





























Last Updated on April 19, 2022
Datenaufbereitungstools gibt es nun schon seit geraumer Zeit. Die meisten dieser Tools setzen jedoch voraus, dass die Benutzer über Kenntnisse in Programmiersprachen und relationalen Datenbanken verfügen, um sie zu bedienen. Die Datenbereinigung, -umwandlung und -aufbereitung wird in der Regel von IT-Benutzern durchgeführt, die funktionale Befehle ausführen und Geschäftsregeln erstellen, um die Aufgabe zu erledigen.
Dadurch ist der Geschäftskunde im Nachteil. Sie müssen sich auf die IT verlassen, um Daten aufzubereiten, die ihnen gehören und die sie besser verstehen können. Wenn die IT-Abteilung keine Datenvorbereitungstools einsetzt, sondern sich bei der Lösung komplexer Datenprobleme auf ETL-Methoden verlässt, werden die Geschäftsanwender wahrscheinlich die Leidtragenden sein, die sich über Kundenbeschwerden und kostspielige Fehler beschweren.
Was ist also die Lösung für dieses Problem?
Geben Sie die Datenaufbereitung in Selbstbedienung ein.
Was ist Self-Service-Datenvorbereitung?
In einem Prozess, der nach wie vor als IT-dominiert gilt, liegt die Datenaufbereitung kaum in den Händen der Fachanwender. Dies gilt auch, wenn das Unternehmen ein zentrales ERP oder Data Warehouse betreibt, das nicht für Geschäftsanwender zugelassen ist. Aber ein Unternehmen verfügt heute über verschiedene Arten von Daten, und nicht alle diese Daten müssen von der IT-Abteilung verwaltet werden. Kundendatensätze, Daten von Marketingkampagnen, Mailinglisten usw. müssen nicht von der IT-Abteilung bearbeitet werden, und sie erfordern auch keine ETL-Prozesse.
Hier erfahren Sie, wie sich ETL und Datenaufbereitung unterscheiden und warum ETL sein EOL-Stadium erreicht.
Wie kann ein Geschäftsanwender also schnell Hunderttausende von Zeilen mit fehlerhaften Daten korrigieren? Ist es über Excel, das wiederum die Beherrschung von Funktionen und Formeln erfordert? Hier kommen die Tools für die Datenaufbereitung zur Selbstbedienung ins Spiel.
Wie der Name schon sagt, bieten Self-Service-Datenvorbereitungstools die Möglichkeit, dass sachkundige Benutzer (insbesondere Geschäftsanwender, die keine IT-Experten sind) ihre Daten kombinieren, bereinigen, deduzieren, organisieren und für die Verwendung vorbereiten. Die meisten Tools in dieser Self-Service-Kategorie richten sich an Unternehmensanalysten, Datenwissenschaftler und alle Benutzer, die häufig mit großen Datenmengen arbeiten müssen.
Was bewirkt es?
Es gibt mehrere Funktionen, die Sie ausführen müssen, um die Daten für die vorgesehene Verwendung vorzubereiten. Normalerweise würde jede dieser Funktionen Stunden und Tage in Anspruch nehmen, um erledigt zu werden.
Wenn ein Geschäftsanwender beispielsweise hunderttausend Adressen bereinigen muss, muss er dies manuell tun, indem er zunächst die Daten aus dem CRM extrahiert, sie in Excel importiert und Funktionen und Formeln ausführt, um die Daten zu korrigieren. Die Korrekturen werden jedoch oberflächlich sein. Der Benutzer kann höchstens Tippfehler oder Rechtschreibfehler und redundante Daten in den Feldern selbst korrigieren. Sie können keine komplexen Aufgaben wie Datendeduplizierung oder Datenabgleich (auch Konsolidierung genannt) durchführen, wenn sie Daten von Dritten kombinieren wollen.
Die Self-Service-Datenaufbereitung ist somit eine moderne Lösung für uralte Probleme wie Konflikte zwischen Fachanwendern und IT, Abhängigkeiten und Prozesse, die nicht dem Geschäftszweck der Datenerfassung dienen. Da Unternehmen heute einen datengesteuerten Ansatz fordern, müssen Geschäftsanwender mit einem Tool ausgestattet werden, das es ihnen ermöglicht, komplexe Daten in großem Umfang zu erforschen – ohne dass technische Fähigkeiten oder Programmiersprachenkenntnisse erforderlich sind.
