’ transformation, you can click on ‘Address’ to apply the changes.

Upon clicking the transformation, the Address 1 data is split into various other sub-fields as shown in Figure 6.
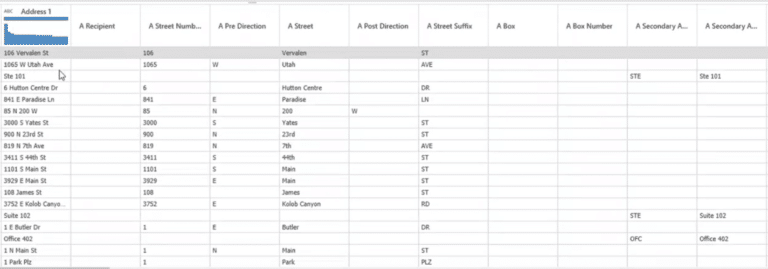
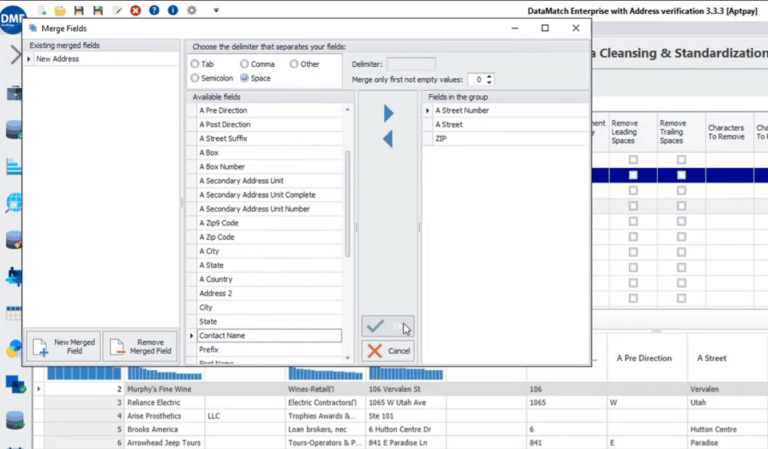
You can then choose the relevant fields to use for your new custom address field using the ‘Merge Fields’ option. For example, you can choose A Street Number, A Street, and ZIP Code and create a new address field.
Matching and Deduplication
After standardizing the fields according to a set format, we can map each field more accurately to achieve a higher matching score and minimize false positives and negatives. Taking the above-mentioned example of name fields in Figure 4, we can decide to match first names with first names and last names with last names across the two data sources using fuzzy matching as follows:

The matches are then combined into separate group IDs and the resulting match scores can be used to identify duplicate and golden records.

Conclusion
For name and address fields to exist in varying formats across databases, Excel files, enterprise applications, etc. is inevitable. Organizations like banks, healthcare providers and other institutions can’t afford to overlook the minutest discrepancy in formats to negatively impact their matching and deduplication accuracy.
To overcome this challenge, DataMatch Enterprise’s name and address field transformations enables enterprises to ensure like-with-like mappings and easily detect redundant or duplicate entries to maximize their data integrity.
For more information on DataMatch Enterprise’s data scrubbing solutions, click here.

How best in class fuzzy matching solutions work: Combining established and proprietary algorithms
Start your free trial today

