





























Last Updated on April 14, 2022
Im Zuge der industriellen Datenrevolution erkennen Unternehmen, dass herkömmliche Datenmanagement-Tools für die Bewältigung der Komplexität moderner Daten unzureichend sind. Viele mussten ein böses Erwachen erleben, als Migrations- oder Transformationsinitiativen aufgrund schlechter Daten, fehlender Datenqualitätsmanagementsysteme und des Rückgriffs auf veraltete, nicht mehr wirksame Methoden scheiterten.
Bei Data Ladder betrachten wir Datenqualität als einen notwendigen, fortlaufenden Prozess, der innerhalb und zwischen Systemen und Abteilungen integriert werden muss. Letztere sind die wahren Eigentümer der Kundendaten und müssen daher mit Systemen ausgestattet werden, die es ihnen ermöglichen, Daten zu profilieren und zu bereinigen, ohne sich bei der Datenaufbereitung auf die IT zu verlassen.
Data Profiling und Data Cleansing sind die beiden grundlegenden Funktionen oder Komponenten der Data Ladder-Lösung für das Datenqualitätsmanagement und der Ausgangspunkt jeder Datenmanagementinitiative. Einfach ausgedrückt: Um Ihre Daten zu reparieren, müssen Sie wissen, was mit ihnen los ist.
In diesem Beitrag erfahren Sie alles, was Sie über den Unterschied zwischen Datenprofilierung und Datenbereinigung wissen müssen.
Schauen wir genauer hin.
Data Profiling vs. Data Cleansing – Was ist der Hauptunterschied?
In einem Datenqualitätssystem ist die Datenprofilierung eine leistungsstarke Methode zur Analyse von Millionen von Datenzeilen, um Fehler, fehlende Informationen und Anomalien zu erkennen, die die Qualität der Informationen beeinträchtigen könnten. Durch die Erstellung von Datenprofilen können Sie alle zugrundeliegenden Probleme mit Ihren Daten erkennen, die Sie sonst nicht sehen könnten.
Die Datenbereinigung ist der zweite Schritt nach der Profilerstellung. Sobald Sie die Schwachstellen in Ihren Daten erkannt haben, können Sie die notwendigen Schritte zur Beseitigung der Schwachstellen unternehmen. In der Phase der Profilerstellung stellen Sie beispielsweise fest, dass in mehr als 100 Ihrer Datensätze Telefonnummern mit fehlenden Ländercodes enthalten sind. Sie können dann eine Regel in Ihre DQM-Plattform schreiben, um die Ländervorwahlen in alle Telefonnummern einzufügen, bei denen sie fehlen.
Der Hauptunterschied zwischen den beiden Verfahren ist ganz einfach: Bei dem einen wird auf Fehler geprüft, bei dem anderen können Sie Fehler bereinigen.
Datenprofilierung und Datenbereinigung sind keine neuen Konzepte. Sie beschränken sich jedoch weitgehend auf manuelle Prozesse in Datenverwaltungssystemen. So wurde die Erstellung von Datenprofilen schon immer von IT- und Datenexperten mit einer Kombination aus Formeln und Codes durchgeführt, um grundlegende Fehler zu ermitteln. Allein die Profilerstellung würde Wochen dauern, und selbst dann würden kritische Fehler übersehen werden. Die Datenbereinigung war ein weiterer Alptraum. Es kann Monate dauern, eine Datenbank zu bereinigen, einschließlich der Beseitigung von Duplikaten (mit einer sehr niedrigen Genauigkeitsrate). Während diese Methoden bei einfachen Datenstrukturen funktioniert haben, ist es nahezu unmöglich, die gleichen Methoden auf moderne Datenformate anzuwenden.
Hier ein Beispiel für die Erstellung von Datenprofilen mit Microsoft Visual Studio. IT-Manager müssten diesen Arbeitsablauf manuell einrichten.nur um Fehler in einer Datenquelle zu identifizieren.
