




























Last Updated on marzo 9, 2022
Los datos del mundo real siempre tendrán valores incompletos o faltantes, especialmente si se recogen de varias fuentes. Los datos incompletos pueden dar lugar a informes defectuosos y conclusiones sesgadas en el sector de la investigación. Para las empresas, esto se traduce en un conocimiento deficiente de los clientes, una inteligencia empresarial inexacta y la pérdida de rentabilidad.
La exhaustividad de los datos, por tanto, es un componente esencial del marco de calidad de los datos y está estrechamente relacionada con la validez y la precisión. Si faltan los datos, la información no puede validarse y si no se valida, no puede considerarse exacta.
Ya sea un investigador con datos de encuestas, un profesional de la empresa con datos de CRM o un profesional de TI con datos de la organización, debe ser capaz de identificar los valores de los datos que faltan o están incompletos para determinar el siguiente curso de acción.
En este breve post, cubriré conceptos clave como:
- ¿Qué significa que falten datos?
- Tipos de datos que faltan
- ¿Cómo se identifican los datos que faltan?
- El significado de la integridad de los datos
- Tipos de integridad de los datos
- Cómo medir la exhaustividad
- Cómo DataMatch Enterprise es más eficaz que Python para identificar los datos que faltan
¿Qué significa que falten datos?
Los datos que faltan se refieren a las filas o columnas que tienen valores nulos, en blanco o incompletos.
Ejemplos:
- Faltan apellidos, números de teléfono y direcciones de correo electrónico en un CRM
- Edad y años de empleo perdidos en un conjunto de datos observacionales
- Faltan cifras de ingresos de los empleados en los datos de la organización
Las causas de la falta de datos son muchas, pero pueden resumirse en tres motivos comunes:
- La falta de voluntad de las personas para proporcionar información (como cifras de ingresos, orientación sexual, etc.)
- Errores de entrada de datos que son el resultado de normas de datos deficientes (formularios web que no tienen campos obligatorios)
- Campos que no son relevantes para el público objetivo (por ejemplo, una columna que requiera el nombre de la empresa se dejará vacía si la mayoría de los encuestados son jubilados)
- Para los investigadores que realizan estudios longitudinales, las tasas de deserción (los participantes que abandonan el estudio) son también una de las principales causas de la falta de datos.
En los modelos de investigación estadística, estas causas dan lugar a cuatro tipos de datos que faltan y que los investigadores deben identificar antes de intentar corregirlos. Aunque la estadística de los tipos de datos que faltan no entra en el ámbito de este artículo, le daré un repaso básico.
Nota:
Para quienes estén interesados en conocer más a fondo los tipos de datos que faltan en la investigación sanitaria y en los estudios longitudinales, el artículo «Strategies for handling missing data in longitudinal studies» (Estrategias para tratar los datos que faltan en los estudios longitudinales ), del Journal of Statistical Computation and Simulation, es un gran recurso para profundizar.
Tipos de datos perdidos:
En la investigación estadística, los datos que faltan se clasifican en cuatro tipos:
Estructural: Datos que faltan porque lógicamente no deberían existir.
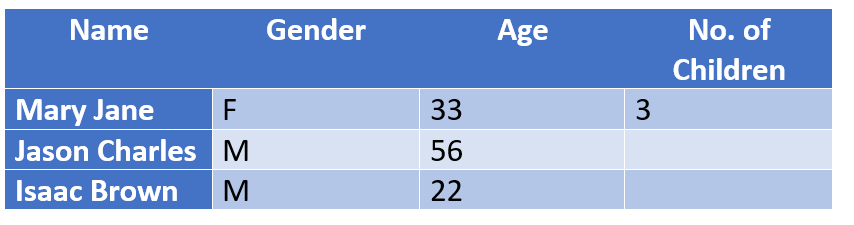
Ejemplo: Las personas que no tienen hijos dejan la columna [No .of Children] vacía. Estas personas pueden ser excluidas estructuralmente de la conclusión sin que ello repercuta en el resultado de un estudio porque, lógicamente, no necesitan rellenar ese campo.
