






Verschlucken
Zusammenführung von Daten an einem Ort, da sie über verschiedene Quellen verstreut sind, und Lösung von widersprüchlichen Änderungen in Datenbankschemata, um eine weitere Verarbeitung zu ermöglichen.

Standardisierung von Daten
Behebung von Datenstandardisierungsproblemen, die im vorherigen Schritt hervorgehoben wurden, einschließlich des Auffüllens leerer Daten, des Ersetzens ungenauer oder ungültiger Informationen, der Standardisierung von Werten anhand definierter Muster und Formate usw.


Entdeckung von Daten
Erkennung und Hervorhebung von statistischen Anomalien, die in Form von fehlenden, unvollständigen oder ungültigen Datenwerten vorhanden sein können.

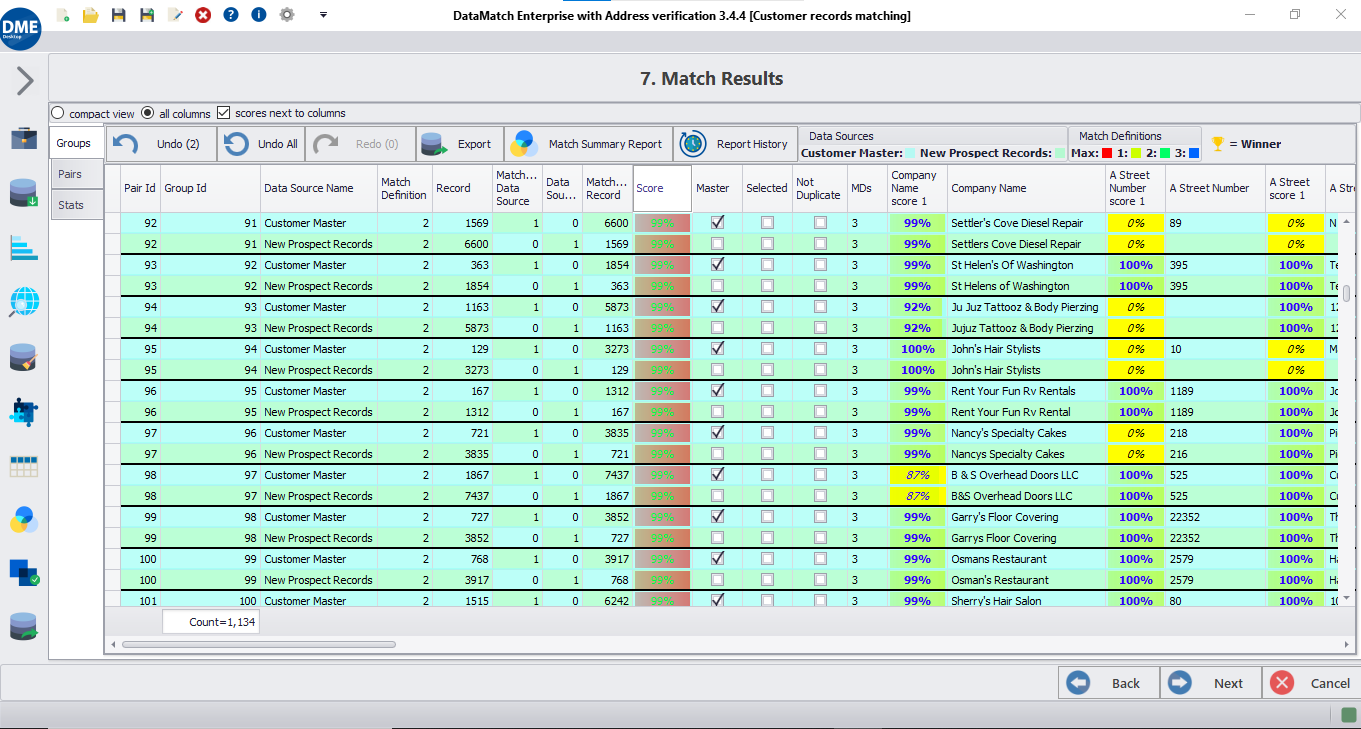
Verknüpfung von Entitätsdatensätzen
Abgleich von Datensätzen innerhalb und zwischen Datenbanken und Identifizierung potenzieller Datensätze, die sich auf dieselbe Person beziehen. In der Regel fehlt es den Datensätzen an standardisierten, eindeutig identifizierenden Attributen, so dass eine Kombination intelligenter Fuzzy-Matching-Algorithmen erforderlich sein kann, um die Genauigkeit zu erhöhen.