































Last Updated on January 28, 2026
Data preparation tools have been around for quite some time now. Most of these tools though require users to be proficient in programming languages & relational databases to operate them. Data cleaning, transforming & preparing is usually done by IT users who run functional commands and create business rules to do the task.
This leaves the business user at a disadvantage. They have to rely on IT to prepare data that they own and have a better understanding of. Moreover, if IT does not use data preparation tools, but relies on ETL methods to resolve complex data issues, chances are business users will face the brunt of complaining customers and costly mistakes.
So what’s the solution to this?
Enter self-service data preparation.
What is Self-Service Data Preparation?
In what has been and continues to be considered as an IT-dominant process, data preparation is hardly in the hands of a business user. This holds true if the company operates a centralized ERP or data warehouse which is not authorized for business users. But a company today has different forms of data and all of this data don’t need to be handled by IT. For instance, customer records, marketing campaign data, mailing lists, etc don’t need IT’s involvement and neither do they require ETL processes.
Here's how ETL and data preparation are different and why ETL is reaching its EOL stage.
ETL vs Data Preparation
DownloadSo how then can a business user quickly fix hundreds of thousands of rows of bad data? Is it via Excel that again requires proficiency in functions and formulas? Well, that’s where self-service data preparation tools come in.
As the name implies, self-service data preparation tools have the capabilities to allow knowledgeable users (more specifically business users who are not IT experts) to combine, clean, dedupe, organize and prepare their data for use. Most tools in this self-service category are aimed at business analysts, data scientists, and any user who has to work with copious amounts of data frequently.
What Does it Do?
There are multiple functions that you need to perform to prepare data for its intended use. Usually, each of these functions would take hours and days to get gone.
For instance, if a business user has to clean up a hundred thousand addresses, they will need to manually work on that by first extracting the data from the CRM, importing it into Excel and running functions and formulas to fix that data. The fixes though will be superficial. The maximum a user can do is fix typos or spellings and redundant data within fields itself. They cannot carry out complex tasks like data deduplication or data matching (aka consolidation) if they want to combine third-party data.
Self-service data preparation then is a modern solution to age-old problems of conflicts between business users and IT, dependencies and processes that do not serve the business purpose of acquiring data. Today, as companies demand a data-driven approach, business users must be equipped with a tool that allows them to explore complex data at scale – without imposing demands of technical skills or programming language knowledge.
Self-service data preparation tools are democratizing the data preparation process and that’s a much-needed reprieve to CRM data woes.
How Does Self-service Data Preparation Tools Work?
Most self-service data prep tools are easy to use. Of course, there is a learning curve that comes with every software and you do need initial training but because most tools offer a drag and drop interface, the user does not need to focus on learning or remember functions.
Data prep tools share the same goals but different forms and functionalities. Some will just let you fix data without advanced data matching. Some will require you to use a group of tools for each function. Some are focused on specific data prep functions like data profiling, data integration or data cleaning only.
There are only a few tools that allow for a multi-faceted approach to data prep. Of these, DataMatch Enterprise is the only tool that has an 8-step workflow.
If you’re using a tool like DataMatch Enterprise, all you do is import your data source in the tool, run it through the step-by-step modules and get an output that caters to your requirements.
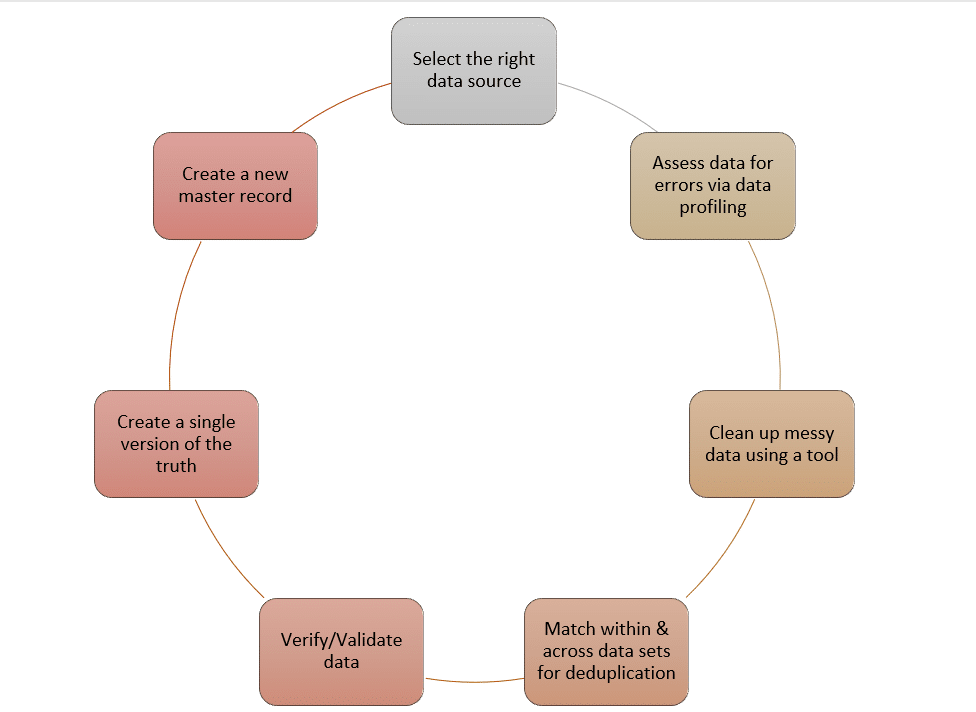
Each step of the module performs critical functions as:
Data Integration: Integrate data from over 150+ applications and derive data sets that you need for your analysis and reports. This means you can import data from social media sources like Facebook and Twitter, big data platforms like Hadoop, CRM platforms like Salesforce and HubSpot. You simply integrate the platform with DME and make fixes as you go.
