































Last Updated on June 4, 2026
Fuzzy matching identifies strings that likely represent the same entity, even if the formats, spellings, or fields don’t match exactly. It does this by measuring
how many small edits it would take to make them match.
This guide is for data practitioners, analysts, and engineers who need to clean, link, or deduplicate messy, inconsistent datasets. It walks you through how fuzzy matching works, which algorithms to use, and how to improve accuracy in real-world environments.
What is Fuzzy Matching?
Fuzzy matching is a data matching technique for identifying records that refer to the same entity even when the data does not match exactly. Instead of requiring identical values, it computes a similarity score between fields typically between 0 to 1 or 0 to 100. It then uses that score to decide whether two records should be linked, reviewed, or left separate.
This approach helps identify potential duplicates and near matches that exact matching would miss.
For example:

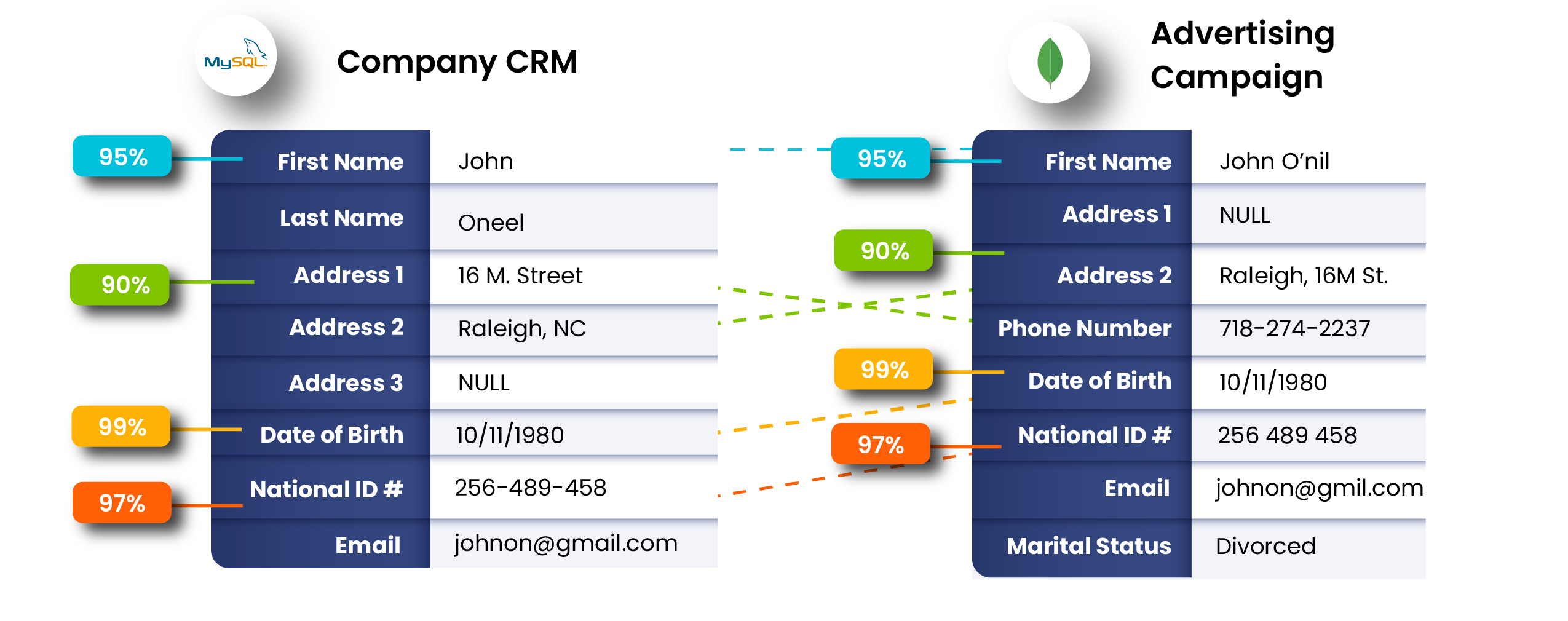
One system stores a record as “Clara A. Jenson,” and another lists “Clara Jenson.”
To a standard matching process, these might look unrelated. But with a fuzzy matching algorithm, they get a 0.92 similarity score, which indicates that both these records are very likely to be of the same person.
Once decisions are finalized, merge matched records into a master version. But never lose the trail.
Best practices:
- Maintain audit trails showing which records were merged, when, and under what rules.
- Generate match reports, including details like number of matches, false positives/negatives, and average score per field.
- Re-profile data periodically; data drift and new sources can shift performance.
Example metric:
Precision = 0.96, Recall = 0.89 after first run → indicates strong accuracy but room to capture more true matches by lowering review threshold slightly.
