







Preprocesamiento
Garantizar una calidad de datos fiable realizando actividades de limpieza y normalización de datos, como la corrección de datos nulos, mal escritos o no válidos, así como la comprobación de la exactitud y relevancia de los datos.

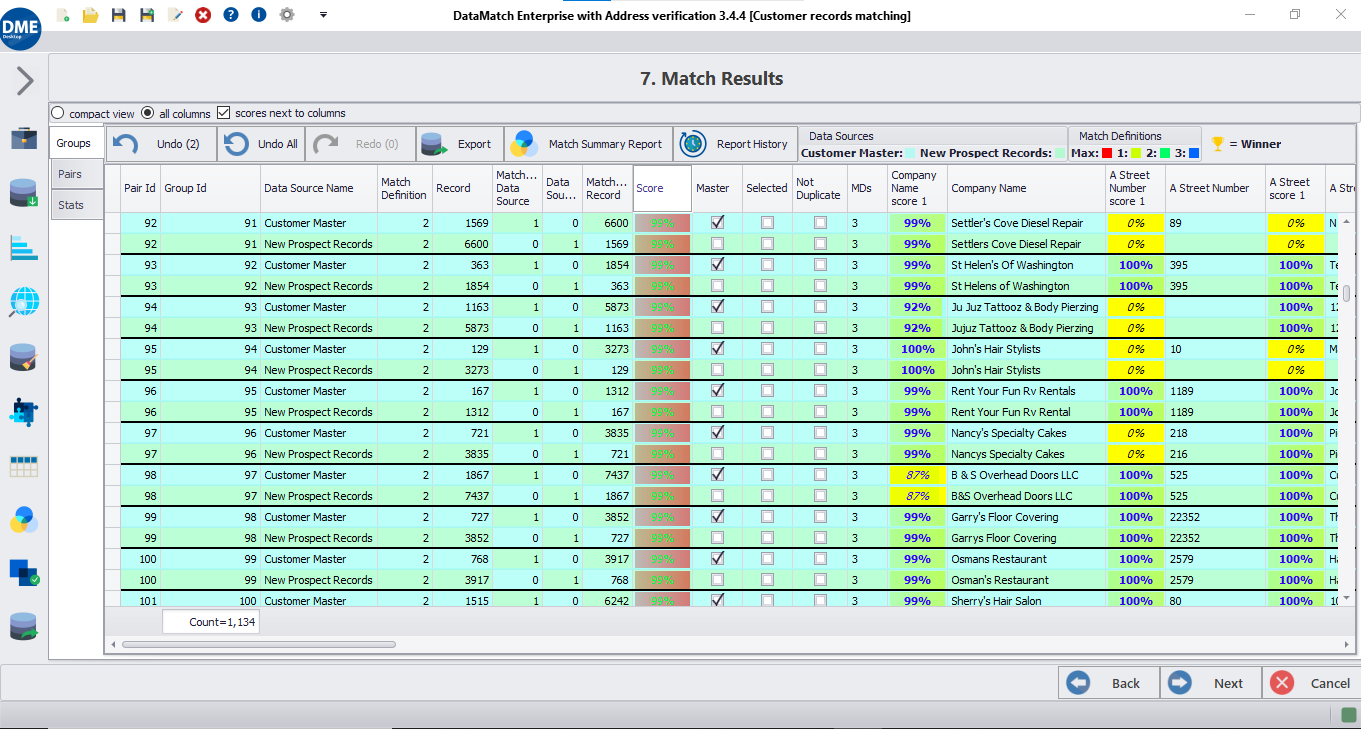
Comparaciones de campo
Seleccione una combinación de campos y calcule la probabilidad de que sus valores sean similares aplicando los algoritmos de coincidencia de campos pertinentes utilizados para las comparaciones difusas, numéricas, fonéticas o específicas del dominio.


Indexación/Bloqueo
Implementar técnicas de bloqueo o indexación que limiten el número de comparaciones entre los registros y sólo los comparen si tienen una alta probabilidad de pertenecer a la misma entidad.

Clasificación y evaluación
Clasificar los registros como coincidentes o no coincidentes en función de las puntuaciones de coincidencia calculadas para la similitud de los campos, y evaluar los resultados con distintos niveles y ponderaciones para alcanzar la máxima precisión de vinculación de los registros.