





























Last Updated on April 14, 2022
Daten aus der realen Welt werden immer unvollständige oder fehlende Werte enthalten, insbesondere wenn sie aus verschiedenen Quellen stammen. Unvollständige Daten können zu fehlerhaften Berichten und verzerrten Schlussfolgerungen im Forschungsbereich führen. Für Unternehmen bedeutet dies, dass sie nur unzureichende Einblicke in ihre Kunden erhalten, ungenaue Geschäftsinformationen erhalten und ihre Rentabilität verlieren.
Die Vollständigkeit der Daten ist daher eine wesentliche Komponente des Datenqualitätsrahmens und steht in engem Zusammenhang mit der Gültigkeit und der Genauigkeit. Wenn die Daten fehlen, können die Informationen nicht validiert werden, und wenn sie nicht validiert sind, können sie nicht als korrekt angesehen werden.
Unabhängig davon, ob Sie als Forscher mit Umfragedaten, als Geschäftsmann mit CRM-Daten oder als IT-Experte mit Organisationsdaten arbeiten, müssen Sie in der Lage sein, fehlende und unvollständige Datenwerte zu erkennen, um die nächsten Schritte zu bestimmen.
In diesem kurzen Beitrag gehe ich auf die wichtigsten Konzepte ein:
- Was bedeutet es, wenn Daten fehlen?
- Arten von fehlenden Daten
- Wie erkennen Sie fehlende Daten?
- Die Bedeutung der Vollständigkeit der Daten
- Arten der Datenvollständigkeit
- Wie man Vollständigkeit misst
- Wie DataMatch Enterprise bei der Ermittlung fehlender Daten effektiver ist als Python
Was bedeutet es, wenn Daten fehlen?
Fehlende Daten beziehen sich auf Zeilen oder Spalten, die keine, leere oder unvollständige Werte aufweisen.
Beispiele:
- Fehlende Nachnamen, Telefonnummern, E-Mail-Adressen in einem CRM
- Fehlendes Alter und fehlende Beschäftigungsjahre in einem Beobachtungsdatensatz
- Fehlende Einkommensangaben von Arbeitnehmern in Organisationsdaten
Die Ursachen für fehlende Daten sind vielfältig, lassen sich aber auf drei häufige Gründe zusammenfassen:
- mangelnde Bereitschaft der Menschen, Informationen zu geben (z. B. Einkommensverhältnisse, sexuelle Orientierung usw.)
- Fehler bei der Dateneingabe, die auf mangelhafte Datenstandards zurückzuführen sind (Webformulare ohne Pflichtfelder)
- Felder, die für die Zielgruppe nicht relevant sind (z. B. wird eine Spalte, in der der Firmenname verlangt wird, leer gelassen, wenn die Mehrheit der Antwortenden im Ruhestand ist)
- Für Forscher, die an Längsschnittstudien teilnehmen, ist die Abbruchquote (Teilnehmer, die aus der Studie aussteigen) ebenfalls eine der Hauptursachen für fehlende Daten.
In statistischen Forschungsmodellen führen diese Ursachen zu vier Arten von fehlenden Daten, die Forscher identifizieren müssen, bevor sie versuchen, Korrekturen vorzunehmen. Obwohl die statistische Erfassung fehlender Datentypen nicht in den Rahmen dieses Artikels fällt, werde ich Ihnen dennoch einen grundlegenden Überblick geben.
Anmerkung:
Für diejenigen, die an einem tieferen Verständnis der Arten von fehlenden Daten in der Gesundheitsforschung und in Längsschnittstudien interessiert sind, ist der Artikel „Strategies for handling missing data in longitudinal studies“ aus dem Journal of Statistical Computation and Simulation eine hervorragende Quelle.
Arten von fehlenden Daten:
In der statistischen Forschung werden fehlende Daten in vier Typen unterteilt:
Strukturell: Daten, die fehlen, weil sie logischerweise nicht existieren sollten.