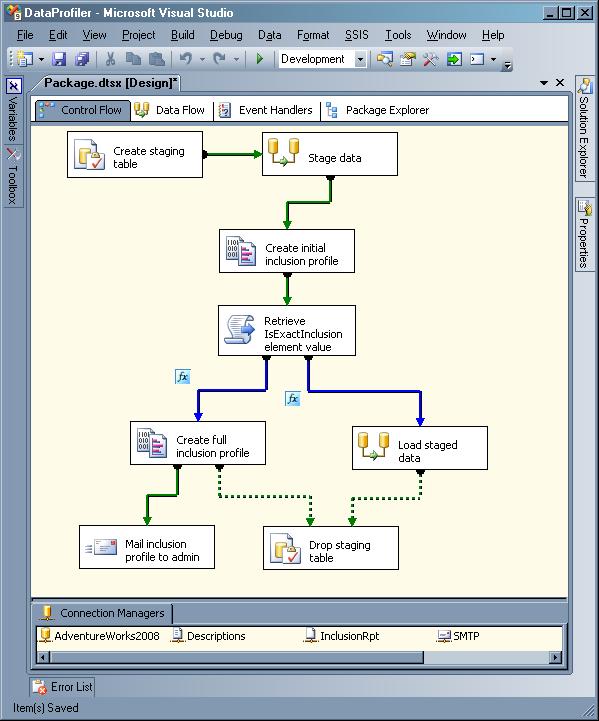
Stellen Sie sich vor, Sie könnten diesen Workflow für komplexe, inkonsistente Daten von Dritten, wie z. B. aus den sozialen Medien, verwenden! Stellen Sie sich vor, Sie haben mehrere Datenquellen, die von verschiedenen Anwendungen, Plattformen (online und offline), Anbietern, Lieferanten usw. kommen. Stellen Sie sich vor, Sie könnten diesen Arbeitsablauf für jede Art von Datenquelle neu erstellen. Dies ist nicht nur zeitaufwendig, sondern auch ineffizient bei der Verarbeitung großer Datenmengen.
Nehmen wir an, der Name wurde bei der Dateneingabe falsch eingegeben und wird im CRM als Johnnathan Smith buchstabiert. Wenn das Team, das diese Daten bearbeitet, keine Profilprüfung durchführt, würde es nicht wissen, dass es sich um einen Fehler handelt, und dem Kunden eine E-Mail mit der falschen Schreibweise schicken. Ich überlasse es Ihnen, sich vorzustellen, welche Folgen das haben könnte.
Die Erstellung von Datenprofilen hilft dem Unternehmen daher, diesen Rechtschreibfehler gleich zu Beginn des Prozesses zu erkennen. Die Datenbereinigung ermöglicht es dem Benutzer dann, diesen Fehler zu korrigieren, indem er ihn durch den richtigen Namen ersetzt.
Wie die Datenprofilierung traditionell durchgeführt wurde und warum es wichtig ist, sich der Automatisierung zuzuwenden
Die Erstellung von Datenprofilen ist ein entscheidender Bestandteil von Data-Warehouse- und Business-Intelligence-Projekten, bei denen Datenqualitätsprobleme in Datenquellen ermittelt werden. Darüber hinaus ermöglicht das Data Profiling den Nutzern, neue Anforderungen an ein Zielsystem zu entdecken. Doch bis vor kurzem war die Erstellung von Datenprofilen ein mühsamer Prozess, der manuelle Aufgaben wie:
- Erstellung von Datenvalidierungsregeln und Formeln zur Behebung häufiger Datenfehler
- Berechnung von Statistiken wie Minimum, Maximum, Anzahl und Summe
- Spaltenübergreifende Analyse zur Ermittlung von Abhängigkeiten
- Identifizierung von Inkonsistenzen im Format
Je nach Datenmenge und Art der Probleme kann dieser Schritt Tage in Anspruch nehmen. Sobald die Entdeckungen gemacht sind, werden neue Regeln in die Liste der Regeln aufgenommen, die dann in einer Bereinigungsphase durchgesetzt werden. Hat man beispielsweise herausgefunden, dass das häufigste Muster für ein Datum (JJJJ/MM/TT) ist, wird dieses Muster in eine Regel umgewandelt (durch Kodierung), damit alle Zahlen entsprechend formatiert werden. Diese Regel muss später möglicherweise umgekehrt werden, wenn ein anderer Datensatz (z. B. das Format eines neuen CRM) Datumsangaben in (TT/MM/JJJJ) erfordert.
In ihrer herkömmlichen Form ist Data Profiling nicht trivial – es ist rechenaufwändig, Datenprobleme zu entdecken, es ist praktisch unmöglich, alle Einschränkungen zu bestimmen, die sich auf Spalten auswirken, und schließlich wird sie oft an einer großen Menge von Datensätzen durchgeführt, die nicht in den Hauptspeicher passen, wodurch die Fähigkeit, exponentielle Datenmengen zu verarbeiten, eingeschränkt wird.
Zur Bewältigung dieser Herausforderungen wurden verschiedene Tools und Algorithmen eingeführt, wie z. B. die Verwendung von SQL-Abfragen zur Erstellung von Datenprofilen im DBMS. Diese Tools haben den Prozess zwar erheblich verbessert, doch fehlt es ihnen noch an interaktiver Profilerstellung und an der Handhabung der Komplexität von Big Data. Hier kommt der Bedarf an automatisierten Self-Service-Tools ins Spiel.