Self-Service-Tools für die Datenvorbereitung demokratisieren den Datenvorbereitungsprozess, und das ist eine dringend benötigte Erleichterung bei CRM-Datenproblemen.
Wie funktionieren Self-Service-Datenvorbereitungstools?
Die meisten Self-Service-Tools zur Datenvorbereitung sind einfach zu bedienen. Natürlich gibt es eine Lernkurve, die mit jeder Software einhergeht, und Sie benötigen eine Einarbeitung, aber da die meisten Tools eine Drag-and-Drop-Oberfläche bieten, muss sich der Benutzer nicht auf das Erlernen oder Merken von Funktionen konzentrieren.
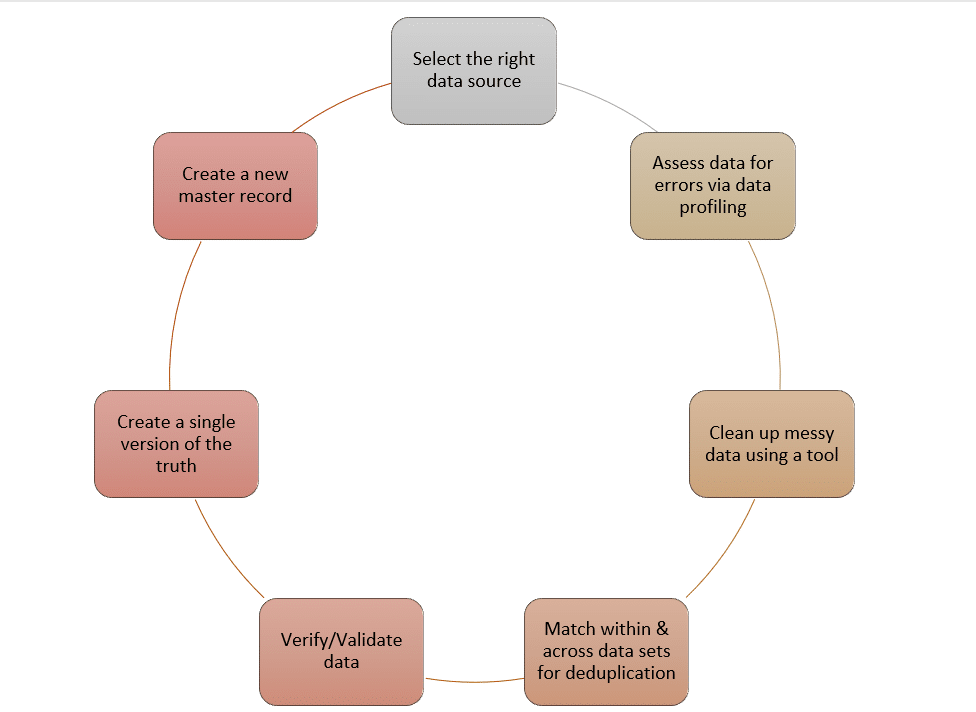
Datenvorbereitungstools haben die gleichen Ziele, aber unterschiedliche Formen und Funktionen. Bei einigen können Sie nur Daten korrigieren, ohne einen erweiterten Datenabgleich durchzuführen. In einigen Fällen müssen Sie für jede Funktion eine Gruppe von Werkzeugen verwenden. Einige konzentrieren sich nur auf spezifische Datenvorbereitungsfunktionen wie Datenprofilierung, Datenintegration oder Datenbereinigung.
Es gibt nur wenige Tools, die einen vielschichtigen Ansatz für die Datenvorbereitung ermöglichen. Davon ist DataMatch Enterprise das einzige Tool, das einen 8-stufigen Arbeitsablauf hat.
Wenn Sie ein Tool wie DataMatch Enterprise verwenden, brauchen Sie nur Ihre Datenquelle in das Tool zu importieren, sie Schritt für Schritt durch die Module laufen zu lassen und eine Ausgabe zu erhalten, die Ihren Anforderungen entspricht.
