





























Last Updated on mars 30, 2022
Les outils de préparation des données existent depuis un certain temps déjà. La plupart de ces outils exigent cependant que les utilisateurs maîtrisent les langages de programmation et les bases de données relationnelles pour les utiliser. Le nettoyage, la transformation et la préparation des données sont généralement effectués par des utilisateurs informatiques qui exécutent des commandes fonctionnelles et créent des règles de gestion pour accomplir cette tâche.
L’utilisateur professionnel est donc désavantagé. Ils doivent s’en remettre à l’informatique pour préparer les données qu’ils possèdent et dont ils ont une meilleure compréhension. De plus, si le service informatique n’utilise pas d’outils de préparation des données, mais s’en remet aux méthodes ETL pour résoudre les problèmes de données complexes, il y a de fortes chances que les utilisateurs professionnels soient confrontés à des clients mécontents et à des erreurs coûteuses.
Alors quelle est la solution à ce problème ?
Saisir la préparation des données en libre-service.
Qu’est-ce que la préparation des données en libre-service ?
Dans ce qui a été et continue d’être considéré comme un processus à dominante informatique, la préparation des données n’est guère entre les mains d’un utilisateur professionnel. Cela est vrai si l’entreprise exploite un ERP ou un entrepôt de données centralisé qui n’est pas autorisé aux utilisateurs professionnels. Mais aujourd’hui, une entreprise dispose de différentes formes de données et toutes ces données n’ont pas besoin d’être traitées par l’informatique. Par exemple, les dossiers des clients, les données des campagnes de marketing, les listes de diffusion, etc. n’ont pas besoin de l’intervention du service informatique et ne nécessitent pas non plus de processus ETL.
Voici en quoi l’ETL et la préparation des données sont différents et pourquoi l’ETL atteint son stade d’obsolescence.
Alors, comment un utilisateur professionnel peut-il corriger rapidement des centaines de milliers de lignes de données erronées ? Est-ce par l’intermédiaire d’Excel qui nécessite à nouveau la maîtrise des fonctions et des formules ? C’est là que les outils de préparation des données en libre-service entrent en jeu.
Comme leur nom l’indique, les outils de préparation des données en libre-service ont la capacité de permettre aux utilisateurs avertis (plus précisément aux utilisateurs professionnels qui ne sont pas des experts en informatique) de combiner, nettoyer, déduire, organiser et préparer leurs données en vue de leur utilisation. La plupart des outils de cette catégorie de libre-service sont destinés aux analystes d’entreprise, aux scientifiques des données et à tout utilisateur devant travailler fréquemment avec de grandes quantités de données.
Que fait-il ?
Il existe de multiples fonctions que vous devez exécuter pour préparer les données à leur utilisation prévue. Habituellement, chacune de ces fonctions prendrait des heures et des jours pour disparaître.
Par exemple, si un utilisateur professionnel doit nettoyer cent mille adresses, il devra travailler manuellement en extrayant d’abord les données du CRM, en les important dans Excel et en exécutant des fonctions et des formules pour corriger ces données. Les corrections seront toutefois superficielles. Le maximum qu’un utilisateur puisse faire est de corriger les fautes de frappe ou d’orthographe et les données redondantes dans les champs eux-mêmes. Ils ne peuvent pas effectuer des tâches complexes comme la déduplication des données ou le rapprochement des données (ou consolidation) s’ils veulent combiner des données provenant de tiers.
La préparation des données en libre-service est donc une solution moderne aux problèmes séculaires de conflits entre les utilisateurs et l’informatique, de dépendances et de processus qui ne servent pas l’objectif commercial d’acquisition des données. Aujourd’hui, alors que les entreprises exigent une approche axée sur les données, les utilisateurs professionnels doivent être équipés d’un outil qui leur permet d’explorer des données complexes à grande échelle, sans exiger de compétences techniques ou de connaissances en langage de programmation.
