







Vorverarbeitung
Sicherstellung einer zuverlässigen Datenqualität durch Datenbereinigung und Standardisierung, z. B. durch Korrektur ungültiger, falsch geschriebener oder ungültiger Daten sowie durch Überprüfung der Datengenauigkeit und -relevanz.

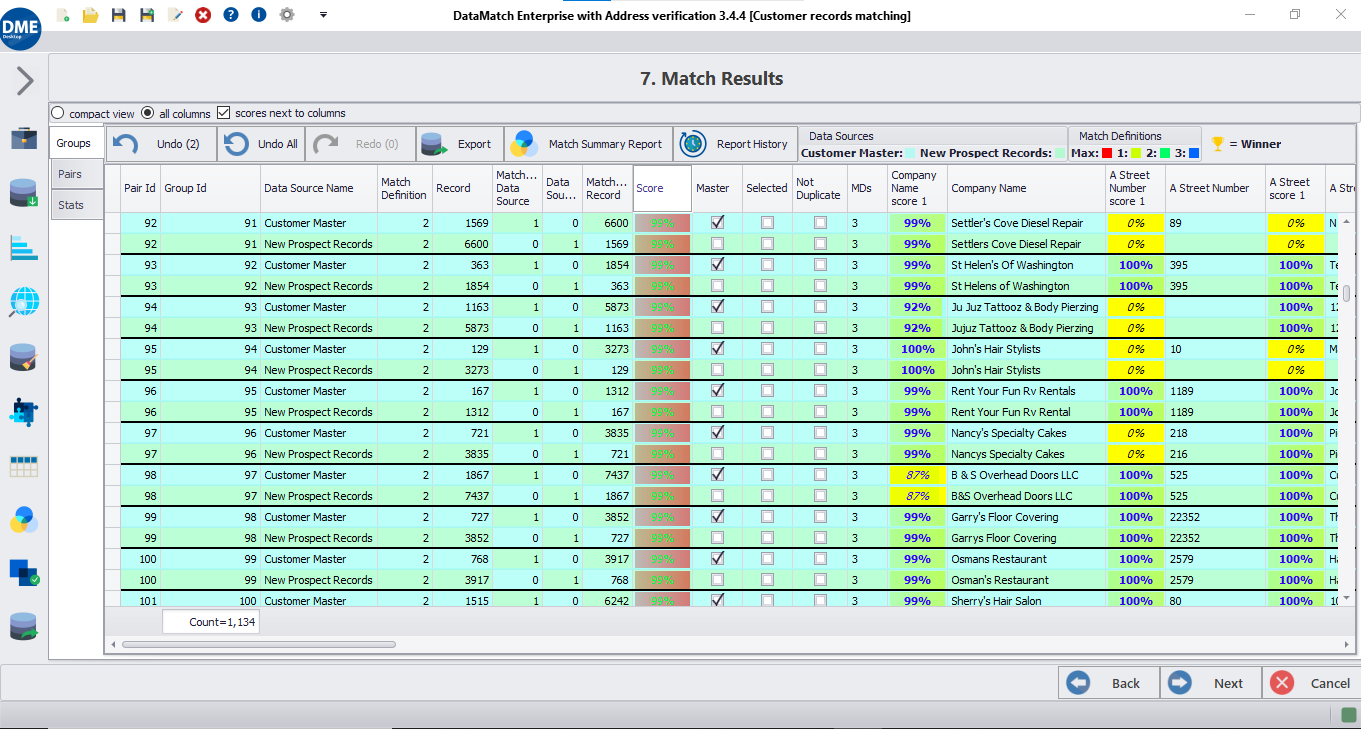
Feldvergleiche
Wählen Sie eine Kombination von Feldern aus und berechnen Sie die Wahrscheinlichkeit, dass ihre Werte ähnlich sind, indem Sie entsprechende Feldübereinstimmungsalgorithmen für unscharfe, numerische, phonetische oder domänenspezifische Vergleiche implementieren.


Indizierung/Blockierung
Implementieren Sie Blockierungs- oder Indizierungstechniken, die die Anzahl der Vergleiche zwischen Datensätzen begrenzen und sie nur dann vergleichen, wenn sie mit hoher Wahrscheinlichkeit zur gleichen Entität gehören.

Klassifizierung und Bewertung
Klassifizierung von Datensätzen als erfolgreiche Übereinstimmung oder Nicht-Übereinstimmung auf der Grundlage der für die Feldähnlichkeit berechneten Übereinstimmungswerte und Auswertung der Ergebnisse mit verschiedenen Stufen und Gewichtungen, um eine maximale Genauigkeit der Datensatzverknüpfung zu erreichen.