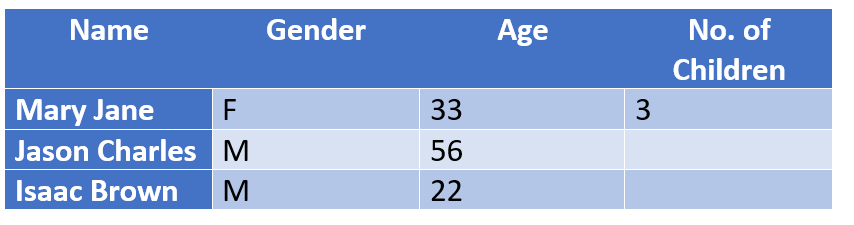
Beispiel: Personen, die keine Kinder haben, lassen die Spalte [No .of Children] leer. Diese Personen können strukturell von den Schlussfolgerungen ausgeschlossen werden, ohne dass sich dies auf das Ergebnis einer Studie auswirkt, da sie dieses Feld logischerweise nicht ausfüllen müssen.
Vollständig zufällig fehlende Daten (MCAR): Die Spalten mit fehlenden Daten stehen nicht in einem Abhängigkeitsverhältnis zueinander.
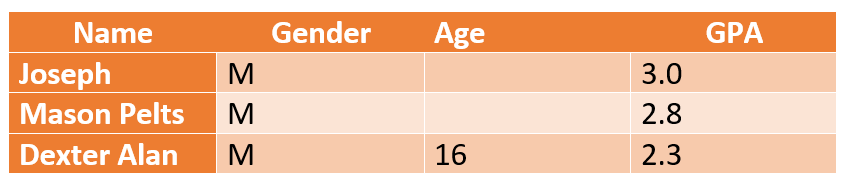
Beispiel: Fehlende Altersangaben stehen nicht im Zusammenhang mit den GPA-Werten eines Schülers in einer Studie zur Messung der akademischen Leistungen von K-12-Schülern. Forscher können ein Durchschnittsalter annehmen (z. B. 16 bis 18 Jahre für K-12) und mit dem Abschluss eines Berichts fortfahren, ohne dessen Glaubwürdigkeit zu beeinträchtigen.
Fehlende Werte nach dem Zufallsprinzip (MAR): Im Gegensatz zu MCAR, bei dem es keine Verbindung zwischen fehlenden Werten und dem Studienteilnehmer gibt, ermöglicht MAR die Vorhersage eines Musters durch die Verwendung anderer Informationen über die Person.
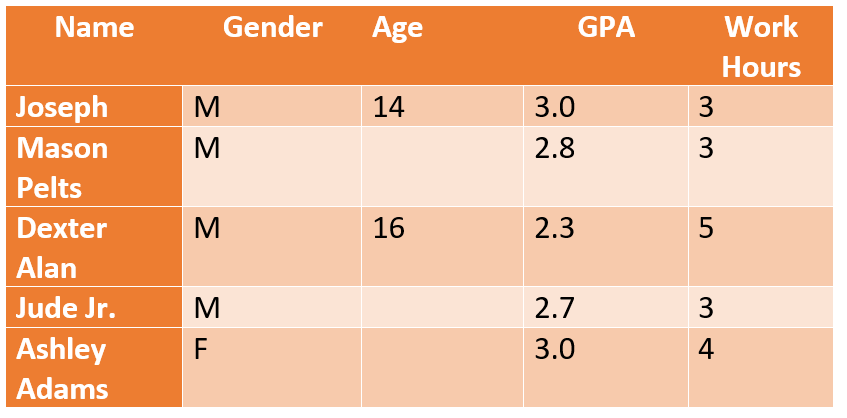
Beispiel: Im obigen Beispiel hat das Alter keinen Einfluss auf die GPA-Werte, wohl aber auf die Beschäftigung. Die Forscher kommen zu dem Schluss, dass Schüler im Alter von über 14 Jahren aufgrund einer Teilzeitbeschäftigung, die sich auf ihre Lernzeiten und ihre geistige Leistungsfähigkeit auswirkt, möglicherweise schlechtere akademische Ergebnisse erzielen.
