































Last Updated on December 10, 2025
Data errors today can easily cascade into millions in losses and poor data quality can cost businesses up to 31% of their revenue. As the complexity of data continues to increases, companies are beginning to realize that traditional methods for managing data are no longer sufficient to catch the issues that can derail everything from customer interactions to critical decision-making.
Many have had to experience rude wake-up calls with failed migration or transformation initiatives caused by poor data, the absence of efficient data quality management systems, and reliance on outdated methods.
To thrive, businesses must shift to modern data quality management practices. Data profiling and data cleansing are at the heart of them. Therefore, for organizations that want to reduce costly mistakes and ensure data quality, understanding these two processes and the difference between them is essential.
At Data Ladder, we see data quality as a necessary, on-going process that must be integrated within and across systems and departments. Moreover, we believe that the control over data should be balanced out between IT and business users, for the latter is the true owner of customer data and therefore must be equipped with systems that can enable them to profile and clean data without relying on IT for data preparation.
Data profiling and data cleansing are the two fundamental functions or components of Data Ladder’s data quality management solution and the starting point of any data management initiative.
Data Profiling vs. Data Cleansing – What’s the Key Difference?
In a data quality system, data profiling is a powerful tool for analyzing millions of rows of data to uncover errors, missing information, and any anomalies that could affect the quality of information. By profiling data, you get to identify all the underlying problems with your data that you would otherwise not be able to notice.
Data cleansing is the second step after profiling. Once you’ve identified the flaws in your data, you can take the steps necessary to clean or fix those flaws. Data cleaning helps you do just that.
Let’s say, during the profiling phase, you discover that more than 100 of your records have phone numbers that are missing country codes. You can then write a rule within your data quality management (DQM) platform to automatically insert country codes in all phone numbers missing them.
The key difference between the two processes is simple – one checks for errors and the other lets you clean them up.
Data profiling reveals hidden problems in existing data, such as incorrect data patterns, missing data, and duplicate data, while data cleansing fixes these problems. Together, these two processes help ensure data accuracy and create cleaner, more reliable, and actionable datasets that resolve several data quality issues and support operational efficiency, strategic decision-making, and business growth.
Why Traditional Methods Fall Short
While both data profiling and data cleansing are old concepts, they have largely been limited to manual processes within data management systems. Traditionally, data profiling has always been done by IT and data experts using a combination of formulas and codes to identify basic-level errors. However, this way, the mere profiling process could take weeks to complete and even then, some critical errors would be missed.
Data cleansing was another nightmare. It could take months to clean up a database – remove duplicates and correct data. Even then, with a very low accuracy rate.
While these methods may have worked for simple data structures, it’s next to impossible to apply the same methods on modern data formats.
Example:
Here’s an example of data profiling using Microsoft Visual Studio. IT managers had to manually configure this workflow just to identify errors in a data source.
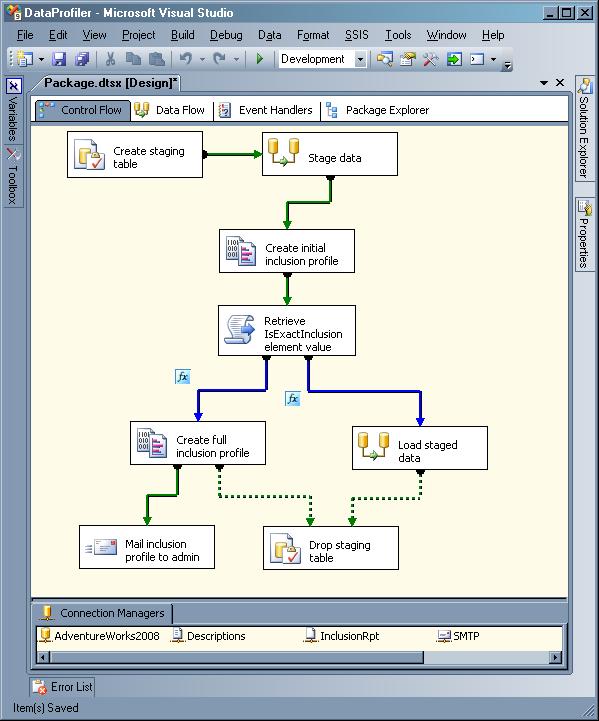
Now imagine using this data governance workflow for complex, inconsistent, third-party data such as that of social media!
Imagine having multiple data sources streaming in from multiple apps, platforms (online and offline), vendors, suppliers etc.
Imagine recreating this workflow for every different type of data source.
Not only would this be time-consuming but also ineffective at handling large amounts of data.
Using the same example, let’s assume the name of a customer is incorrectly entered at the data entry stage and is spelled as Johnnathan Smith in the CRM. If the team handling this data doesn’t run a profile check, they wouldn’t know it’s an error and would proceed to send out an email to the customer with the wrong spelling. I leave you to imagine the consequences of that.
Data profiling helps businesses catch errors like this at the beginning of the process. Data cleansing then lets the users correct those errors to ensure their records are accurate and trustworthy.
Let Go of Traditional Methods
Traditional data profiling and cleansing methods might be useful once, but they no longer cut it. So, it’s time to let go of them and adopt the advanced data preparation methods that can do the job in minutes.
Why You Must Automate Data Profiling?
Data profiling is a crucial part of data warehouse and business intelligence projects to identify data quality issues in data sources. Furthermore, data profiling allows users to uncover new requirements for a target system. But until recently, data profiling has been an exhausting process that involves manual tasks as:
- Creating rules and formulas to tackle common data errors while validating data.
- Calculating statistics such as minimum, maximum, count, and sum.
- Conducting cross-column analysis to identify dependencies.
- Identifying inconsistencies in data formats.
Depending on the volume of data and the nature of problems, this step could take days to complete. Once discoveries were made, new rules had to be created (each requiring coding and further adjustments), which were then enforced in a cleansing phase.
For example, after discovering that the most common date format is YYYY/MM/DD, you’d create a rule to standardize all dates accordingly.
But if another data set, such as a new CRM, uses DD/MM/YYYY format, this rule would need to be reversed.
In its traditional setting, data profiling is non-trivial. It’s computationally complex to discover data issues, it’s virtually impossible to determine all the constraints that affect columns and lastly, it’s often performed on a large volume of data sets that may not fit into main memory, thus limiting the ability to process exponential numbers of data.
Various tools and algorithms have been introduced to tackle these challenges, such as the use of SQL queries to profile data in the DBMS. While these data profiling tools have improved the process considerably, they are still lacking in interactive profiling and handling the complexities of big data. This is where the need for automated self-service tools step in.
An automated self-service data profiling tool like Data Ladder’s DataMatch Enterprise can perform complex computational processes using machine-learning technologies and fuzzy matching algorithms. With an easy-to-use point-and-click interface, business users can easily plug in their data source and let the software do all the computational analysis based on built-in business rules (created via historical learnings of the most common types of errors in a data source).
Use Case 1 – Profiling for Missing Values