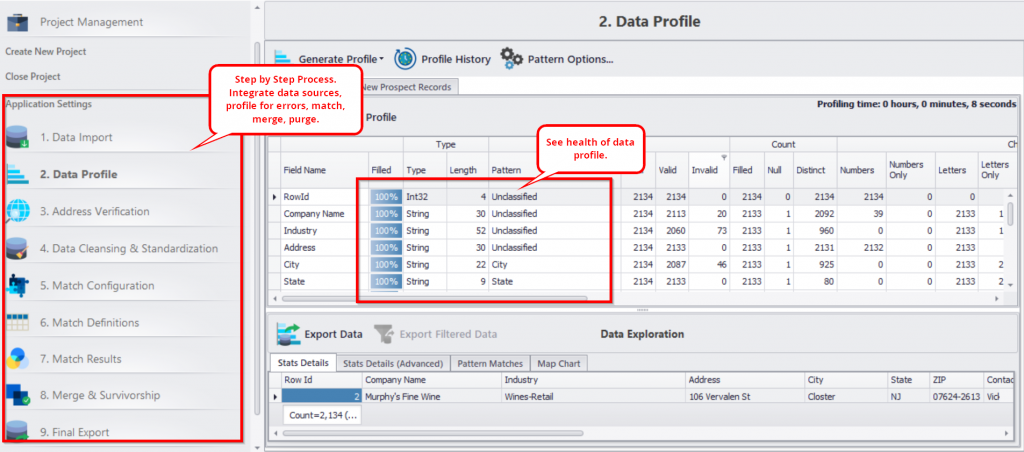
Data Profiling: Identify the flaws of your data visually and get an overview of your data health. You can see the number of misspelled names, typos and other common data quality problems categorized into multiple columns.
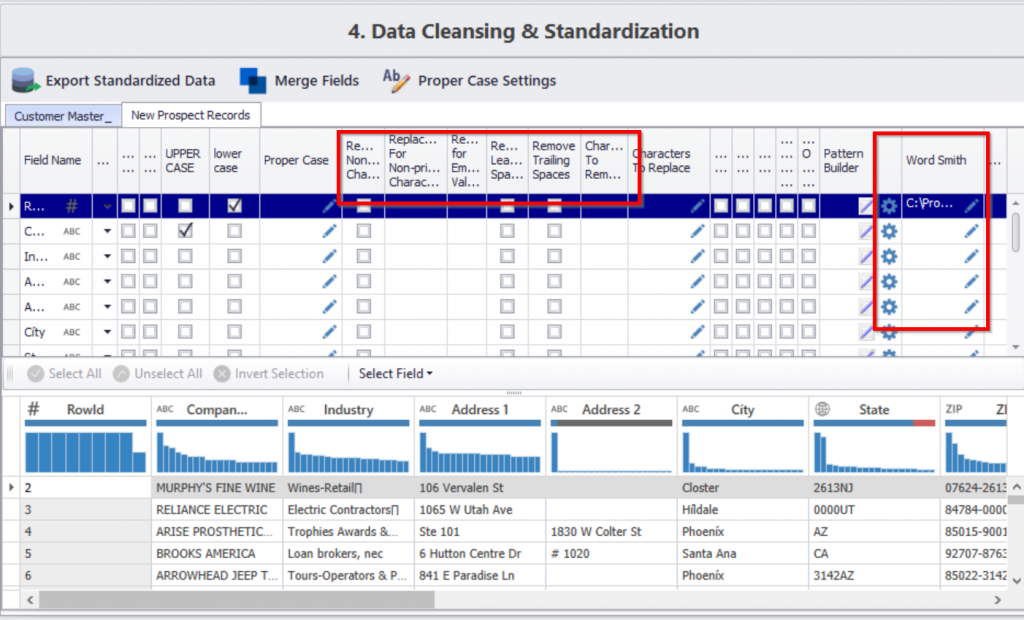
Clean Data: Data cleaning is achieved by applying pre-defined rules on your data. With these rules, you can clean up messy data and standardize it according to established standards. For instance, if your data columns are suffering from mixed case issues, you can clean them up by applying an upper-case function on the data with a simple check-box click.