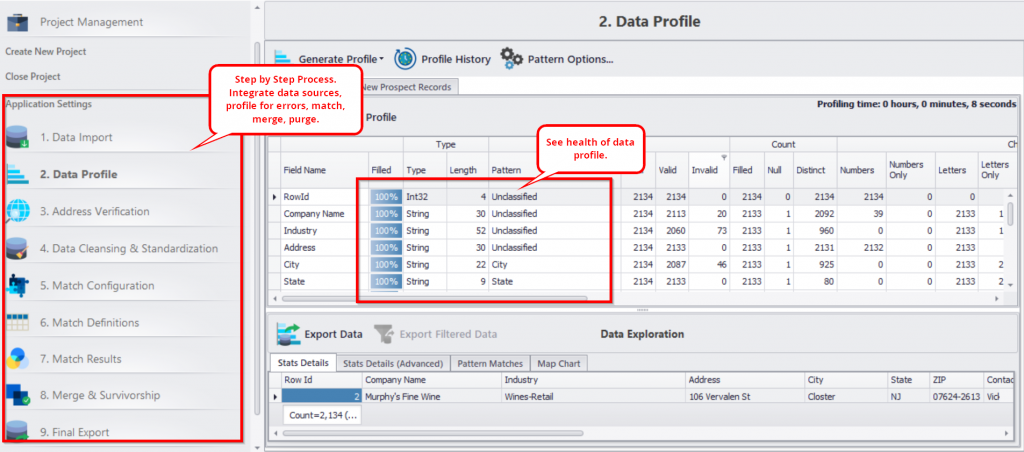
Jeder Schritt des Moduls erfüllt wichtige Funktionen wie:
Datenintegration: Integrieren Sie Daten aus mehr als 150 Anwendungen und leiten Sie Datensätze ab, die Sie für Ihre Analysen und Berichte benötigen. Das bedeutet, dass Sie Daten aus Social-Media-Quellen wie Facebook und Twitter, Big-Data-Plattformen wie Hadoop und CRM-Plattformen wie Salesforce und HubSpot importieren können. Sie integrieren die Plattform einfach in DME und nehmen nach und nach Korrekturen vor.
Daten-Profiling: Identifizieren Sie die Schwachstellen Ihrer Daten visuell und verschaffen Sie sich einen Überblick über den Zustand Ihrer Daten. Sie können die Anzahl der falsch geschriebenen Namen, Tippfehler und andere häufige Datenqualitätsprobleme in mehreren Spalten kategorisiert sehen.
Saubere Daten: Die Datenbereinigung wird durch die Anwendung vordefinierter Regeln auf Ihre Daten erreicht. Mit diesen Regeln können Sie unordentliche Daten bereinigen und nach festgelegten Standards standardisieren. Wenn Ihre Datenspalten beispielsweise Probleme mit gemischter Groß- und Kleinschreibung aufweisen, können Sie sie bereinigen, indem Sie mit einem einfachen Klick auf das Kontrollkästchen eine Großbuchstabenfunktion auf die Daten anwenden.
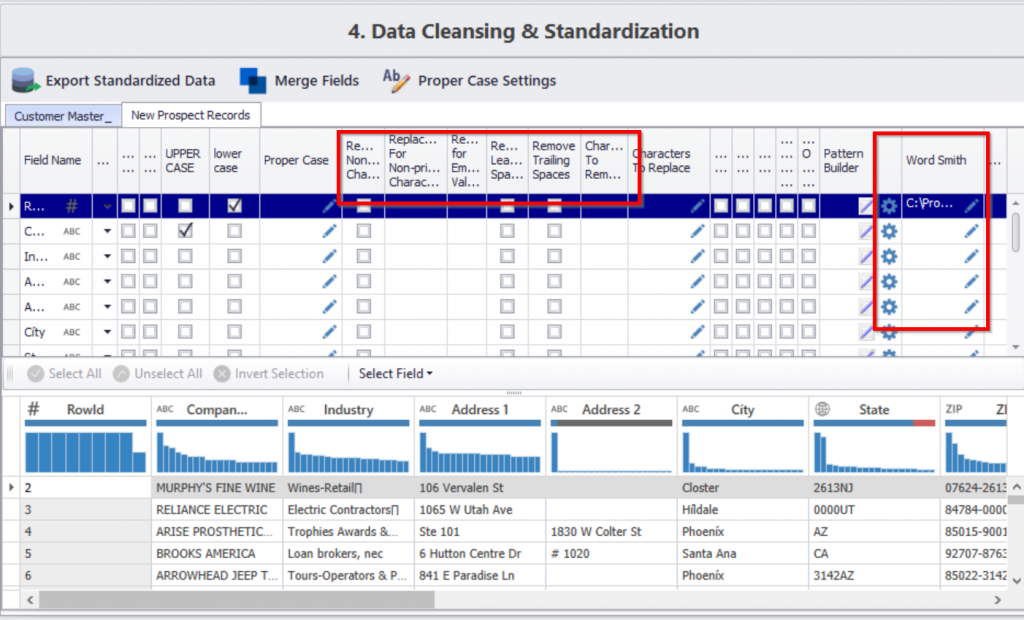
Daten abgleichen: Abgleich von Daten innerhalb, zwischen oder über mehrere Datenquellen hinweg unter Verwendung einer Kombination aus Fuzzy-Matching-Algorithmen und dem softwareeigenen Algorithmus. Der Datenabgleich ist die Grundlage der Datenaufbereitung, denn nur so können Sie Duplikate aus Ihren Daten entfernen. Wenn das von Ihnen verwendete Tool keine 100-prozentige Datenabgleichsgenauigkeit aufweist, gibt es in Ihren Daten wahrscheinlich Tausende von versteckten Duplikaten, die nicht leicht zu erkennen sind.