Les outils de préparation des données en libre-service démocratisent le processus de préparation des données et c’est un répit bien nécessaire pour les problèmes de données CRM.
Comment fonctionnent les outils de préparation des données en libre-service ?
La plupart des outils de préparation des données en libre-service sont faciles à utiliser. Bien sûr, chaque logiciel comporte une courbe d’apprentissage et une formation initiale est nécessaire, mais comme la plupart des outils offrent une interface de type glisser-déposer, l’utilisateur n’a pas besoin de se concentrer sur l’apprentissage ou la mémorisation des fonctions.
Les outils de préparation des données ont les mêmes objectifs mais des formes et des fonctionnalités différentes. Certains vous permettront simplement de fixer les données sans procéder à un rapprochement avancé. Certains vous demanderont d’utiliser un groupe d’outils pour chaque fonction. Certains se concentrent sur des fonctions spécifiques de préparation des données, comme le profilage des données, l’intégration des données ou le nettoyage des données uniquement.
Il n’existe que peu d’outils permettant une approche à multiples facettes de la préparation des données. Parmi ceux-ci, DataMatch Enterprise est le seul outil qui dispose d’un flux de travail en 8 étapes.
Si vous utilisez un outil comme DataMatch Enterprise, il vous suffit d’importer votre source de données dans l’outil, de la faire passer par les modules étape par étape et d’obtenir un résultat qui répond à vos besoins.
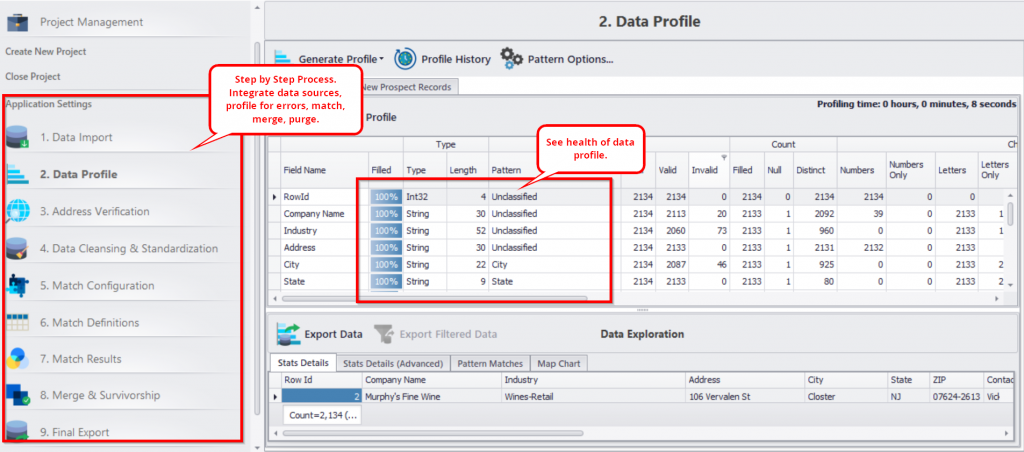
Chaque étape du module remplit des fonctions essentielles comme :
Intégration des données : Intégrez les données de plus de 150 applications et obtenez les ensembles de données dont vous avez besoin pour vos analyses et rapports. Cela signifie que vous pouvez importer des données provenant de sources de médias sociaux comme Facebook et Twitter, de plateformes de big data comme Hadoop, de plateformes de CRM comme Salesforce et HubSpot. Il vous suffit d’intégrer la plate-forme à DME et d’apporter des corrections au fur et à mesure.
Profilage des données : Identifiez visuellement les failles de vos données et obtenez une vue d’ensemble de la santé de vos données. Vous pouvez voir le nombre de noms mal orthographiés, de fautes de frappe et d’autres problèmes courants de qualité des données, classés en plusieurs colonnes.
Nettoyer les données : Le nettoyage des données est réalisé en appliquant des règles prédéfinies sur vos données. Grâce à ces règles, vous pouvez nettoyer les données désordonnées et les normaliser en fonction de normes établies. Par exemple, si vos colonnes de données souffrent de problèmes de majuscules et de minuscules, vous pouvez les nettoyer en appliquant une fonction de majuscules aux données par un simple clic sur une case à cocher.