Automated data profiling helps you get to the problem faster. For instance, if the profiling reveals you’ve got missing last names or phone numbers in the database, you can easily identify the cause of that problem.
Does your webform make it mandatory to enter phone numbers with country codes? Do you have data entry protocols and standards in place?
Automation allows you to focus on what matters most – solving the root cause of the problem rather than wasting time fixated on the problem or manually identifying the source.
Making the Case for Automated Data Cleansing
Dirty data can cost organizations time, money, and valuable insights. Let’s consider an example to understand why automating data cleansing is vital for maintaining data quality.
Take a look at the image below. How do you clean messed up data like this?

In a traditional ETL or Excel-based data management repository, cleaning this level of dirty data could take days. You’d have to run scripts, break down the data, move it around, handle clusters of data, tackling one problem at a time before you can transform this into a standardized format.
Now, if you use an automated data cleansing solution, you’d be able to transform this data by simply clicking on checkboxes.
With automation, you can efficiently manage tasks like:
- Normalizing text style
- Removing unwanted characters
- Correcting accidental typos during data entry (these are hard to catch!)
- Cleaning up spaces between letters/words
- Transforming nicknames into actual names (e.g., John instead of Johnny)
Try doing the same using Excel and it’d take you hours just to normalize letters.
Business intelligence workers spend between 50 – 90% of their time prepping data for analysis! While cleaning or preparing data are essential aspects of their job, it’s a waste of time to be bogged down by what could be achieved in a significantly shorter span of time via automation.
To maximize efficiency and ensure data integrity, organizations must adopt automated data cleansing solutions that empower data scientists and business intelligence teams to focus on what matters most, i.e., extracting valuable insights from clean, reliable data.
Use Case 2 – Data Profiling and Data Cleansing in Action

P.S: Grab our free data profiling CHEAT SHEET and evaluate your data for basic inconsistencies.
Case Study – Lamb Financial
Lamb Financial Group is one of the fastest-growing insurance brokers in the country, providing financial services exclusively to non-profits and social service organizations nationwide. Based in New York, the organization works with carriers who specialize in non-profits and charities, providing a range of insurance products, including Worker’s Compensation, Casualty, Professional Liability, Property, Auto, Directors and Officers, Group Health, and Disability Insurance.
With so many different data sources to manage, and accuracy being the most critical element of their business, the company’s resources were spending days on data cleansing and standardization. As their business expanded and data grew in complexity, the company could no longer afford to clean and standardize manually.
DataMatch Enterprise™ provided an easier data cleansing solution for the organization. They utilized our innovative Wordsmith™ function, which is a standardization tool that enables users to create custom libraries for data inputs. This allowed them to cleanse their data quickly and find the best possible matches. The software has now become an integral part of their process when importing new data into their CRM.
Want a walkthrough of the product? Book a demo with us and let our experts help you get clean data!