Falta completamente al azar (MCAR): Las columnas con datos faltantes no tienen una interdependencia.
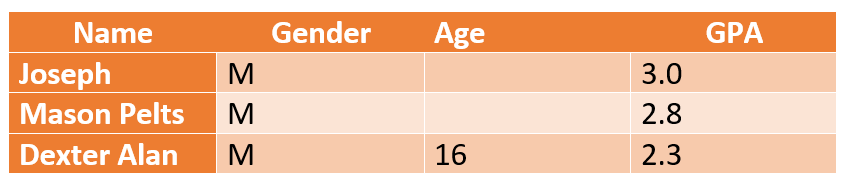
Ejemplo: los valores de edad que faltan no están relacionados con las puntuaciones del GPA de un estudiante en un estudio que mide el rendimiento académico de los estudiantes de K-12. Los investigadores pueden asumir una edad media (por ejemplo, de 16 a 18 años para el K-12) y seguir adelante con la conclusión de un informe sin que ello afecte a su credibilidad.
Faltas al azar (MAR): A diferencia del MCAR, en el que no hay conexión entre los valores perdidos y el sujeto de estudio, el MAR nos permite predecir un patrón utilizando otra información sobre la persona.
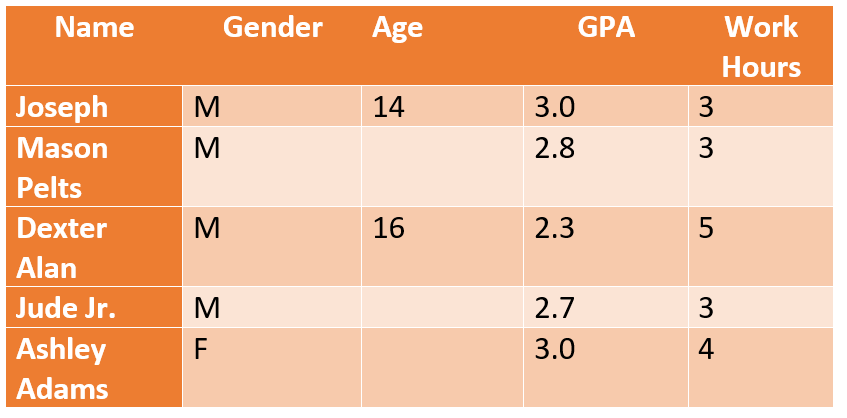
Ejemplo: Refiriéndonos al ejemplo anterior, la edad no está relacionada con las puntuaciones del GPA, pero sí influye en el empleo. Los investigadores pueden concluir que los estudiantes de más de 14 años pueden tener resultados académicos más bajos debido a un trabajo a tiempo parcial que afecta a sus horas de estudio y a su capacidad mental.
Falta no aleatoria (MNAR): Un poco confuso, el MNAR se refiere a los datos que faltan a propósito, es decir, las personas que se niegan a responder. Por ejemplo, en el estudio anterior, la mayoría de los jóvenes de 14 años *puede* negarse a cumplir sus horas de trabajo reales. Los datos MNAR son muy problemáticos porque no se puede concluir o asumir una razón específica y tampoco se pueden utilizar los métodos estándar de manejo de datos faltantes para extraer una respuesta concluyente.
En el mundo empresarial, la naturaleza de los datos ausentes o incompletos es diferente. Si bien no tiene que lidiar con problemas de MAR, MNAR, sí tiene que lidiar con la falta de información de contacto (números de teléfono, apellidos, correos electrónicos, direcciones, códigos postales, etc.).
¿Cómo se identifican los datos que faltan?
Los investigadores que trabajan con programas estadísticos como SAS, SPSS o Stata tienen que utilizar procedimientos estadísticos manuales para identificar, eliminar y sustituir los valores perdidos. Pero hay un problema.