Why Fuzzy Matching Matters (and How It Solves Real-World Data Quality Problems)
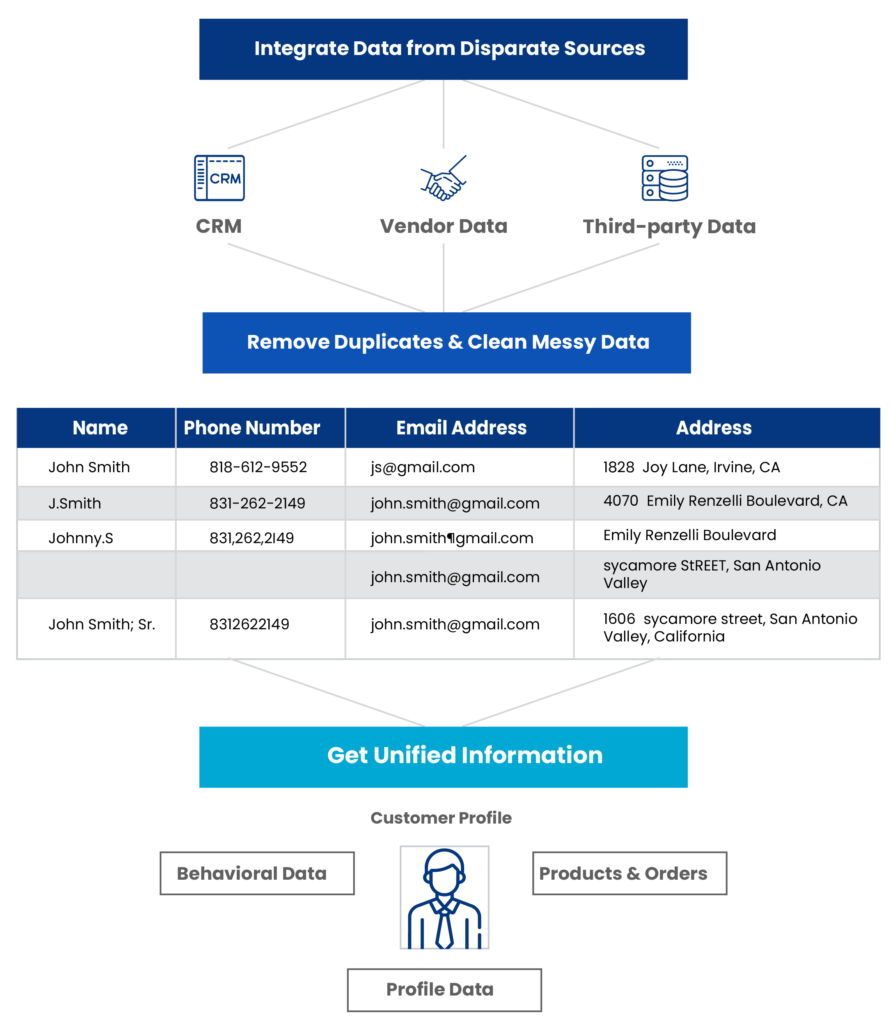
Modern organizations today collect data from hundreds of sources. And it rarely arrives perfectly clean. Typos, missing fields, extra spaces, format variations, and spelling inconsistencies make it nearly impossible to achieve a clean, unified view using exact-matching rules.
Fuzzy matching resolves these issues by identifying and linking imperfect records to create a single, accurate version of truth across systems. In doing so, it strengthens several core data operations, such as master data management, deduplication, record linkage, compliance reporting, and fraud detection.
Fuzzy matching doesn’t just clean an organization’s data; it builds (or restores) trust in it. Moreover, it ensures the information feeding analytics, BI, and AI systems is reliable and complete, thereby, also enhancing decision-making.
See fuzzy matching in action on your own data
DataMatch Enterprise lets you run fuzzy matching across your datasets without writing a single line of code. Upload your file and see match results in minutes.
Start a Free Trial
Example:
In 2003, a joint investigation by the Social Security Administration (SSA) and the Department of Transportation (DOT) revealed more than 3200 cases of pilots misusing their Social Security Numbers to claim disability benefits.
This case, though more than two decades old, is a great example of what fuzzy matching can do and why it matters in real-world business scenarios involving data. Without fuzzy logic, many risky or fraudulent patterns would remain unidentified.
What Data Errors Can Fuzzy Matching Detect and Fix?
Fuzzy matching is designed to catch errors that humans can easily spot but machines typically miss. It detects inconsistencies, typos, and variations that generally occur during data entry, migration, or integration.
Here are some common types of errors fuzzy algorithms can identify:
Type of Error
Example
Misspellings or typos
Micheal vs. Michael
Abbreviations and nicknames
St. vs. Street; Bob vs. Robert
Different date or address formats
12/05/2025 vs. 2025-05-12
123 Main Street, New York, NY 10001 vs. 123 Main St., NYC, NY 10001
Extra or missing spaces and punctuation
INV00123 vs. INV 00123
MaryAnn Smith vs. Mary Ann Smith
S.T. Johnson vs. ST Johnson
O’Connor vs. OConnor
Inconsistent casing
ACME INC vs. Acme Inc
Truncated or swapped fields
Smith John vs. John Smith
These are all small inconsistencies individually, but across hundreds of thousands or millions of records, they create massive duplication and quality issues.
Fuzzy matching helps detect, score, and link these records variations automatically, so teams can focus on insights and analyses, and not remain stuck with cleanup.
How Fuzzy Matching Works – The Logic Behind the Process
Think of fuzzy matching as a way of asking, “How likely is it that these two records refer to the same thing?”
It doesn’t answer yes/no. It gives you a number, called similarity score, and that number is what is used to decide if two records should be linked, reviewed, or ignored.