Match Data: Match data from within, between or across multiple data sources using a combination of fuzzy matching algorithms and the software’s proprietary algorithm. Data matching is the very foundation of data preparation because it is the only way you can remove duplicates from your data. If the tool you’re using does not have a 100% data match accuracy, your data probably has thousands of hidden duplicates that cannot be easily detected.
Merge: Need to merge multiple records into a single source of truth? The platform allows you to consolidate different data sources which is helpful if you’re initiating a data enrichment project. Moreover, with the option of data survivorship, you can save these versions without losing the original version.
All these functions would typically take months to pull off. Profiling alone would take weeks. Cleaning and deduping take months especially if you have to deal with hundreds of thousands of records.
Because the process is so complex, most businesses attempt to make fixes directly on the CRM or on actual data sources itself which results in future problems. It’s not uncommon for teams to end up with duplicated data or error-ridden data because another team member made unannounced and unapproved adjustments.
A data preparation tool will prevent these frustrations from taking over and will enable the business user to follow a preparation process where they can safely clean data and even save copies of it for later use.
Key Benefits of a Self-Service Data Preparation Tool:
DataMatch Enterprise’s self-service approach to data prep has helped Fortune 500 companies like HP, Deloitte, Coca Cola resolve data quality issues on the go. We also play a key role in government and public sector institutes where non-IT experts can use the tool to perform inter and intra-agency data matching. We are recognized for our user-friendly interface and the ease with which companies can perform routine data preparation tasks.
While ease of use is a key benefit, there are several others if you invest in the right tool. Whether you’re a small business, an enterprise, or a government institute, self-service data preparation can help you:
Save on Time & Effort: You don’t have to waste a week to fix data before you can set it up for insights or analytics. You can extract insights from 100K records in under 45 minutes.
No Need for ETL or Data Modeling: Of course, no more complex extract, load and transform operations. A data preparation software can easily be used to clean massive amounts of data for cloud migration or CRM migration purposes. You don’t need ETL, nor data modeling for getting this done.
Easy for Business User: These tools are designed for everyone; business users, IT experts, data analysts, and anyone who understands their data and the outcome they want from it.
Flexible and Scalable: There is no limit to the amount of data you can profile. Greater ease of use makes it possible for users to connect to several different sources, combine and consolidate data on the fly.
Reduced Dependency on IT: Data preparation and data quality is not solely an IT responsibility so it doesn’t make sense to burden them to fix CRM data or marketing data when they are not familiar with the data. A business user understands their data far better than an IT user, therefore, it’s necessary that they take ownership of data quality and data prep.
A self-service data preparation tool is only good if it can empower users from non-technical backgrounds to work with their data. If the tool requires additional programming knowledge or a special language to operate, it’s not the right choice.
How Do You Choose the Right Self-Service Data Prep Tool?
There is a rise in self-service data prep vendors and making the right choice may be difficult. If you’re in the market to hunt for the right tool, make sure you check off the following conditions:
- It Must Have a Friendly UI: The whole point of a self-prep tool is to get data prep done in a quick amount of time. If the UI is not friendly and requires an understanding of relational database where users have to manually connect different data sources, then it’s probably not serving its purpose. The UI should be a drag and drop or a click and go.
- It Must Help the User Follow Data Quality Standards: Data that is complete, accurate, accessible, relevant, and serves the intended purpose is considered high quality. A data prep tool must allow the user to achieve these standards through functions of data cleansing, deduping, standardization, and validation. When choosing the tool, compare it with this list of standards. Do you think it will help you achieve this objective?
- It Must Have a Strong Data Matching Function: Data preparation is not just fixing superficial problems. It’s fixing deeply embedded problems like data duplication for which data matching is the only solution. To remove duplicates that are similar but not exact matches, you’ll need a tool that uses established fuzzy matching algorithms to dedupe complex data.
- It Must Allow for Multiple Data Integrations: While some companies can do without this feature if they primarily operate on CSV files, it will be a problem for companies with platforms like Hadoop or Salesforce. Your solution of choice should be able to allow integrations with different CRMs and data sources.
- It Must be Secure and Be Available as an On-Premises Solution: Some organizations, government institutes are not comfortable with a web version. They’d want an on-premises solution where they have complete control over their data. On-premises solutions are the most secure and can easily be used on your desktop or cloud server.
Self-service data prep tools have been around for quite some years, but it’s only now that the rise of AI, ML, BI, and other digital revolutions has made it become the center-stage of data management. If you’re truly looking to be data-driven, empower your teams with the right tool.
Want to know how Data Ladder can help you achieve this goal? Get in touch with one of our solution architects to know more.