Zusammenführen: Müssen Sie mehrere Datensätze zu einer einzigen Quelle der Wahrheit zusammenführen? Die Plattform ermöglicht es Ihnen, verschiedene Datenquellen zu konsolidieren, was hilfreich ist, wenn Sie ein Projekt zur Datenanreicherung initiieren. Außerdem können Sie diese Versionen mit der Option des Datenüberlebens speichern, ohne die ursprüngliche Version zu verlieren.
All diese Funktionen würden normalerweise Monate in Anspruch nehmen. Allein die Profilerstellung würde Wochen dauern. Bereinigung und Deduplizierung nehmen Monate in Anspruch, vor allem, wenn Sie mit Hunderttausenden von Datensätzen zu tun haben.
Da der Prozess so komplex ist, versuchen die meisten Unternehmen, Korrekturen direkt am CRM oder an den eigentlichen Datenquellen selbst vorzunehmen, was zu zukünftigen Problemen führt. Es ist nicht ungewöhnlich, dass Teams doppelte oder fehlerhafte Daten erhalten, weil ein anderes Teammitglied unangekündigte und nicht genehmigte Änderungen vorgenommen hat.
Ein Datenvorbereitungstool verhindert, dass diese Frustrationen überhand nehmen, und ermöglicht es den Geschäftsanwendern, einem Vorbereitungsprozess zu folgen, bei dem sie Daten sicher bereinigen und sogar Kopien davon zur späteren Verwendung speichern können.
Die wichtigsten Vorteile eines Self-Service-Datenvorbereitungstools:
Der Self-Service-Ansatz von DataMatch Enterprise für die Datenvorbereitung hat Fortune-500-Unternehmen wie HP, Deloitte und Coca Cola geholfen, Datenqualitätsprobleme von unterwegs aus zu lösen. Wir spielen auch eine Schlüsselrolle in Behörden und öffentlichen Einrichtungen, wo Nicht-IT-Experten das Tool für den Datenabgleich zwischen und innerhalb von Behörden nutzen können. Wir sind bekannt für unsere benutzerfreundliche Oberfläche und die Leichtigkeit, mit der Unternehmen Routineaufgaben der Datenaufbereitung durchführen können.
Die Benutzerfreundlichkeit ist zwar ein Hauptvorteil, aber es gibt noch weitere, wenn Sie in das richtige Werkzeug investieren. Ganz gleich, ob Sie ein kleines Unternehmen, ein Konzern oder eine staatliche Einrichtung sind, die Self-Service-Datenaufbereitung kann Ihnen helfen:
Sparen Sie Zeit und Mühe: Sie müssen nicht erst eine Woche mit der Korrektur von Daten verbringen, bevor Sie sie für Einblicke oder Analysen einrichten können. Sie können in weniger als 45 Minuten Erkenntnisse aus 100.000 Datensätzen gewinnen.
Keine Notwendigkeit für ETL oder Datenmodellierung: Natürlich keine komplexen Extraktions-, Lade- und Transformationsvorgänge mehr. Eine Datenaufbereitungssoftware kann problemlos zur Bereinigung großer Datenmengen für die Cloud-Migration oder die CRM-Migration verwendet werden. Sie brauchen weder ETL noch Datenmodellierung, um dies zu erreichen.
Einfach für Geschäftsanwender: Diese Tools sind für alle gedacht: Geschäftsanwender, IT-Experten, Datenanalysten und alle, die ihre Daten und die von ihnen gewünschten Ergebnisse verstehen.
Flexibel und skalierbar: Die Datenmenge, die Sie profilieren können, ist unbegrenzt. Die größere Benutzerfreundlichkeit ermöglicht es den Nutzern, sich mit mehreren verschiedenen Quellen zu verbinden und Daten spontan zu kombinieren und zu konsolidieren.