How Fuzzy Logic Works – A Quick Picture





Two records
Compare selected fields
Compute similarity for each field
Combine those into a similarity score
Interpret that score against thresholds (Auto-match/review/no-match)
How Field Scores Become a Single Match Score
Most fuzzy systems compute a score per field (name score, email score, address score) and then combine them.
A common formula is a weighted sum:
Final score = (name score x its weight) + (email score x its weight) + (address score x its weight)
Where w1 + w2 + w3 = 1
Weight/weighting is the importance assigned to each field. More important or discriminative fields carry higher weightage.
Example:
Name = 0.92 (w1 = 0.4), email = 0.60 (w2 = 0.4), address = 0.80 (w3 = 0.2)
Final score = 0.4*0.92 + 0.4*0.60 + 0.2*0.80 = 0.768
You then compare the final score to your thresholds to decide next steps.
Thresholds in fuzzy logic are numeric cutoffs that define action:
- Above threshold A → auto-merge.
- Between A and B → human review.
- Below B → ignore (no match).
Thresholds aren’t universal. They depend on use case.
Practical Note:
Some systems use more complex combination logic (rule gates like “email must match or two other fields must match”), but the weighted average is the most common and easiest to reason about.
Types of Similarity (what you’re actually measuring)
There are different algorithms used in fuzzy matching (we’ll discuss them in the next section). But here’s what the various approaches actually measure:
- Character similarity – how many edits or swaps and where they appear. Good for typos.
- Token overlap – how many tokens (meaningful parts or chunks a field is split into through tokenization) two values share, regardless of order. Good for addresses and long names.
- Phonetic similarity – how two words sound when spoken. Useful for names that are spelled differently but sound the same.
- Semantic similarity – whether two pieces of text mean the same thing. Useful for long descriptions or product titles.
Each method produces a number you can convert to a 0-1 scale for later combination.
Fuzzy Scoring Examples on a 0-1 Scale (Quick Reference)
Similarity range
What it typically means
Example
0.95–1.00
Near certain match
“Acme Corporation” vs “Acme Corp”
0.80–0.95
Strong match, likely same
“Jon Smith” vs “John Smith”
0.60–0.80
Possible match, needs review
“Roberto” vs “Robert”
0.40–0.60
Weak match, usually ignore
Different people, same city
< 0.40
No meaningful similarity
“Apple Inc.” vs “John Doe”
These similarity bands are illustrative; tune for your data.
Composite and Conditional Logic (Real-World Rules)
In practice, you’ll usually see the fuzzy logic rules implemented in combinations, such as:
- If email similarity > 0.95 → immediate match (email ID is a high trust identifier).
- Else is name > 0.85 and address > 0.75 → review.
- Else → no match.
These conditional rules reduce false positives (when unrelated records are linked) and let you embed business logic alongside similarity scores.
Common Fuzzy Matching Mistakes to Avoid

Normalization: cleaning and standardizing text before comparison. Normalization is especially critical when merging data from multiple sources, where format inconsistencies are the leading cause of false negatives
Typical steps: trim whitespace, lowercasing, remove punctuation, expand or standardize abbreviations (St → Street), normalize phone formats, strip salutations.
Why it matters: similar-looking values can score very differently if not normalized first.
- Skipping normalization: yields low scores for otherwise identical data.
- Overweighting noisy fields: a frequently mistypes field should not dominate the final score.
- Fixed thresholds across datasets: thresholds must reflect data quality and business risk.
- Ignoring blocking/indexing: doing full pairwise comparisons on millions of rows is impractical (more on it in the workflow section).
Fuzzy matching involves computing similarity scores between values (after normalization and tokenization), combining weighted field scores into a single match score, and using context-specific thresholds to decide whether records should be merged, reviewed, or left separate.
Common Fuzzy Matching Algorithms, Libraries, and Tools – and When to Use Each
In the previous section, we discussed how fuzzy logic calculates similarity scores. Let’s now dig a little deeper to understand how those scores are actually produced.
Fuzzy Matching Algorithms
Fuzzy matching relies on different types of algorithms. Each type has its strengths and best-fit scenarios.
Here are the five categories they can be grouped into based on how they work:
A. Character-Based Algorithms
Character-based fuzzy matching algorithms, as the name tells, focus on individual characters. They are useful for catching typos, transpositions, and small edits in short strings like names or IDs, and are widely used in healthcare, finance, and education sectors.
The most common character-based fuzzy algorithms include:
- Levenshtein Distance: Counts the number of edits (insertions, deletions, or substitutions) required to turn one word into another. These edits are measured in distance (often called the edit distance). It’s ideal for detecting simple typos in names, IDs, or short text fields.
- Jaro-Winkler: Gives more weightage to similarities at the beginning of strings. It handles transpositions and minor variations better than Levenshtein Distance and is best for people names and short identifiers.
B. Token-Based Algorithms
These fuzzy matching algorithms look at whole words or tokens. They’re helpful when datasets have order or spacing variations, which make them popular in retail, logistics, and e-commerce industries.
Popular token-based fuzzy algorithms include:
- Jaccard Similarity: Compares the overlap between two sets of tokens. It works best for addresses, company names, or product titles.
- Cosine Similarity: Turns text into vectors and measures the angle between them; closer vectors = more similar. It’s best for longer text fields where context matters slightly more than exact word overlap.
C. Phonetic Algorithms
Phonetic data matching approaches compare how words sound when spoken rather than how they’re spelled. They are commonly used by healthcare and government organizations, and HR teams.