La mayoría de estos programas eliminan automáticamente los valores perdidos de cualquier análisis que se realice, por lo que las diferentes variables tienen diferentes cantidades de datos perdidos. Por lo tanto, los investigadores tienen que comprobar si hay datos que faltan en un conjunto de datos antes de decidir qué eliminar. Este proceso es manual y exige un conocimiento específico de la plataforma, además de dominar Python, el lenguaje utilizado para codificar los algoritmos de detección de datos perdidos.
La determinación de los datos que faltan es sólo el primer paso del problema. Tendrá que realizar una codificación adicional para reemplazar los valores perdidos con imputaciones (es decir, utilizar la media, la mediana para reemplazar los valores perdidos). Tendrá que emparejar manualmente las columnas, escribir los códigos y seguir reiterando el proceso hasta alcanzar el resultado deseado. En una época en la que la rapidez es la norma, no puede permitirse pasar meses identificando los valores que faltan y resolviéndolos.
El mismo problema es aplicable también a los entornos empresariales. Los CRM debían aligerar la carga de la gestión de datos, pero los problemas de falta de datos siguen siendo un reto importante. Los usuarios tienen que identificar manualmente los valores que faltan y limpiarlos exportando los datos a un formato XLS para hacer cambios en bloque. Si sólo falta información básica de contacto, puede arreglarse con Excel, pero ¿qué pasa si la naturaleza de los datos que faltan va más allá de la información de contacto? ¿Y si se trata de datos firmográficos o psicográficos?
Cómo se descubren nombres de empresas incompletos (como BOSE [a brand] vs BOSE Corporation [a company]). No es tan fácil hacerlo manualmente.
La pregunta más importante que hay que responder es cómo limitar los problemas de falta de datos y garantizar la integridad de los mismos.
¿Qué es la integridad de los datos y cómo se mide?
En el marco de la calidad de los datos, la integridad de los datos se refiere al grado de disponibilidad de todos los datos de un conjunto de datos. Una medida de la integridad de los datos es el porcentaje de entradas de datos que faltan.
Por ejemplo, una columna de 500 con 100 campos perdidos tiene un grado de integridad del 80%. Dependiendo de su negocio, un 20% de entradas perdidas puede traducirse en la pérdida de cientos de miles de dólares en clientes potenciales y clientes potenciales.
Dicho esto, la exhaustividad de los datos no consiste en garantizar que el 100% de los campos estén completos. Se trata de determinar qué elementos de información son críticos y cuáles son opcionales. Por ejemplo, seguro que necesita números de teléfono, pero puede que no necesite números de fax.
La exhaustividad indica el nivel de información y conocimiento que tiene sobre su cliente y la precisión de esta información. Por ejemplo, en los datos de contacto, los niños y los ancianos pueden no tener direcciones de correo electrónico o algunos contactos pueden no tener números de teléfono fijo o de trabajo.
La exhaustividad de los datos, por tanto, no implica que todos los atributos de los datos deban estar presentes o rellenados, sino que habrá que clasificar y elegir qué conjuntos de datos son importantes de conservar y cuáles pueden ser ignorados.
¿Cómo se evalúa la integridad de los datos?
Tradicionalmente, en el almacén de datos, la integridad de los datos se evalúa mediante pruebas ETL que utilizan funciones agregadas como (suma, máximo, mínimo, recuento) para evaluar la integridad media de una columna o registro. Además, la validación del perfil de datos también se realiza mediante instrucciones manuales utilizando comandos como:

para comparar valores distintos y el recuento de filas para cada valor distinto. Sin embargo, antes de ejecutar los comandos, el usuario deberá determinar el tipo de incompletud con el que se enfrenta y establecer el tipo de problema de calidad de los datos que los afecta. Por ejemplo, si a todos los números de teléfono les faltan los códigos de las ciudades, podría tratarse de un problema de calidad de datos en el nivel de entrada. Si más del 50% de la audiencia no da respuesta a un problema concreto, puede tratarse de un problema MNAR (missing not at random).
