







Pré-traitement
Assurer une qualité de données fiable en effectuant des activités de nettoyage et de normalisation des données, telles que la correction des données nulles, mal orthographiées ou invalides, ainsi que la vérification de l'exactitude et de la pertinence des données.

Comparaisons sur le terrain
Sélectionnez une combinaison de champs et calculez la probabilité que leurs valeurs soient similaires en mettant en œuvre des algorithmes de correspondance de champs pertinents utilisés pour des comparaisons floues, numériques, phonétiques ou spécifiques à un domaine.


Indexation/Blocage
Mettez en œuvre des techniques de blocage ou d'indexation qui limitent le nombre de comparaisons entre les enregistrements et ne les comparent que s'ils ont une forte probabilité d'appartenir à la même entité.

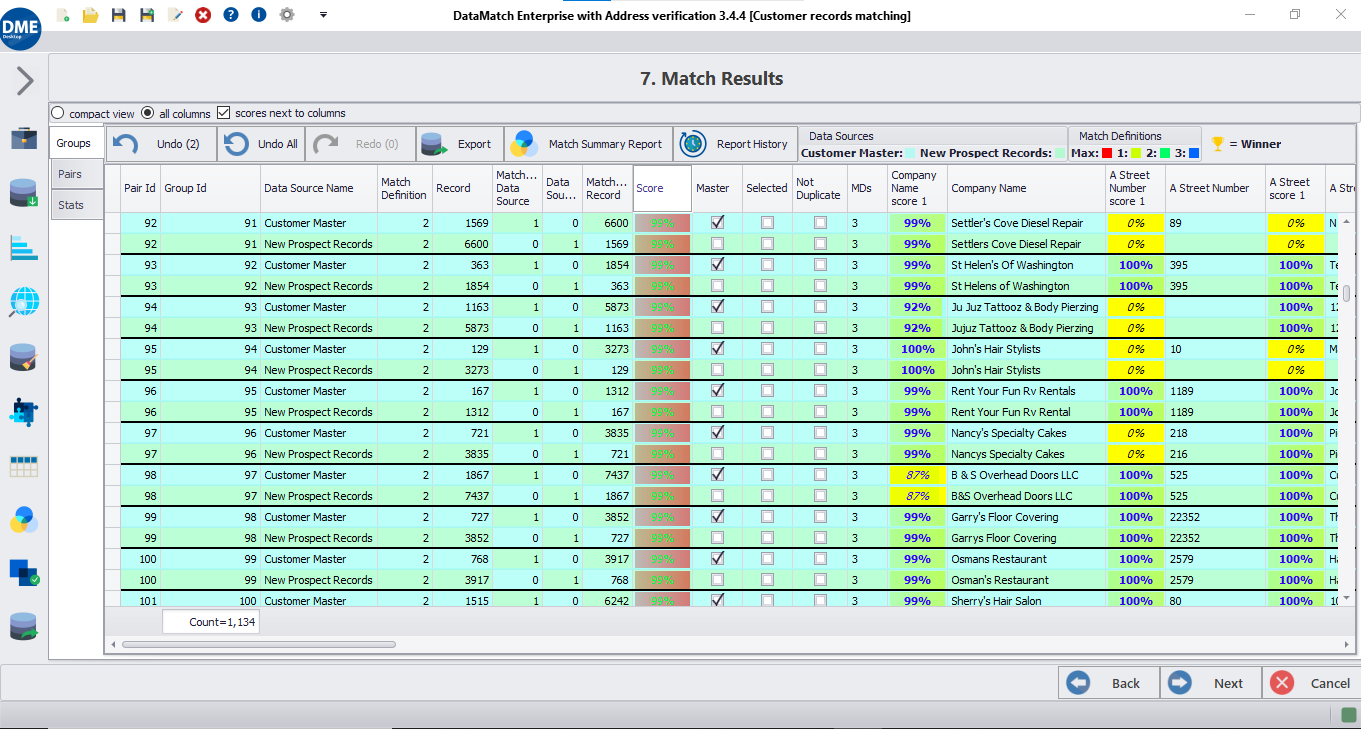
Classification et évaluation
Classez les enregistrements comme étant des correspondances réussies ou des non-correspondances sur la base des scores de correspondance calculés pour la similarité des champs, et évaluez les résultats avec des niveaux et des poids variables afin d'obtenir une précision maximale du couplage des enregistrements.