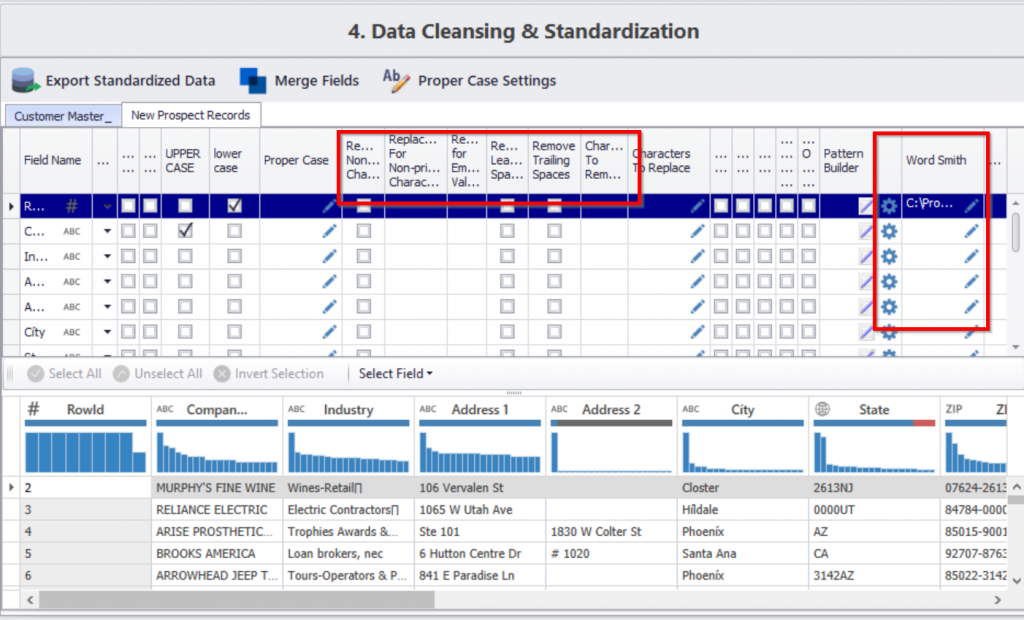
Appariement des données : Faites correspondre les données à l’intérieur, entre ou à travers plusieurs sources de données en utilisant une combinaison d’algorithmes de correspondance flous et l’algorithme propriétaire du logiciel. Le rapprochement des données est la base même de la préparation des données, car c’est le seul moyen de supprimer les doublons de vos données. Si l’outil que vous utilisez n’a pas une précision de 100 % en matière de correspondance des données, vos données contiennent probablement des milliers de doublons cachés qui ne peuvent pas être facilement détectés.
Fusionner : Vous devez fusionner plusieurs enregistrements en une seule source de vérité ? La plateforme vous permet de consolider différentes sources de données, ce qui est utile si vous lancez un projet d’enrichissement des données. De plus, grâce à l’option de survie des données, vous pouvez sauvegarder ces versions sans perdre la version originale.
Toutes ces fonctions prendraient généralement des mois à réaliser. Le profilage seul prendrait des semaines. Le nettoyage et la déduplication prennent des mois, surtout si vous devez traiter des centaines de milliers d’enregistrements.