Nicht zufällig fehlende Daten (MNAR): MNAR ist etwas verwirrend und bezieht sich auf Daten, die absichtlich fehlen, d. h. auf Personen, die sich weigern zu antworten. In der oben genannten Studie weigern sich beispielsweise die meisten 14-Jährigen *vielleicht*, ihre tatsächlichen Arbeitsstunden zu leisten. MNAR-Daten sind höchst problematisch, da man weder auf einen bestimmten Grund schließen oder diesen vermuten kann, noch kann man die Standardmethoden für fehlende Daten anwenden, um eine schlüssige Antwort zu erhalten.
In der Geschäftswelt ist die Art der fehlenden oder unvollständigen Daten eine andere. Sie müssen sich zwar nicht mit MAR- oder MNAR-Problemen befassen, wohl aber mit fehlenden Kontaktinformationen (Telefonnummern, Nachnamen, E-Mails, Adressen, Postleitzahlen usw.).
Wie werden fehlende Daten identifiziert?
Forscher, die mit Statistikprogrammen wie SAS, SPSS oder Stata arbeiten, müssen fehlende Werte manuell ermitteln, löschen und ersetzen. Aber es gibt ein Problem.
Die meisten dieser Programme entfernen automatisch fehlende Werte aus jeder von Ihnen durchgeführten Analyse, weshalb die verschiedenen Variablen unterschiedlich viele fehlende Daten aufweisen. Daher müssen die Forscher einen Datensatz auf fehlende Daten überprüfen , bevor sie entscheiden können, welche Daten sie entfernen wollen. Dieser Prozess ist manuell und erfordert neben der Beherrschung von Python – der Sprache, die zur Programmierung von Algorithmen zur Erkennung fehlender Daten verwendet wird – auch spezifische Plattformkenntnisse.
Die Ermittlung der fehlenden Daten ist nur der erste Schritt des Problems. Sie müssen zusätzliche Kodierungen vornehmen, um fehlende Werte durch Imputationen zu ersetzen (d. h. Mittelwert, Median, um fehlende Werte zu ersetzen). Sie müssen Spalten manuell abgleichen, Codes schreiben und den Vorgang so lange wiederholen, bis das gewünschte Ergebnis erreicht ist. In einem Zeitalter, in dem Schnelligkeit die Norm ist, können Sie es sich nicht leisten, Monate damit zu verbringen, fehlende Werte zu ermitteln und sie zu beheben.
Dasselbe Problem stellt sich auch im geschäftlichen Umfeld. CRMs sollten den Aufwand für die Datenverwaltung verringern, aber Probleme mit fehlenden Daten sind nach wie vor eine große Herausforderung. Die Benutzer müssen fehlende Werte manuell ermitteln und sie bereinigen, indem sie die Daten in ein XLS-Format exportieren, um Massenänderungen vorzunehmen. Wenn nur grundlegende Kontaktinformationen fehlen, kann dies mit Excel behoben werden, aber was ist, wenn die Art der fehlenden Daten über Kontaktinformationen hinausgeht? Was ist, wenn es sich um firmenbezogene oder psychografische Daten handelt?
Wie entdeckt man unvollständige Firmennamen (z. B. BOSE [a brand] vs. BOSE Corporation [a company]). Es ist nicht so einfach, dies manuell zu tun!
Die wichtigste Frage, die es zu beantworten gilt, lautet: Wie lassen sich Probleme mit fehlenden Daten begrenzen und die Vollständigkeit der Daten sicherstellen?
Was ist Datenvollständigkeit und wie kann man sie messen?
Im Rahmen der Datenqualität bezieht sich die Vollständigkeit der Daten auf das Ausmaß, in dem alle Daten in einem Datensatz verfügbar sind. Ein Maß für die Vollständigkeit der Daten ist der Prozentsatz der fehlenden Dateneinträge.
