





























Last Updated on mars 29, 2022
Alors que nous traversons la révolution industrielle des données, les entreprises commencent à se rendre compte de l’inadéquation des outils traditionnels de gestion des données pour gérer la complexité des données modernes. Nombreux sont ceux qui ont dû faire l’expérience de l’échec d’initiatives de migration ou de transformation dues à des données de mauvaise qualité, à l’absence de systèmes de gestion de la qualité des données et au recours à des méthodes dépassées qui ne sont plus efficaces.
Chez Data Ladder, nous considérons la qualité des données comme un processus nécessaire et continu qui doit être intégré dans et entre les systèmes et les départements. En outre, le contrôle des données doit être équilibré entre l’informatique et les utilisateurs professionnels, car ces derniers sont les véritables propriétaires des données clients et doivent donc être équipés de systèmes leur permettant de profiler et de nettoyer les données sans dépendre de l’informatique pour leur préparation.
Leprofilage et le nettoyage desdonnées sont les deux fonctions ou composants fondamentaux de la solution de gestion de la qualité des données de Data Ladder et le point de départ de toute initiative de gestion des données. En d’autres termes, pour réparer vos données, vous devez savoir ce qui ne va pas.
Cet article couvre tout ce que vous devez savoir sur la différence entre le profilage et le nettoyage des données.
Allons-y.
Profilage des données ou nettoyage des données – Quelle est la principale différence ?
Dans un système de qualité des données, le profilage des données est un moyen puissant d’analyser des millions de lignes de données pour identifier les erreurs, les informations manquantes et toutes les anomalies susceptibles d’affecter la qualité des informations. En profilant les données, vous pouvez voir tous les problèmes sous-jacents de vos données que vous ne pourriez pas voir autrement.
Le nettoyage des données est la deuxième étape après le profilage. Une fois que vous avez identifié les failles dans vos données, vous pouvez prendre les mesures nécessaires pour les nettoyer. Par exemple, lors de la phase de profilage, vous découvrez que plus de 100 de vos enregistrements ont des numéros de téléphone auxquels il manque l’indicatif du pays. Vous pouvez alors écrire une règle dans votre plateforme DQM pour insérer les codes pays dans tous les numéros de téléphone qui en sont dépourvus.
La différence essentielle entre les deux processus est simple : l’un vérifie les erreurs et l’autre vous permet de les corriger.
Le profilage et le nettoyage des données ne sont pas des concepts nouveaux. Cependant, ils ont été largement limités à des processus manuels au sein des systèmes de gestion des données. Par exemple, le profilage des données a toujours été effectué par des experts en informatique et en données qui utilisent une combinaison de formules et de codes pour identifier les erreurs de base. Le simple processus de profilage prendrait des semaines et même alors, des erreurs critiques seraient manquées. Le nettoyage des données était un autre cauchemar. Le nettoyage d’une base de données, y compris la suppression des doublons (avec un taux de précision très faible), peut prendre des mois. Si ces méthodes ont pu fonctionner pour des structures de données simples, il est pratiquement impossible d’appliquer les mêmes méthodes aux formats de données modernes.
Voici un exemple de profilage de données à l’aide de Microsoft Visual Studio. Les responsables informatiques devraient configurer manuellement ce flux de travail.ow juste pour identifier les erreurs dans une source de données.
