







Pre-processing
Ensure reliable data quality by performing data cleansing and standardization activities, such as fixing null, misspelled, or invalid data, as well as checking data accuracy and relevancy.

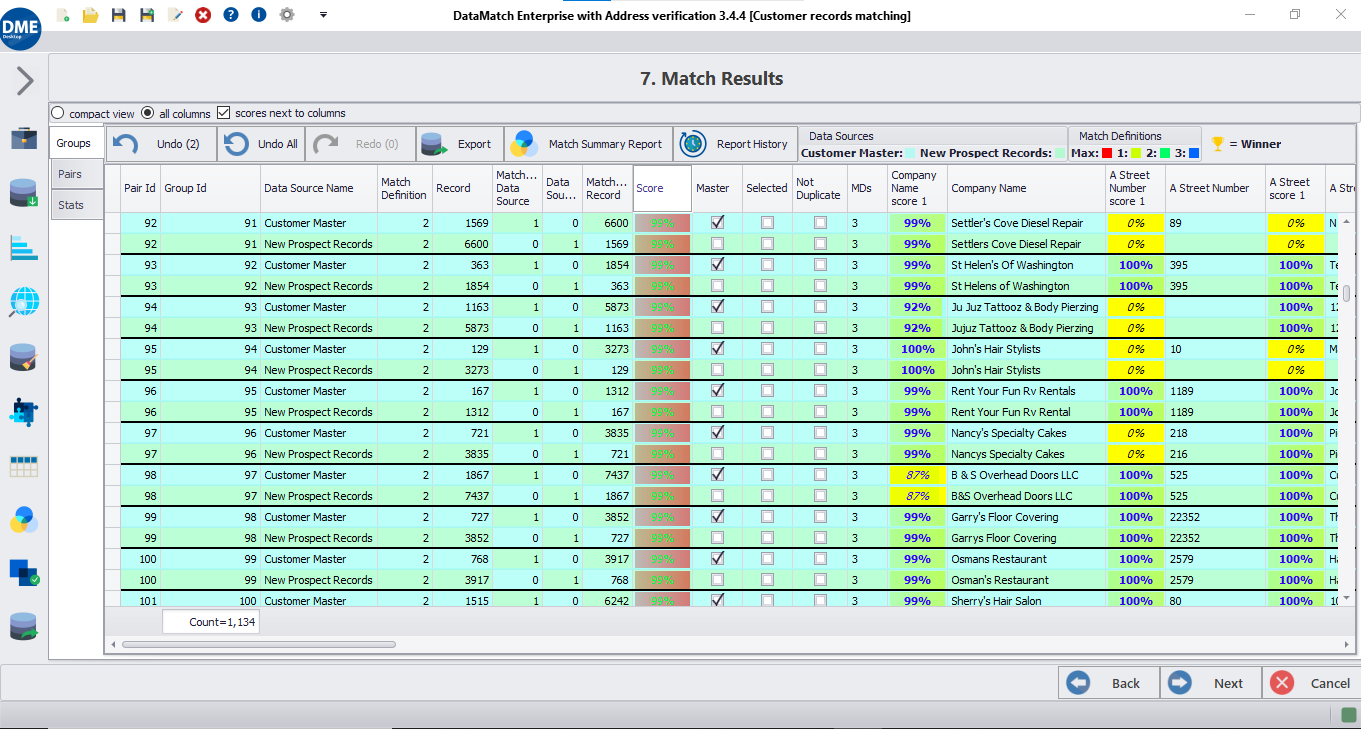
Field comparisons
Select a combination of fields and calculate the probability of their values being similar by implementing relevant field matching algorithms used for fuzzy, numeric, phonetic, or domain-specific comparisons.


Indexing/Blocking
Implement blocking or indexing techniques that limit the number of comparisons between records and only compares them if they have a high probability of belonging to the same entity.

Classification and evaluation
Classify records as a successful match or non-match based on the match scores calculated for field similarity, and evaluate results with varying levels and weights to attain maximum record linkage accuracy.