Geringere Abhängigkeit von der IT: Datenaufbereitung und Datenqualität liegen nicht allein in der Verantwortung der IT-Abteilung. Es macht also keinen Sinn, sie mit der Korrektur von CRM- oder Marketingdaten zu belasten, wenn sie mit den Daten nicht vertraut sind. Ein Geschäftsanwender versteht seine Daten viel besser als ein IT-Anwender, daher ist es notwendig, dass er die Verantwortung für die Datenqualität und die Datenvorbereitung übernimmt.
Ein Self-Service-Tool für die Datenaufbereitung ist nur dann gut, wenn es Benutzer ohne technischen Hintergrund in die Lage versetzt, mit ihren Daten zu arbeiten. Wenn das Tool zusätzliche Programmierkenntnisse oder eine spezielle Sprache erfordert, ist es nicht die richtige Wahl.
Wie wählen Sie das richtige Self-Service-Datenvorbereitungstool?
Es gibt immer mehr Anbieter von Self-Service-Datenvorbereitung, und es kann schwierig sein, die richtige Wahl zu treffen. Wenn Sie auf der Suche nach dem richtigen Werkzeug sind, sollten Sie die folgenden Bedingungen abhaken:
- Es muss eine benutzerfreundliche Oberfläche haben: Der Sinn eines Tools zur Selbstvorbereitung besteht darin, die Datenvorbereitung in kurzer Zeit zu erledigen. Wenn die Benutzeroberfläche nicht benutzerfreundlich ist und ein Verständnis für relationale Datenbanken erfordert, bei denen die Benutzer verschiedene Datenquellen manuell verbinden müssen, dann erfüllt sie wahrscheinlich nicht ihren Zweck. Die Benutzeroberfläche sollte per Drag & Drop oder per Mausklick zu bedienen sein.
- Es muss dem Benutzer helfen, die Datenqualitätsstandards einzuhalten: Daten, die vollständig, genau, zugänglich und relevant sind und dem beabsichtigten Zweck dienen, gelten als qualitativ hochwertig. Ein Datenvorbereitungstool muss es dem Benutzer ermöglichen, diese Standards durch Funktionen zur Datenbereinigung, Deduplizierung, Standardisierung und Validierung zu erreichen. Vergleichen Sie bei der Auswahl des Geräts mit dieser Liste von Normen. Glauben Sie, dass es Ihnen helfen wird, dieses Ziel zu erreichen?
- Sie muss eine starke Datenabgleichsfunktion haben: Bei der Datenaufbereitung geht es nicht nur um die Behebung oberflächlicher Probleme. Sie behebt tief verwurzelte Probleme wie Datenduplizierung, für die der Datenabgleich die einzige Lösung ist. Um Duplikate zu entfernen, die zwar ähnlich sind, aber nicht exakt übereinstimmen, benötigen Sie ein Tool, das bewährte Fuzzy-Matching-Algorithmen zur Deduktion komplexer Daten verwendet.
- Es muss mehrere Datenintegrationen zulassen: Während einige Unternehmen auf diese Funktion verzichten können, wenn sie hauptsächlich mit CSV-Dateien arbeiten, wird dies für Unternehmen mit Plattformen wie Hadoop oder Salesforce ein Problem darstellen. Die von Ihnen gewählte Lösung sollte die Integration mit verschiedenen CRMs und Datenquellen ermöglichen.
- Sie muss sicher sein und als Vor-Ort-Lösung verfügbar sein: Einige Organisationen und staatliche Einrichtungen sind mit einer Webversion nicht einverstanden. Sie wünschen sich eine Lösung vor Ort, bei der sie die vollständige Kontrolle über ihre Daten haben. Vor-Ort-Lösungen sind am sichersten und können problemlos auf Ihrem Desktop oder Cloud-Server verwendet werden.
Self-Service-Tools zur Datenvorbereitung gibt es schon seit einigen Jahren, aber erst jetzt, mit dem Aufkommen von KI, ML, BI und anderen digitalen Revolutionen, sind sie in den Mittelpunkt der Datenverwaltung gerückt. Wenn Sie wirklich datengesteuert arbeiten wollen, sollten Sie Ihren Teams das richtige Werkzeug an die Hand geben.
Möchten Sie wissen, wie Data Ladder Ihnen helfen kann, dieses Ziel zu erreichen? Nehmen Sie Kontakt mit einem unserer Lösungsarchitekten auf, um mehr zu erfahren.