Todo esto es genial. Pero hay un paso importante que todos los usuarios pasan por alto:
No se puede limpiar, eliminar o sustituir los valores que faltan si no se sabe qué falta y qué porcentaje de estos datos faltantes es tolerable.
Y esto se hace mediante la elaboración de perfiles de datos.
Perfiles de datos – El primer paso para comprobar la integridad de los datos e identificar los valores perdidos a nivel de atributos
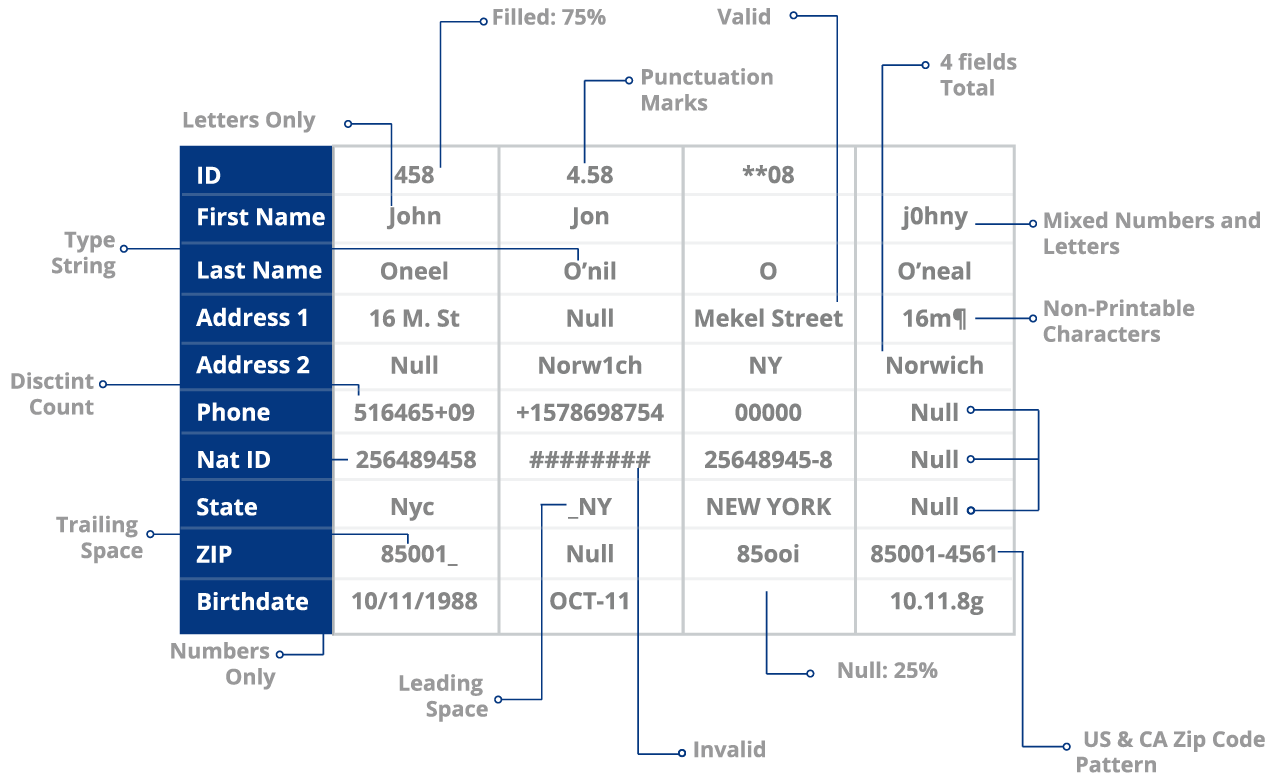
La elaboración de perfiles de datos es el proceso de evaluación de su conjunto de datos para identificar una serie de problemas, entre ellos:
- Valores y registros perdidos
- Errores en los datos, como las erratas
- Anomalías a nivel de atributos (uso de signos de puntuación o espacios negativos en los campos)
- Problemas de estandarización (incoherencia en los formatos NYC vs Nueva York)
y más.