Common phonetic algorithms include:
- Soundex: Converts words into four-character phonetic codes based on how they sound. It works best for name matching.
- Metaphone/Double Metaphone: Improved versions of Soundex for handling languages other than English and complex sounds. They are the best choice for names with multiple spellings.
D. Semantic and Machine-Learning-Based Algorithms
These algorithms move beyond spelling to measure meaning. They’re more resource-intensive but powerful for unstructured text, which makes them highly useful for retail, e-commerce, research, and marketing analytics.
Some of the most common ones include:
- TF-IDF (Term Frequency-Inverse Document Frequency): Represents text as weighted vectors based on how important words are in a dataset. It’s best for comparing longer fields like product descriptions of address lines.
- Embeddings/ Vector Models (Word2Vec, BERT, Sentences Transformers): Advanced data matching algorithms that use AI to capture contextual similarities. They are the best choice for semantic or multilingual matching where meaning matters more than spelling.
E. Probabilistic Algorithms
Probabilistic algorithms assign a probability that two records represent the same entity, based on multiple fields and historical error rates. They are especially useful when data is inconsistent, incomplete, or partially matching, and are widely used by government agencies (for census and registries), healthcare organizations, and finance companies.
The most commonly used probabilistic algorithm is:
- Fellegi-Sunter: Assigns match and non-match probabilities to each field and combines them into an overall score. It’s best for large, messy datasets like census, healthcare, or financial records.
F. Hybrid Methods
Real-world data doesn’t often fit one pattern. Hybrid approaches to data matching combine various techniques for better accuracy. They are quite popular in the e-commerce and logistics industries.
Some commonly used hybrid data matching approaches include:
- Monge-Elkan: Compares each token in one string to the best-matching token in another, and then average the results.
- SoftTF-IDF: Merges TF-IDF weighting with character similarity for potential token matches. It’s best for complex records like full names of addresses that mix text, numbers, and abbreviations.
Which Fuzzy Matching Algorithm Should You Choose?
Choosing the right fuzzy matching algorithm depends on what you’re matching, not on which algorithm is most popular. The decision tree below walks through the most common data types — personal names, business names, addresses, and long text — and shows which algorithm produces the highest accuracy for each. Combine algorithms when data is mixed.

If you’re matching personal names with phonetic variations, combine NYSIIS for blocking with Jaro-Winkler for scoring. For business names with heavy punctuation and legal suffixes, normalize first, then apply Levenshtein with token-based methods. For addresses, standardize using a postal validation service before applying Levenshtein. For long text fields like product descriptions, use TF-IDF or embedding-based similarity. For mixed-field records, apply a hybrid approach with field weighting.
Common Fuzzy Matching Libraries and Tools
Once you figure out which fuzzy algorithms fit your data, the next decision you have to make is how to implement them. Depending on your goals, data size, and technical resources, you can use open-source libraries for experimentation, spreadsheet-based method, or enterprise-grade fuzzy matching software for production-scale matching.
Popular Open-Source Libraries
For teams exploring fuzzy matching techniques or working with smaller datasets, Python offers several powerful open-source options:
- FuzzyWuzzy – One of the earliest and most popular libraries for string matching, built on Levenshtein distance. It’s easy to use and great for prototyping or quick deduplication tasks, but slower on large datasets.
- RapidFuzz – A modern, faster alternative to FuzzyWuzzy. It supports partial and token-based matching and is better optimized for production environments.
- PolyFuzz – Focused on text embeddings and vector-based similarity, it works well for matching phrases and longer text fields.
- FuzzyPandas – Integrates fuzzy matching directly into Pandas workflows, letting data analysts perform fuzzy joins and record linkage without leaving the DataFrame environment.
- RecordLinkage Toolkit/ Dedupe.io – Extend beyond algorithms to full record-linkage pipelines.
These libraries are excellent for data scientists, engineers, and analysts who need flexible, script-based control or want to test and fine-tune matching logic in-house.
Enterprise Tools vs. Spreadsheets and Scripts
While open-source tools work well for small-scale or exploratory projects, they start to show limitations when data grows or compliance standards tighten. Managing fuzzy matching across millions of records, multiple databases, and enterprise workflows requires more than scripts or spreadsheets.
Enterprise platforms such as DataMatch Enterprise (DME) are designed for this scale. DME combines deterministic, fuzzy, and phonetic matching methods in one interface, backed by high-performance algorithms that can process millions of records quickly and accurately. It also provides full transparency, matching configuration controls, and seamless integration into your existing tech stack; requirements that scripting environments rarely address.
In contrast, spreadsheet-based methods or ad hoc scripts often lack transparency, are prone to human error, and can’t scale beyond small datasets.
Enterprise Tools vs. Spreadsheets and Scripts
Use Case
Recommended Approach
Prototyping or working with small datasets
FuzzyWuzzy, RapidFuzz
Operational workloads with medium data volumes
PolyFuzz or FuzzyPandas integrations
Large-scale or compliance-driven environments
DataMatch Enterprise
Business users needing no-code matching
DataMatch Enterprise
In short, open-source libraries are great for experimentation and learning. But as datasets grow into millions of records, or when accuracy, scalability, and transparency become priorities, purpose-built enterprise solutions like DataMatch Enterprise deliver unmatched reliability and performance.