Eine Spalte mit 500 Feldern und 100 fehlenden Feldern hat zum Beispiel einen Vollständigkeitsgrad von 80 %. Je nach Unternehmen können 20 % fehlende Einträge den Verlust von Hunderttausenden von Dollar an Interessenten und Leads bedeuten!
Allerdings geht es bei der Vollständigkeit der Daten nicht darum, dass 100 % der Felder vollständig sind. Es geht darum zu bestimmen, welche Informationen wichtig und welche optional sind. So benötigen Sie zum Beispiel auf jeden Fall Telefonnummern, aber vielleicht keine Faxnummern.
Die Vollständigkeit gibt an, wie viele Informationen und Kenntnisse Sie über Ihren Kunden haben und wie genau diese Informationen sind. Bei den Kontaktdaten kann es beispielsweise sein, dass Kinder und ältere Menschen keine E-Mail-Adressen haben oder dass einige Kontakte keine Festnetz- oder Arbeitsnummern haben.
Datenvollständigkeit bedeutet also nicht, dass alle Datenattribute vorhanden oder ausgefüllt sein müssen. Vielmehr müssen Sie klassifizieren und auswählen, welche Datensätze wichtig sind und beibehalten werden müssen und welche ignoriert werden können.
Wie wird die Vollständigkeit der Daten bewertet?
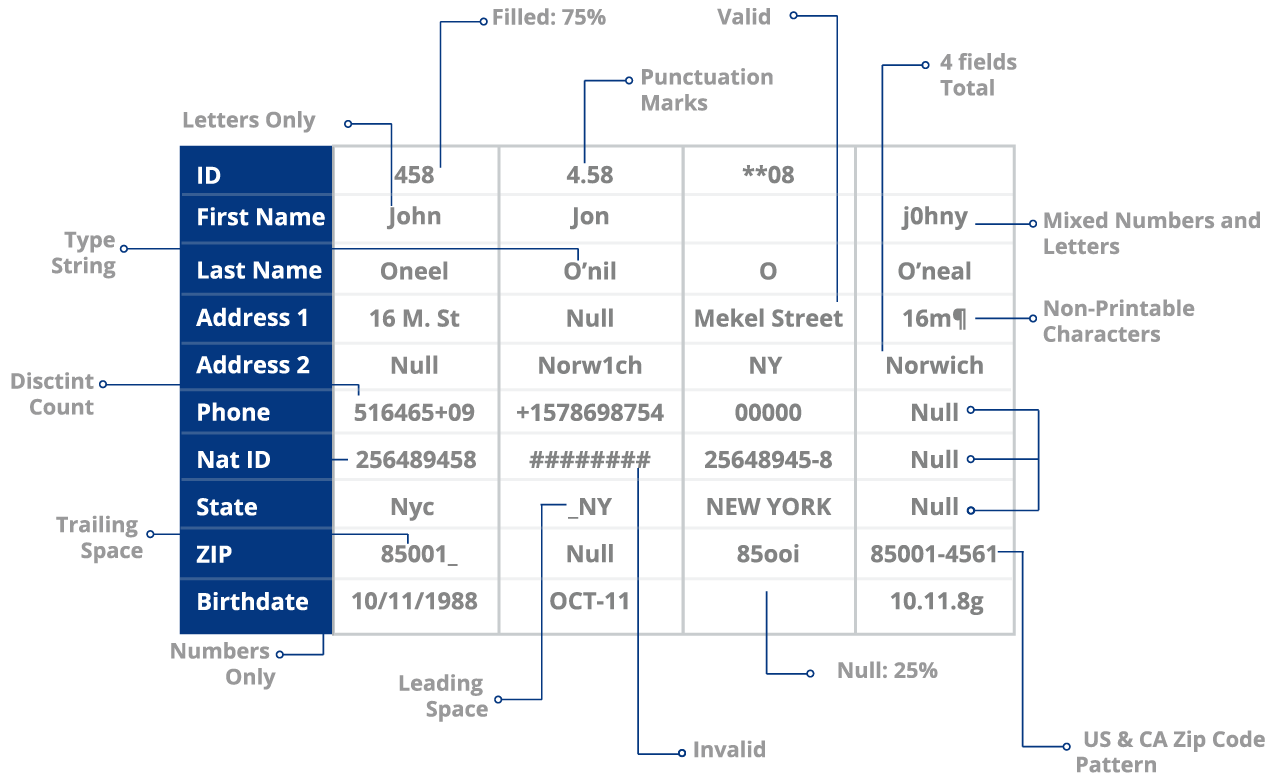
Traditionell wird die Datenvollständigkeit im Data Warehouse durch ETL-Tests bewertet, bei denen Aggregatfunktionen wie (Summe, Maximum, Minimum, Anzahl) zur Bewertung der durchschnittlichen Vollständigkeit einer Spalte oder eines Datensatzes verwendet werden. Darüber hinaus wird die Datenprofilvalidierung auch durch manuelle Anweisungen unter Verwendung von Befehlen wie:

um unterschiedliche Werte und die Anzahl der Zeilen für jeden unterschiedlichen Wert zu vergleichen. Bevor der Benutzer die Befehle ausführt, muss er jedoch die Art der Unvollständigkeit bestimmen, mit der er zu tun hat, und die Art des Datenqualitätsproblems ermitteln, das die Daten betrifft. Wenn z. B. bei allen Telefonnummern die Vorwahlen fehlen, könnte es sich um ein Problem der Datenqualität auf der Eingangsebene handeln. Wenn mehr als 50 % der Teilnehmer keine Antwort auf ein bestimmtes Problem geben, handelt es sich möglicherweise um ein MNAR-Problem (missing not at random).