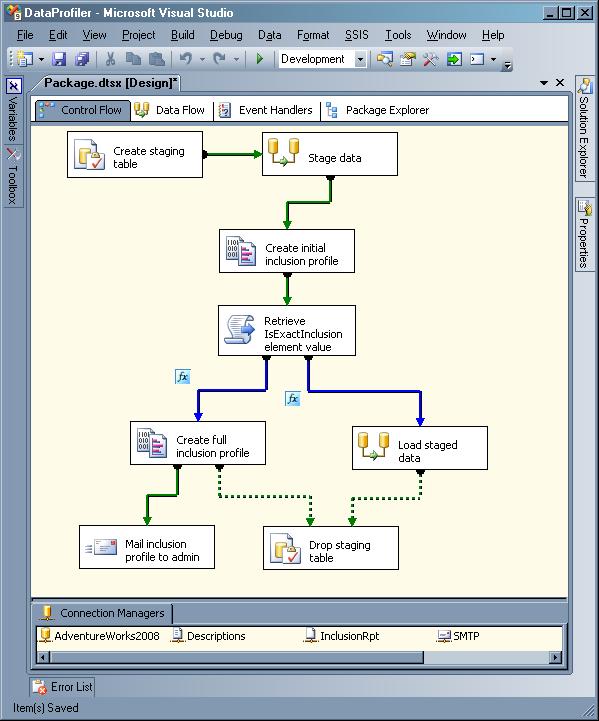
Imaginez l’utilisation de ce flux de travail pour des données tierces complexes et incohérentes telles que celles des médias sociaux ! Imaginez que vous ayez de multiples sources de données provenant de plusieurs applications, plateformes (en ligne et hors ligne), vendeurs, fournisseurs, etc. Imaginez recréer ce flux de travail pour chaque type différent de source de données. Non seulement cela prend du temps, mais c’est inefficace pour traiter de grandes quantités de données.
En reprenant le même exemple, supposons que le nom a été mal saisi lors de l’entrée des données et qu’il est orthographié comme Johnnathan Smith dans le CRM. Si l’équipe qui traite ces données ne procède pas à une vérification du profil, elle ne saura pas qu’il s’agit d’une erreur et enverra au client un courrier électronique contenant la mauvaise orthographe. Je vous laisse imaginer les conséquences de cette situation.
Le profilage des données aide donc l’entreprise à identifier cette erreur d’orthographe dès le début du processus. Le nettoyage des données permet ensuite à l’utilisateur de corriger cette erreur en la remplaçant par le bon nom.
Comment le profilage des données était traditionnellement effectué et pourquoi il est important de se tourner vers l’automatisation
Le profilage des données est une partie cruciale des projets d’entrepôt de données et de business intelligence, où les problèmes de qualité des sources de données sont identifiés. En outre, le profilage des données permet aux utilisateurs de découvrir de nouvelles exigences pour un système cible. Mais jusqu’à récemment, le profilage des données était un processus épuisant qui impliquait des tâches manuelles comme.. :
- Création de règles et de formules de validation des données pour résoudre les problèmes courants d’erreurs de données.
- Calculer des statistiques comme le minimum, le maximum, le nombre et la somme.
- Analyse inter-colonnes pour identifier les dépendances
- Identifier les incohérences dans le format
Selon le volume de données et la nature des problèmes, cette étape peut prendre plusieurs jours. Une fois les découvertes faites, de nouvelles règles sont ajoutées à la liste des règles qui sont ensuite appliquées dans une phase de nettoyage. Par exemple, après avoir découvert que le modèle le plus fréquent pour une date est (AAAA/MM/JJ), ce modèle est transformé en une règle (réalisée par codage) pour que tous les nombres soient formatés en conséquence. Cette règle devra peut-être être inversée plus tard si un autre ensemble de données (comme le format d’un nouveau CRM) exige que les dates soient (DD/MM/YYYY).
Dans son cadre traditionnel, le profilage des données n’est pas trivial – il est complexe sur le plan informatique de découvrir les problèmes liés aux données, il est pratiquement impossible de déterminer toutes les contraintes qui affectent les colonnes et, enfin, il est souvent effectué sur un grand volume d’ensembles de données qui peuvent ne pas tenir dans la mémoire principale, ce qui limite la capacité de traiter un nombre exponentiel de données.
Divers outils et algorithmes ont été introduits pour relever ces défis, comme l’utilisation de requêtes SQL pour profiler les données dans le SGBD. Si ces outils ont considérablement amélioré le processus, ils présentent encore des lacunes en matière de profilage interactif et de gestion de la complexité des données volumineuses. C’est là qu’intervient le besoin d’outils de libre-service automatisés.