Fuzzy matching algorithms fall into five families — character-based, token-based, phonetic, semantic, and hybrid — each measuring similarity differently.
Choose simpler algorithms like Levenshtein for typos, phonetic methods for names, or vector models for text meaning.
For implementation, use open-source tools for small projects and enterprise platforms such as DataMatch Enterprise for large, governed workloads.
Fuzzy Matching Workflow: End-to-End Process for Accurate Results
Fuzzy matching isn’t just about running an algorithm.
To get accurate, repeatable results, you need a structured workflow; one that starts with understanding your data and ends with governed, auditable merges.
Here’s what an enterprise-ready fuzzy matching process looks like from start to finish.
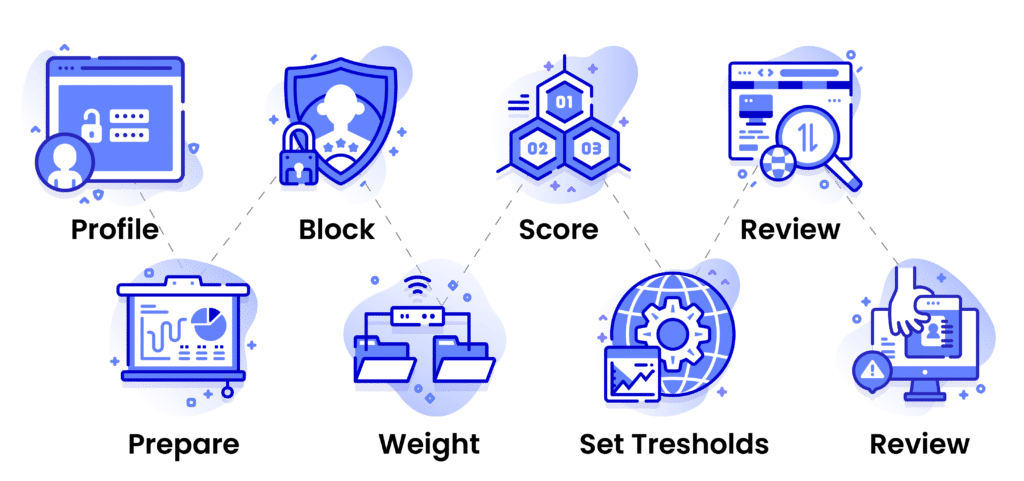
Step 1: Data Profiling to Understand Your Data Sources
Before matching, gather all relevant datasets and profile your data.
You need to know which fields are complete, how many duplicates exist, where nulls hide, and what patterns or outliers you’re dealing with.
Profiling helps answer:
- Which fields carry unique information (email, SSN, phone)?
- Which fields are noisy or inconsistent (name, address)?
- What kinds of errors dominate; typos, casing, abbreviations, format mismatches?
Practical tip:
Use summary stats and frequency charts, such as, if “First Name” has 10 percent blanks or “City” appears in multiple languages, flag that early.
Profiling sets the foundation for every tuning decision that follows.
Step 2: Cleanse and Standardize Your Data
Even the best algorithm can’t fix messy input. Normalize and standardize your records before matching so you’re comparing like with like.
Typical data preparation steps include:
- Format Standardization: Unify date styles (YYYY-MM-DD), phone patterns, postal codes.
- Text Cleaning: Remove punctuation, extra spaces, and non-printable characters.
- Case Normalization: Convert all text to upper or lower case.
- Abbreviation Expansion: “St.” → “Street”, “Ave” → “Avenue”.
- Accent/Diacritic Removal: “José” → “Jose”.
Example:
“123 Main St., Apt 4” and “123 Main Street Apt #4” become much easier to compare once normalized.
Why it matters:
Data preparation eliminates superficial differences in records, so fuzzy algorithms can focus on the meaningful ones.
Step 3: Block and Index Records
Without blocking, fuzzy matching algorithms compare every record with every other, leading to millions of comparisons that cripple performance.
Blocking (also called indexing or candidate generation) limits comparisons to likely matches.
Common Blocking and Indexing techniques:
- Sorted Neighborhood: Sort by key fields (e.g., last name + ZIP) and compare within a sliding window.
- Key Blocking: Use simple keys like Soundex codes or first-letter + ZIP.
- Canopy Clustering / Locality-Sensitive Hashing (LSH): Advanced methods that group records using approximate similarity itself.
Example:
Block = first 2 letters of last name + ZIP
“SM-10001” block will hold Smith, Smyth, Smid, not unrelated names.
That reduces a million-record dataset from ~1012 comparisons to a manageable few million.
Step 4: Select Fields and Assign Weights
Every dataset has fields that signal identity more strongly than others.
For example, a phone number is more reliable identifier than a ZIP code; an email address beats a nickname.
Assign weights to each filed in your dataset based on how discriminative it is. Here are some guidelines to get started:
Field
Typical Weight
Notes
0.4 – 0.5
High uniqueness
Name
0.3
Frequent but variable
Address
0.2
Moderate reliability
ZIP / City
0.1
Supportive context
Combine field-level similarities using a weighted average or business rules.
Example Rule:
Match if (name > 0.85 AND address > 0.75) OR (email > 0.9).
Step 5: Score Similarity
This is the stage where you apply the selected algorithms.
When you do that, each record pair inside a block is scored per field, such as, name 0.94, email 0.99, address 0.81, then combines into an overall similarity score.