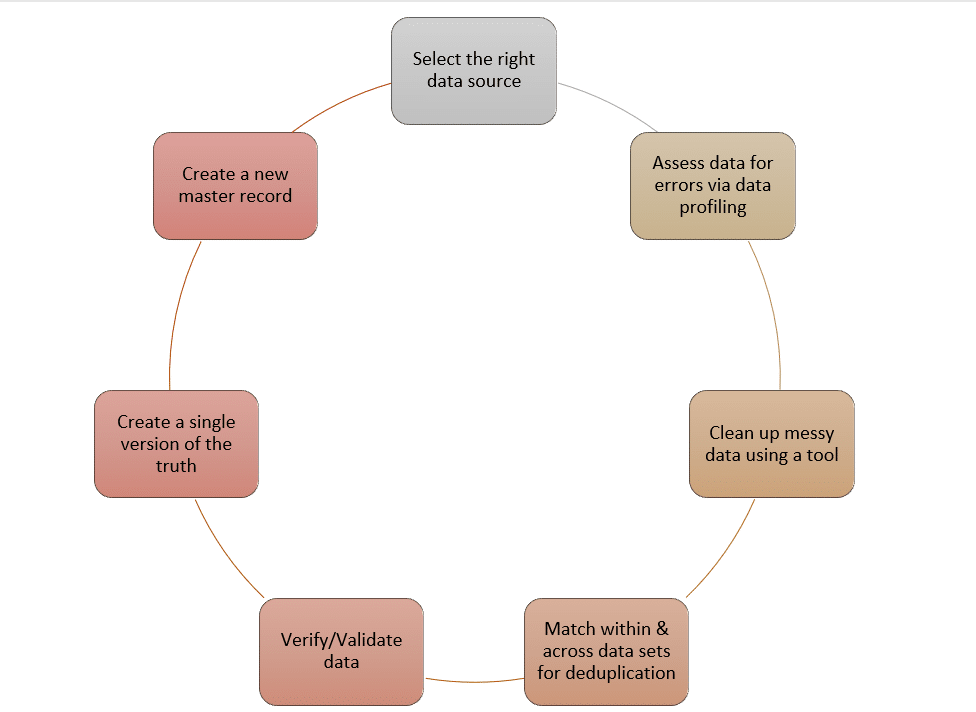
En raison de la complexité du processus, la plupart des entreprises tentent d’apporter des corrections directement sur le CRM ou sur les sources de données elles-mêmes, ce qui entraîne des problèmes futurs. Il n’est pas rare que des équipes se retrouvent avec des données en double ou des données erronées parce qu’un autre membre de l’équipe a effectué des ajustements non annoncés et non approuvés.
Un outil de préparation des données empêchera ces frustrations de prendre le dessus et permettra à l’utilisateur professionnel de suivre un processus de préparation au cours duquel il pourra nettoyer les données en toute sécurité et même en sauvegarder des copies pour une utilisation ultérieure.
Principaux avantages d’un outil de préparation des données en libre-service :
L’approche en libre-service de DataMatch Enterprise pour la préparation des données a permis à des entreprises du classement Fortune 500 comme HP, Deloitte, Coca Cola de résoudre les problèmes de qualité des données en déplacement. Nous jouons également un rôle clé dans les administrations et les instituts du secteur public où des experts non informaticiens peuvent utiliser l’outil pour effectuer des rapprochements de données inter et intra-agences. Nous sommes reconnus pour notre interface conviviale et la facilité avec laquelle les entreprises peuvent effectuer des tâches de préparation de données de routine.
Si la facilité d’utilisation est un avantage clé, il en existe plusieurs autres si vous investissez dans le bon outil. Que vous soyez une petite entreprise, une société ou un organisme public, la préparation des données en libre-service peut vous aider :
Économisez du temps et de l’énergie : Vous n’avez pas besoin de perdre une semaine à réparer des données avant de pouvoir les configurer pour des aperçus ou des analyses. Vous pouvez extraire des informations de 100 000 enregistrements en moins de 45 minutes.
Plus besoin d’ETL ou de modélisation des données : Bien sûr, plus d’opérations complexes d’extraction, de chargement et de transformation. Un logiciel de préparation des données peut facilement être utilisé pour nettoyer des quantités massives de données à des fins de migration vers le cloud ou vers le CRM. Vous n’avez pas besoin d’ETL, ni de modélisation des données pour y parvenir.
Facile pour l’utilisateur professionnel : ces outils sont conçus pour tout le monde ; les utilisateurs professionnels, les experts en informatique, les analystes de données et tous ceux qui comprennent leurs données et les résultats qu’ils veulent en tirer.