All das ist großartig. Aber es gibt einen wichtigen Schritt, den alle Nutzer übersehen:
Sie können fehlende Werte nicht bereinigen, entfernen oder ersetzen, wenn Sie nicht wissen, was fehlt und wie viel Prozent dieser fehlenden Daten tolerierbar sind.
Und dies geschieht durch Datenprofilierung!
Data Profiling – Der erste Schritt zur Überprüfung der Datenvollständigkeit und zur Identifizierung fehlender Werte auf Attributsebene
Bei der Datenprofilierung wird Ihr Datensatz ausgewertet, um eine Reihe von Problemen zu ermitteln, darunter:
- Fehlende Werte und Datensätze
- Datenfehler wie Tippfehler
- Anomalien auf Attributsebene (Verwendung von Satzzeichen oder negativen Leerzeichen in Feldern)
- Standardisierungsprobleme (Inkonsistenz der Formate NYC vs. New York)
und mehr.
Die Erstellung von Datenprofilen ist eine sehr umfangreiche Aufgabe.
Im Idealfall möchten Sie in der Lage sein, einen Blick auf die Kundendaten zu werfen und die Nullwerte in den Daten einfach oder schnell zu identifizieren. Sie könnten dies nun manuell tun, indem Sie jede Spalte einzeln überprüfen oder Algorithmen ausführen.
Python ermöglicht es dem Benutzer, seine Daten auf der Grundlage seiner Wahrnehmung und seines Verständnisses zu sortieren. Dies ist zwar ideal, wenn es um Kontrolle und Anpassung geht, aber nicht ideal, wenn Sie unter Zeitdruck stehen und es auf Genauigkeit ankommt.
Sie müssen ständig Codes erstellen und überprüfen. Sie müssen ständig testen, messen und die Ergebnisse analysieren. Dies ist nicht nur kontraproduktiv, sondern verfehlt auch den Zweck der Nutzung von Daten zur Erreichung von Echtzeitzielen.
Können Ihre Marketingteams 4 Monate warten, bis Sie Kundendaten aus verschiedenen Quellen bereinigt, abgeleitet und konsolidiert haben?