Ein automatisiertes Self-Service-Tool zur Erstellung von Datenprofilen wie DataMatch Enterprise von Data Ladder führt komplexe Berechnungsprozesse unter Verwendung von Technologien des maschinellen Lernens und Fuzzy-Matching-Algorithmen durch. Mit einer benutzerfreundlichen Point-and-Click-Oberfläche können Geschäftsanwender ihre Datenquelle einfach anschließen und die Software die gesamte rechnerische Analyse auf der Grundlage integrierter Geschäftsregeln durchführen lassen (die anhand historischer Erkenntnisse über die häufigsten Fehlerarten in einer Datenquelle erstellt wurden).
Anwendungsfall 1
– Profiling für fehlende Werte

Die automatisierte Erstellung von Datenprofilen hilft Ihnen, das Problem schneller zu lösen. Wenn die Profilerstellung z. B. ergibt, dass Nachnamen oder Telefonnummern in der Datenbank fehlen, können Sie die Ursache für dieses Problem leicht ermitteln. Ist die Eingabe von Telefonnummern mit Ländervorwahl in Ihrem Webformular obligatorisch? Verfügen Sie über Dateneingabeprotokolle und -standards? Die Automatisierung ermöglicht es Ihnen, sich auf das Wesentliche zu konzentrieren – die Lösung der Problemursache, anstatt Zeit mit der Fixierung auf das Problem zu verschwenden.
Argumente für die automatisierte Datenbereinigung
Wie bereinigt man solche Datenmisere?
In einer herkömmlichen ETL- oder Excel-Umgebung würde die Bereinigung dieser Menge an verschmutzten Daten Tage dauern. Man müsste Skripte ausführen, die Daten aufschlüsseln, sie verschieben, Datencluster bearbeiten und ein Problem nach dem anderen angehen, bevor man sie in ein standardisiertes Format umwandeln kann.
Wenn Sie nun eine automatisierte Datenbereinigungslösung verwenden, können Sie diese Daten durch einfaches
durch Anklicken von Kontrollkästchen.
- Textstil normalisieren.
- Unerwünschte Zeichen entfernen
- Beseitigung versehentlicher Tippfehler bei der Dateneingabe (diese sind schwer zu erkennen!)
- Leerzeichen zwischen Buchstaben/Wörtern bereinigen
- Spitznamen in richtige Namen umwandeln (John statt Johnny)
Versuchen Sie, dasselbe mit Excel zu tun, und Sie würden Stunden brauchen, um die Buchstaben zu normalisieren.
Business Intelligence-Mitarbeiter verbringen zwischen50 – 90% ihrer Zeit für die Aufbereitung der Daten für die Analyse! Nicht, dass das Bereinigen oder Aufbereiten von Daten nicht zu ihren Aufgaben gehören würde, aber wenn sie sich damit aufhalten, was durch Automatisierung erreicht werden könnte, ist das eine Verschwendung ihrer Zeit. Datenwissenschaftler und Business-Intelligence-Mitarbeiter brauchen Unterstützung bei der Auswertung von Daten, und zwar in Form einer leistungsstarken automatisierten Lösung.
Anwendungsfall 2 – Datenprofilierung und Datenbereinigung in Aktion

P.S.: Holen Sie sich unser kostenloses CHEAT SHEET zur Erstellung von Datenprofilen und bewerten Sie Ihre Daten auf grundlegende Unstimmigkeiten.
Fallstudie – Lamb Financial
Die Lamb Financial Group ist einer der am schnellsten wachsenden Versicherungsmakler des Landes und bietet landesweit Finanzdienstleistungen ausschließlich für gemeinnützige Organisationen und soziale Einrichtungen an. Die in New York ansässige Organisation arbeitet mit Versicherern zusammen, die sich auf gemeinnützige Organisationen und Wohltätigkeitsorganisationen spezialisiert haben und Arbeiterunfall-, Unfall-, Berufshaftpflicht-, Sach-, Auto-, Direktoren- und Vorstandsmitglieder-, Gruppenkranken- und Invaliditätsversicherungen anbieten.
Angesichts der vielen verschiedenen Datenquellen, die es zu verwalten galt, und der Tatsache, dass die Genauigkeit das wichtigste Element des Unternehmens war, verbrachten die Ressourcen des Unternehmens Tage mit der Datenbereinigung und -standardisierung. Da immer mehr und immer komplexere Daten in das Unternehmen strömten, konnte es sich nicht mehr leisten, diese manuell zu bereinigen und zu standardisieren.
DataMatch Enterprise™ bot eine einfachere Lösung zur Datenbereinigung für das Unternehmen. Sie waren in der Lage, unsere Wordsmith™-Funktion, ein Standardisierungstool zur Erstellung benutzerdefinierter Bibliothekseinstellungen, schnell zu nutzen. So konnten sie die Daten bereinigen und die bestmögliche Übereinstimmung finden. Die Software ist inzwischen ein wichtiger Bestandteil des Prozesses, wenn neue Daten in das CRM-System importiert werden.
Möchten Sie das Produkt kennenlernen? Buchen Sie eine Demo bei uns und lassen Sie sich von unseren Experten helfen, saubere Daten zu erhalten!