Practical notes:
- Choose algorithm per field; Jaro-Winkler for names, TF-IDF for addresses, phonetic for names that vary by sound.
- Log the distribution of scores; a clear bimodal pattern (high cluster vs low cluster) helps set thresholds later.
- Keep results reproducible; store algorithm version, parameters, and date.
Step 6: Classify by Threshold
This is where similarity scores are converted into actions.
Here’s what a typical setup looks like:
Score Range
Action
Description
≥ 0.90
Auto-match
Confident duplicates; merge directly
0.75 – 0.89
Manual review
Possible matches; send to steward queue
< 0.75
No match
Distinct records
Tune thresholds using validation data.
High-risk domains, such as finance and healthcare, favor higher thresholds to avoid false mergers, while marketing or customer data may use lower cutoffs to catch more potential duplicates.
Step 7: Validate with Human Review
Even the smartest data matching models can’t resolve every ambiguity.
To improve accuracy of results, introduce a manual-review queue for borderline cases.
A good steward interface shows both records side-by-side, highlights differences, and lets reviewers confirm, reject, or adjust matches.
Why this step matters:
- Protects against irreversible merges.
- Provides labeled feedback that can retrain models or refine rules.
- Builds organizational trust in automated matching.
Step 8: Merge, Audit, and Monitor
Once decisions are finalized, merge matched records into a master version. But never lose the trail.
Best practices:
- Maintain audit trails showing which records were merged, when, and under what rules.
- Generate match reports, including details like number of matches, false positives/negatives, and average score per field.
- Re-profile data periodically; data drift and new sources can shift performance.
Example metric:
Precision = 0.96, Recall = 0.89 after first run → indicates strong accuracy but room to capture more true matches by lowering review threshold slightly.
For a complete walkthrough of consolidation after matching, see our guide on merging data from multiple sources.
How to Evaluate Fuzzy Match Accuracy
Once your fuzzy matching system is in place, the next logical step is to measure how well it’s performing.
However, evaluating accuracy of your fuzzy matching systems isn’t just about looking at how many matches it found; it’s about understanding how many of those matches were correct, and how many true matches might have been missed.
That’s where you need the knowledge of evaluation metrics.
Precision, Recall, and F1 Score – The Core Trio to Measure Fuzzy Matching Performance
Precision, Recall, and the F1 Score are three key metrics used to quantify fuzzy match quality.
They tell you how accurate, complete, and balanced your matching results are.
Precision: How Many of Your Matches Are Right
Precision measures how many of the records your system labeled as “matches” are actually correct.
Formula:
Precision = True Positives ÷ (True Positives + False Positives)
Example:
If your system identified 100 matches and 95 are correct, precision is 0.95 (or 95%).
What it tells you:
A high precision score means your system isn’t falsely linking unrelated records. It’s being strict and careful.
Recall: How Many True Matches You Actually Found
Recall looks at completeness. It measures how many of the actual true matches in your dataset your system successfully identified.
Formula:
Recall = True Positives ÷ (True Positives + False Negatives)
Example:
If there were 120 real matches in the dataset and your system found 95, recall is 0.79 (or 79%).
What it tells you:
A high recall score means your system is finding most of the true matches. Even if a few false ones sneak in, your results are mostly accurate.
F1 Score: Finding the Balance
F1 score combines precision and recall scores into a single metric to offer a mean value that balances accuracy and completeness.
An F1 score of 0.92 indicates an optimal balance between false positives (incorrect matches) and false negatives (missed matches).
Formula:
F1 = 2 × (Precision × Recall) ÷ (Precision + Recall)
Example:
Precision = 0.95, Recall = 0.79 → F1 = 0.86.
Precision vs. Recall vs. F1 Score
Metric
Definition
Formula
Example
Interpretation
Precision
How many of the matches found were correct.
TP ÷ (TP + FP)
95 correct matches out of 100 found = 0.95
Accuracy of detected matches.
Recall
How many of the true matches were actually found.
TP ÷ (TP + FN)
95 found out of 120 total = 0.79
Coverage or completeness.
F1 Score
Balance between precision and recall.
2 × (P × R) ÷ (P + R)
0.95 and 0.79 → 0.86
Overall matching quality.
Precision
How many of the matches found were correct.
TP ÷ (TP + FP)
95 correct matches out of 100 found = 0.95
Accuracy of detected matches.
Together, these metrics reveal whether your matching configuration leans more toward strictness (higher precision, lower recall) or flexibility (higher recall, lower precision).
How to Find Your Precision and Recall Balance?
Balancing these scores correctly depends on your business goals.
- Identify Your Goals:
Some use cases demand higher recall score while others may demand high precision. Therefore, the first step is to determine what exactly are you going to use fuzzy matching for and what it demands.
For example:
Scenario
Goal
Metric Priority
Explanation
Fraud detection
Catch all possible duplicates.
High Recall
You’d rather review extra records than miss a potential match.
Customer master data detection
Merge only confirmed duplicates.
High Precision
False merges can damage data integrity and trust.
Marketing segmentation
Maximize coverage.
Moderate Precision + High Recall
Missing a few false positives is acceptable if it means reaching more valid contacts.
- Tune Thresholds According to Your Goals
Adjusting similarity thresholds directly impacts these metrics.
Scenario
Goal
Metric Priority
Explanation
Lower (Ienient)
↓
Lower
Higher
↓
When catching all possible duplicates is critical.