Kann es sich Ihr Unternehmen leisten, mit jedem Tag, der zu einem ROI-Verlust führt, diesen zu verlieren? Nicht wirklich.
Verwendung einer ML-basierten Lösung wie DataMatch Enterprise im Vergleich zu Python Scripting oder ETL-Tools
Python-Skripte und ETL-Tools sind ideal, weil Sie die Kontrolle darüber haben. Die Verwendung eines automatisierten Tools bedeutet nicht, dass Sie die Kontrolle aufgeben oder die Nützlichkeit dieser Plattformen verwerfen. Es bedeutet lediglich, dass Sie den Prozess beschleunigen und bei Bedarf automatisieren.
Eine Lösung mit maschinellem Lernen wie DataMatch Enterprise von Data Ladder – eine Lösung für das Datenqualitätsmanagement, mit der Sie fehlende Werte und unvollständige Informationen erkennen können, ohne dass Codes oder Skripte erforderlich sind.
Mit der Datenprofilierungsfunktion von DME können Sie den Prozentsatz der Datenvollständigkeit auf Attributsebene überprüfen (dies ist über ETL oder Kodierung nur schwer möglich).
Wenn zum Beispiel 30 von 100 Datensätzen fehlende Werte aufweisen, werden diese automatisch hervorgehoben, damit Sie sie überprüfen können. Außerdem erhalten Sie für jede Spalte einen Gesundheitswert. In diesem Fall hat Ihre Spalte „Nachname“ einen Gesundheitswert von 70 %. All dies ist innerhalb von nur 10 Minuten erledigt. Sie ersparen sich stundenlange manuelle Überprüfungen, das Testen von Algorithmen und das Schreiben/Umschreiben von Definitionen , nur um Ihre Daten auf Richtigkeit oder Vollständigkeit zu überprüfen.
Das ist noch nicht alles.
Manchmal ist es auch erforderlich, Daten zu konsolidieren und redundante Daten zu bereinigen. Sie stellen zum Beispiel fest, dass die Informationen über Ihren Kunden in zwei verschiedenen Datenquellen gespeichert sind. Eine Quelle enthält alles, was Sie brauchen – Telefonnummern, E-Mail-Adressen, Standorte usw. Die andere Quelle enthält Informationen, die Sie nicht unbedingt benötigen – Alter, Geschlecht, Faxnummern usw. Sie möchten beide kombinieren und diese Informationen entweder zusammenführen oder bereinigen, um die Vollständigkeit zu gewährleisten. Stellen Sie sich den Zeitaufwand und die Prozesse vor, die Sie dafür aufwenden müssen. Allein der Gedanke daran ist anstrengend.
Mit einem Tool wie DME können Sie eine Million Datensätze innerhalb von 20 Minuten abgleichen und ableiten!
Das wahre Ziel der Datenvollständigkeit
Es ist leicht zu fehlende Werte ignorieren und mit der Erstellung von Berichten oder der Durchführung von Aktivitäten fortfahren, obwohl Sie wissen, dass Daten fehlen. Das Ergebnis sind Aufgaben, die zu schlechten Antworten führen (z. B. eine E-Mail-Marketingkampagne, bei der fehlende Nachnamen ignoriert wurden und die mit Duplikaten zu kämpfen hatte), Berichte mit irreführenden Schlussfolgerungen, die sich auf politische Maßnahmen und wichtige Reformen auswirken, Geschäftspläne, die scheitern, und Fehler, die rechtliche Auswirkungen haben.
Das wahre Ziel der Datenvollständigkeit besteht also nicht darin, perfekte, 100 %ige Daten zu haben. Es geht darum, sicherzustellen, dass die für Ihren Zweck wesentlichen Daten gültig, vollständig, genau und brauchbar sind. Die Ihnen zur Verfügung stehenden Hilfsmittel, wie DME, sind Technologien, die Ihnen dabei helfen werden.