La elaboración de perfiles de datos es una tarea exhaustiva.
Lo ideal es poder echar un vistazo a los datos del cliente e identificar fácil o rápidamente los valores nulos en los datos. Ahora podría hacerlo manualmente revisando cada columna de forma independiente o ejecutando algoritmos.
Python permite al usuario ordenar sus datos en función de su percepción y comprensión. Aunque esto es ideal en términos de control y personalización, no lo es si estás presionado por el tiempo y la precisión.
Tendrá que crear y revisar constantemente los códigos. Tendrá que seguir probando, midiendo y analizando los resultados. Esto no sólo es contraproducente, sino que además es contrario al propósito de utilizar los datos para alcanzar objetivos en tiempo real.
¿Pueden sus equipos de marketing esperar 4 meses para limpiar, desduplicar y consolidar los datos de los clientes de múltiples fuentes?
¿Puede su organización permitirse el lujo de perder el retorno de la inversión con cada día que pasa y que se traduce en una pérdida del mismo? La verdad es que no.
Uso de una solución basada en ML como DataMatch Enterprise frente a scripts de Python o herramientas ETL
Las herramientas de scripting y ETL de Python son ideales porque están bajo su control. Utilizar una herramienta automatizada no significa renunciar al control ni a la utilidad de estas plataformas. Simplemente significa que está acelerando el proceso y automatizando donde sea necesario.
Una solución habilitada para el aprendizaje automático, como DataMatch Enterprise de Data Ladder, una solución de gestión de la calidad de los datos que permite identificar los valores que faltan y la información incompleta sin necesidad de códigos o scripts.
Con la función de perfilado de datos del ISD, puede comprobar el porcentaje de integridad de los datos a nivel de atributos (algo complejo de hacer mediante ETL o codificación).
Por ejemplo, si 30 de 100 registros tienen valores que faltan, se resaltan automáticamente para que los revise. También se le da una puntuación de salud para cada columna. En este caso, su columna Apellido tiene una puntuación de salud del 70%. Todo esto se hace en cuestión de 10 minutos. Se ahorrará horas de revisiones manuales, pruebas de algoritmos y redacción/reescritura de definiciones para simplemente comprobar la exactitud o integridad de sus datos.
Eso no es todo.
A veces también es necesario consolidar los datos y desduplicar los datos redundantes. Por ejemplo, descubre que la información de su cliente está almacenada en dos fuentes de datos distintas. Una sola fuente contiene todo lo que necesitas: números de teléfono, direcciones de correo electrónico, ubicación, etc. La otra fuente contiene información que no necesariamente necesitas: edad, sexo, números de fax, etc. Es conveniente combinar los dos, y fusionar o depurar esta información para garantizar la exhaustividad. ¿Imagina el tiempo y los procesos que tendrá que pasar para conseguirlo? El mero hecho de pensarlo es agotador.
Con una herramienta como el ISD se pueden cotejar y desduplicar un millón de registros en 20 minutos.
El verdadero objetivo de la exhaustividad de los datos
Es fácil ignorar los valores que faltan y proceder a la elaboración de informes o a la realización de actividades sabiendo que faltan datos. El resultado final son tareas que ofrecen respuestas deficientes (como una campaña de marketing por correo electrónico que ignoró los apellidos que faltaban y tuvo que luchar con los duplicados), informes con conclusiones erróneas que afectan a las políticas y a las reformas críticas, planes de negocio que fracasan y errores que tienen implicaciones legales.
Dicho esto, el verdadero objetivo de la exhaustividad de los datos no es tener datos perfectos al 100%. Se trata de garantizar que los datos esenciales para su propósito sean válidos, completos, precisos y utilizables. Las herramientas que tiene a su disposición, como el DME, es una tecnología que le ayudará a conseguirlo.