Higher (Strict)
Higher
↓
↓
Lower
When false positives must be minimized.
Adaptative
Balanced
Balanced
When requirements vary by field (the metrics automatically adjust by field or confidence level).
Example:
If your system auto-links records above 0.90, flags 0.75-0.89 for review, and discards the rest, you can fine-tune those numbers based on how your precision and recall shift in reports.
How to Measure Fuzzy Matching Accuracy?
To measure fuzzy matching accuracy, you must:
Track Precision, Recall, and F1 Score. Precision shows how many identified matches were correct, recall shows how many true matches were found, and F1 combines both into one score.
Tune thresholds based on your goal: Higher recall for discovery, higher precision for data quality.
Review performance regularly: Matching accuracy changes as data grows and evolves, so make sure to keep a track.
How to Improve Fuzzy Matching Accuracy
Even the most advanced fuzzy matching systems can produce incorrect, incomplete, or misleading results if not configured correctly.
Improving accuracy isn’t about adding complexity; it’s about refining the process so your system makes smarter comparisons with less noise.
Below are practical ways to boost accuracy and consistency of your setup across data types, sources, and use cases:
1. Start with Clean, Standardized Data
Accuracy begins long before algorithms enter the picture.
If your input data is inconsistent, every downstream step will suffer.
To improve the quality of your input data, focus on preparation steps such as:
- Consistent formatting: Standardize casing, abbreviations, date formats, and punctuation.
- Normalization: Remove extra spaces, fix abbreviations, (like “St.” → “Street”), and standardize phone and postal code patterns.
- Handling nulls and duplicates: Fill or remove blanks; validate key identifiers before matching.
- Field unification: Make sure similar data lives in the same field. For example, city names aren’t mixed into address lines.
Why it matters:
Clean data helps algorithms focus on meaningful similarity, not formatting differences.
2. Minimize False Positives and Negatives
A well-tuned fuzzy matching system strikes a healthy balance between precision and recall.
- False positives happen when unrelated records are incorrectly linked. For example, when two different people sharing a similar name are considered one.
- False negatives occur when genuine matches are missed due to overly strict thresholds or poor data quality.
To minimize false positives and negatives:
- Adjust thresholds according to data sensitivity. For example, a marketing dataset may allow 80% similarity, while financial records often require 95%+.
- Segment by data domain. Apply separate thresholds for customer names vs. addresses vs. products.
- Manually review borderline matches. Records scoring near the threshold (e.g., 0.78 – 0.85) are ideal candidates for human validation.
- Use feedback loops. Feed reviewer confirmations or rejections back into the model to refine rules and thresholds and improve performance over time.
3. Combine Multiple Fields
Matching on a single field like Name or Address rarely yields reliable results.
Combining fields adds context and strengthens match confidence.
For instance, matching on Name + Email or Company + Domain can confirm identity more reliability than either field alone.
4. Apply Field Weighting and Rule-Based Filters
As mentioned earlier as well, not all fields carry the same importance.
An email address is far more discriminative than a ZIP code, and a full name most often (if not always) outweighs a partial ID.
By assigning weights, you tell the system which fields to trust more.
Rule-based filters go one step further by adding logic or rules like:
- Ignore matches across different countries.
- Match only when both Phone Number and Last Name are similar.
- Reject matches if ZIP codes conflict.
- Only accept if Date of Birth matches within ±1 day.
- Exclude records with missing identifiers.
These filters narrow ambiguity and help your matching logic reflect business reality instead of pure algorithmic probability.
5. Continuously Optimize: Don’t “Set and Forget”
Matching accuracy isn’t static. It shifts as data changes, formats drift, systems evolve, and new sources introduce new types of noise, all of which affect how well your matching rules perform.
Building a feedback loop ensures your fuzzy engine learns and improves and the process is continuously optimized over time.
Best practices:
- Monitor tends: Track precision and recall over time, not just immediately after deployment.
- Validate with labeled samples: Use gold-standard datasets to check if your tuning still holds.
- Analyze borderline matches: They help identify recurring error patterns.
- Iterate thresholds and weights: Small changes can significantly improve balance.
- Review algorithm choices: As unstructured or multilingual data grows, embedding-based or hybrid methods may outperform older distance-based algorithms.
How to Improve Fuzzy Matching accuracy?
- Clean and standardize data before matching.
- Adjust thresholds to balance false positives and negatives.
- Combine multiple fields for stronger context.
- Apply field weighting and domain rules for realism.
- Build continuous feedback loops to optimize the process.
Real-world Result
In one enterprise deployment, fuzzy matching (conducted using DataMatch Enterprise) improved match rate by 24% and reduced time by 66.67% without requiring additional development resources.
This demonstrates how applying fuzzy matching correctly, with systematic tuning and field optimization, can deliver measurable improvements in both efficiency and accuracy.
Fuzzy Matching Use Cases and Examples
Fuzzy matching is a versatile technique used across sectors to detect duplicates, reconcile data inconsistencies, and ensure accurate records. When fuzzy matching is applied across multiple systems to build a unified view of a customer or entity, this process is called entity resolution.
Here’s a quick overview of how different industries leverage fuzzy matching in real-world scenarios to build reliable single sources of truth:
- Healthcare: Patient record linkage.
- Finance: KYC compliance, duplicate customer record detection, fraud detection and prevention.