Un outil automatisé de profilage de données en libre-service comme DataMatch Enterprise de Data Ladder effectue des processus de calcul complexes en utilisant des technologies d’apprentissage automatique et des algorithmes de correspondance flous. Grâce à une interface conviviale de type « pointer-cliquer », les utilisateurs professionnels peuvent facilement brancher leur source de données et laisser le logiciel effectuer toute l’analyse informatique sur la base de règles commerciales intégrées (créées à partir de l’apprentissage historique des types d’erreurs les plus courantes dans une source de données).
Cas d’utilisation 1
– Profilage pour les valeurs manquantes

Le profilage automatisé des données vous permet d’atteindre le problème plus rapidement. Par exemple, si le profilage révèle que vous avez des noms de famille ou des numéros de téléphone manquants dans la base de données, vous pouvez facilement identifier la cause de ce problème. Votre formulaire Web rend-il obligatoire la saisie des numéros de téléphone avec les codes de pays ? Avez-vous mis en place des protocoles et des normes de saisie des données ? L’automatisation vous permet de vous concentrer sur ce qui compte le plus – résoudre la cause profonde du problème plutôt que de perdre du temps à se focaliser sur le problème.
Argumenter en faveur du nettoyage automatisé des données
Comment nettoie-t-on des données désordonnées comme celles-ci ?
Dans un environnement ETL ou Excel traditionnel, le nettoyage de ce niveau de données sales vous prendrait des jours. Il faut exécuter des scripts, décomposer les données, les déplacer, gérer des groupes de données, s’attaquer à un problème à la fois avant de pouvoir les transformer en un format standardisé.
Maintenant, si vous utilisez une solution de nettoyage de données automatisée, vous serez en mesure de transformer ces données simplement en
cliquant sur les cases à cocher.
- Normaliser le style du texte.
- Supprimer les caractères indésirables
- Supprimez les fautes de frappe accidentelles lors de la saisie des données (elles sont difficiles à repérer !).
- Nettoyer les espaces entre les lettres/mots
- Transformer les surnoms en noms réels (John au lieu de Johnny)
Essayez de faire la même chose avec Excel et il vous faudra des heures rien que pour normaliser les lettres.
Les travailleurs de l’intelligence économique passent entre
50 – 90%
de leur temps à préparer les données pour l’analyse ! Non pas que le nettoyage ou la préparation des données ne fasse pas partie de leur travail, mais s’ils se laissent submerger par ce qui pourrait être réalisé par l’automatisation, c’est une perte de temps. Les spécialistes des données et les travailleurs de l’informatique décisionnelle ont besoin d’aide pour donner un sens aux données, et cette aide se présente sous la forme d’une solution automatisée puissante.
Cas d’utilisation 2 – Profilage et nettoyage des données en action

P.S. : Téléchargez notre CHEAT SHEET gratuite sur le profilage des données et évaluez vos données pour détecter les incohérences de base.
Étude de cas – Lamb Financial
Lamb Financial Group est l’un des courtiers d’assurance dont la croissance est la plus rapide du pays. Il fournit des services financiers exclusivement à des organismes à but non lucratif et à des organisations de services sociaux dans tout le pays. Basée à New York, l’organisation travaille avec des assureurs spécialisés dans les organismes à but non lucratif et les organisations caritatives et propose des assurances contre les accidents du travail, les risques divers, la responsabilité professionnelle, les biens, l’automobile, les administrateurs et les dirigeants, la santé collective et l’invalidité.
Avec autant de sources de données différentes à gérer, et l’exactitude étant l’élément le plus critique de leur activité, les ressources de l’entreprise passaient des jours entiers à nettoyer et normaliser les données. L’entreprise ne pouvait plus se permettre de nettoyer et de normaliser manuellement les données qui affluaient et devenaient de plus en plus complexes.
DataMatch Enterprise™ a fourni une solution de nettoyage des données plus facile pour l’organisation. Ils ont pu utiliser rapidement notre fonction Wordsmith™, qui est un outil de normalisation permettant de créer des paramètres de bibliothèques personnalisés. Cela leur a permis de nettoyer les données et de trouver la meilleure correspondance possible. Le logiciel est maintenant devenu un élément important de leur processus d’importation de nouvelles données dans leur CRM.
Vous voulez une démonstration du produit ? Réservez une démonstration avec nous et laissez nos experts vous aider à obtenir des données propres !