Flexible et évolutif : Il n’y a pas de limite à la quantité de données que vous pouvez profiler. Une plus grande facilité d’utilisation permet aux utilisateurs de se connecter à plusieurs sources différentes, de combiner et de consolider les données à la volée.
Réduction de la dépendance à l’égard de l’informatique : La préparation et la qualité des données ne relèvent pas uniquement de la responsabilité des services informatiques. Il n’est donc pas logique de les charger de réparer les données CRM ou les données marketing alors qu’ils ne sont pas familiarisés avec ces données. Un utilisateur professionnel comprend ses données bien mieux qu’un utilisateur informatique. Il est donc nécessaire qu’il s’approprie la qualité et la préparation des données.
Un outil de préparation des données en libre-service n’est bon que s’il permet à des utilisateurs non techniques de travailler avec leurs données. Si l’outil nécessite des connaissances supplémentaires en programmation ou un langage spécial pour fonctionner, ce n’est pas le bon choix.
Comment choisir le bon outil de préparation des données en libre-service ?
Les fournisseurs de solutions de préparation des données en libre-service sont de plus en plus nombreux et il peut être difficile de faire le bon choix. Si vous êtes sur le marché de la chasse au bon outil, assurez-vous de cocher les conditions suivantes :
- Il doit avoir une interface utilisateur conviviale : L’objectif d’un outil d’auto-préparation est de permettre la préparation des données en un temps record. Si l’interface utilisateur n’est pas conviviale et nécessite une compréhension des bases de données relationnelles où les utilisateurs doivent connecter manuellement différentes sources de données, alors elle ne sert probablement pas son objectif. L’interface utilisateur devrait être un simple glisser-déposer ou un clic et c’est parti.
- Il doit aider l’utilisateur à respecter les normes de qualité des données : Les données qui sont complètes, exactes, accessibles, pertinentes et qui servent l’objectif visé sont considérées comme étant de haute qualité. Un outil de préparation des données doit permettre à l’utilisateur de respecter ces normes grâce à des fonctions de nettoyage, de dédoublonnage, de normalisation et de validation des données. Lorsque vous choisissez l’outil, comparez-le à cette liste de normes. Pensez-vous qu’il vous aidera à atteindre cet objectif ?
- Il doit avoir une forte fonction de mise en correspondance des données : La préparation des données ne consiste pas seulement à résoudre des problèmes superficiels. Il s’agit de résoudre des problèmes profondément ancrés, tels que la duplication des données, pour lesquels le rapprochement des données est la seule solution. Pour supprimer les doublons qui sont similaires mais ne correspondent pas exactement, vous aurez besoin d’un outil qui utilise des algorithmes de correspondance floue établis pour déduire des données complexes.
- Il doit permettre des intégrations de données multiples : Si certaines entreprises peuvent se passer de cette fonctionnalité si elles fonctionnent principalement avec des fichiers CSV, cela posera un problème aux entreprises disposant de plateformes comme Hadoop ou Salesforce. La solution de votre choix doit pouvoir permettre des intégrations avec différents CRM et sources de données.
- Elle doit être sécurisée et être disponible en tant que solution sur site : Certaines organisations et institutions gouvernementales ne sont pas à l’aise avec une version web. Ils veulent une solution sur site où ils ont un contrôle total sur leurs données. Les solutions sur site sont les plus sûres et peuvent facilement être utilisées sur votre bureau ou sur un serveur en nuage.
Les outils de préparation des données en libre-service existent depuis un certain nombre d’années, mais ce n’est que maintenant que l’essor de l’IA, du ML, de la BI et d’autres révolutions numériques l’ont fait devenir la scène centrale de la gestion des données. Si vous cherchez vraiment à être axé sur les données, donnez à vos équipes le bon outil.
Vous voulez savoir comment Data Ladder peut vous aider à atteindre cet objectif ? Contactez l’un de nos architectes de solutions pour en savoir plus.