- Retail: Product catalog reconciliation, inventory management, and reporting.
- Government: Citizen data unification, including tax records, social security information, and voter registration details.
- Education: Student enrollment validation.
- Telecommunications: Customer data consolidation to improve billing accuracy and customer service.
- E-commerce: Product and customer data accuracy, enhanced product recommendations.
- Logistics & Transportation: Shipment and supplier management.
- Real Estate: Property data standardization, consolidate property listings.
Make Fuzzy Matching Simple and Scalable with DataMatch Enterprise
DME turns what used to be months-long, code-heavy projects into a visual, repeatable workflow for data teams and business users alike.
You can configure, test, and deploy fuzzy matching rules without writing scripts, all while maintaining enterprise-grade security, auditability, and performance.
Explore how DataMatch Enterprise simplifies fuzzy matching at scale.
Real-World Case Study: How Zurich Insurance Improved Match Accuracy and Efficiency at Scale with DME
In a real-world deployment, a global insurance provider, Zurich Insurance, used DataMatch Enterprise’s fuzzy matching and data cleansing features to reconcile 170,000+ vendor records.
The project resulted in a cleaner, more reliable vendor directory and streamlined payments. It also enabled accurate confidential reporting, previously hindered by inconsistent and duplicate entries.
According to Andy Green, Statistic Manager at Zurich:
“Now, DataMatch Enterprise has become a main staple in my suite of tools.”
See how your organization can simplify fuzzy matching at scale:
The Sum Up
Data rarely arrives clean, complete, or consistent, and that’s exactly why fuzzy matching matters.
When implemented correctly, fuzzy matching doesn’t just clean data, it strengthens every system and decision that depends on that data.
It bridges the gap between imperfect records and accurate, unified data. By finding connections that exact matching can’t, it helps organizations trust their data, improve analytics, and make confident decisions.
Whether you’re merging customer records, reconciling supplier information, or unifying patient files, the principles remain the same:
Clean first, match smartly, monitor continuously, and refine with feedback.
And when the time comes to scale this across millions of records or multiple systems, DataMatch Enterprise delivers the automation, transparency, and accuracy needed to make it practical, and measurable, at enterprise level.
Ready to run fuzzy matching on your data?
DataMatch Enterprise is used by data teams across finance, healthcare, retail, and government to match, deduplicate, and link records at scale — with full audit trails and no-code configuration.
Start Your Free TrialFrequently Asked Questions (FAQs)
1. What is fuzzy data matching used for?
Fuzzy data matching is used to find records that refer to the same entity even when the data isn’t identical. It helps identify duplicates, link records across systems, and correct inconsistencies caused by typos, abbreviations, or different formatting.
2. Which algorithms does fuzzy matching use?
Fuzzy matching relies on multiple algorithms to measure similarity between text strings.
Common fuzzyalgorithms include Levenshtein Distance, Jaro-Winkler, Soundex, N-Gram, and TF-IDF.
- Levenshtein counts character edits.
- Jaro-Winkler gives more weight to prefix similarity (great for names).
- Soundex and Metaphone match based on pronunciation.
- Fellegi-Sunter calculates match probabilities across multiple fields; best for large, messy datasets.
- TF-IDF and embeddings compare meaning or context in longer text.
3. How is fuzzy matching different from deterministic & probabilistic matching?
Deterministic (or exact) matching requires exact agreement on key identifiers, while probabilistic matching uses statistical models and confidence scoring to predict matches.
Fuzzy matching sits in between. It’s less strict than deterministic matching but simpler than probabilistic matching, making it ideal for messy or inconsistent data.
4. How accurate is fuzzy matching?
The accuracy of fuzzy matching depends on data quality, algorithm choice, and threshold settings.
A well-tuned fuzzy matching workflow typically achieves 90–98% accuracy for structured data when combined with standardization, field weighting, and human review.
5. Which industries benefit from fuzzy matching?
Fuzzy matching is widely used in healthcare, finance, retail, government, education, and logistics to unify records, reduce duplication, and improve decision-making.
Overall, any organization that manages large or inconsistent datasets can benefit from it.
6. Is fuzzy matching reliable?
Yes, fuzzy matching is reliable when combined with proper data standardization, algorithm selection, and human validation. Enterprise solutions like DataMatch Enterprise offer hybrid matching and rule-based filtering to minimize false matches and ensure accuracy at scale.
7. Why choose DataMatch Enterprise for fuzzy matching?
DataMatch Enterprise by Data Ladder combines deterministic, fuzzy, and phonetic algorithms in a single, scalable platform. It includes built-in data cleansing, profiling, threshold tuning, and merge and survivorship features that enable up to 98% match accuracy with full transparency and control.
8. Can I combine multiple fuzzy matching algorithms?
Yes, combining algorithms typically improves accuracy. Common patterns include using phonetic algorithms (Soundex or NYSIIS) for blocking, then applying character-based algorithms (Jaro-Winkler or Levenshtein) for scoring within blocks. Enterprise tools like DataMatch Enterprise apply this hybrid approach automatically.
9. When should I use Soundex vs NYSIIS?
Use NYSIIS over Soundex when accuracy matters more than legacy compatibility. NYSIIS handles a wider range of English name variations and typically outperforms Soundex by 10–15 percentage points in F1 score. Soundex remains useful only when integrating with older systems that already use Soundex codes.

