





























Last Updated on mars 28, 2022
Les données du monde réel auront toujours des valeurs incomplètes ou manquantes, surtout si elles sont recueillies auprès de plusieurs sources. Des données incomplètes peuvent donner lieu à des rapports erronés et à des conclusions faussées dans le secteur de la recherche. Pour les entreprises, cela se traduit par une mauvaise connaissance du client, des informations commerciales inexactes et une perte de retour sur investissement.
L’exhaustivité des données est donc une composante essentielle du cadre de qualité des données et est étroitement liée à la validité et à l’exactitude. Si les données sont manquantes, l’information ne peut pas être validée et si elle ne l’est pas, elle ne peut pas être considérée comme exacte.
Que vous soyez un chercheur travaillant sur des données d’enquête, un professionnel de l’entreprise travaillant sur des données CRM ou un professionnel de l’informatique travaillant sur des données organisationnelles, vous devez être en mesure d’identifier les valeurs de données manquantes ou incomplètes afin de déterminer la marche à suivre.
Dans ce bref article, je vais aborder les concepts clés suivants :
- Que signifie l’absence de données
- Types de données manquantes
- Comment identifier les données manquantes
- La signification de l’exhaustivité des données
- Types d’exhaustivité des données
- Comment mesurer l’exhaustivité
- Comment DataMatch Enterprise est plus efficace que Python pour identifier les données manquantes
Que signifie l’absence de données ?
Les données manquantes désignent les lignes ou les colonnes dont les valeurs sont nulles, vides ou incomplètes.
Exemples :
- Noms de famille, numéros de téléphone et adresses électroniques manquants dans un CRM
- Âge et années d’emploi manquants dans un ensemble de données d’observation
- Chiffres de revenus manquants des employés dans les données d’organisation
Les causes des données manquantes sont nombreuses, mais peuvent être résumées à trois raisons courantes :
- La réticence des gens à fournir des informations (comme les revenus, l’orientation sexuelle, etc.).
- Les erreurs de saisie de données qui sont le résultat de mauvaises normes de données (formulaires web qui n’ont pas de champs obligatoires)
- Les champs qui ne sont pas pertinents pour le public cible (par exemple, une colonne demandant le nom de l’entreprise sera laissée vide si la majorité des répondants sont des retraités).
- Pour les chercheurs qui s’engagent dans des études longitudinales, le taux d’attrition (participants qui abandonnent l’étude) est également une cause majeure de données manquantes.
Dans les modèles de recherche statistique, ces causes se traduisent par quatre types de données manquantes que les chercheurs doivent identifier avant de tenter d’y remédier. Bien que les statistiques sur les types de données manquantes n’entrent pas dans le cadre de cet article, je vais tout de même vous donner un aperçu de base.
Note :
Pour ceux qui souhaitent mieux comprendre les types de données manquantes dans la recherche sur les soins de santé et les études longitudinales, l’article intitulé « Strategies for handling missing data in longitudinal studies » (Stratégies de traitement des données manquantes dans les études longitudinales), publié par le Journal of Statistical Computation and Simulation, est une excellente ressource à consulter.
Types de données manquantes :
Dans la recherche statistique, les données manquantes sont classées en quatre types :
Structurel : Données manquantes parce qu’elles ne devraient pas logiquement exister.
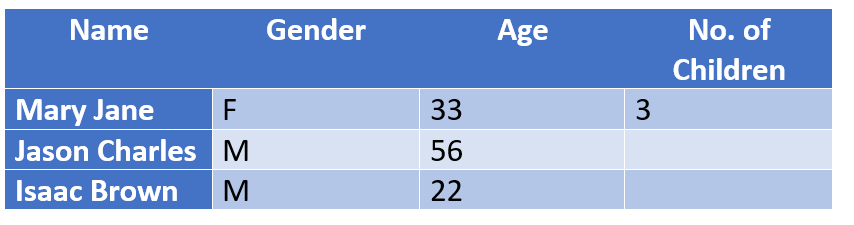
Exemple : Les personnes qui n’ont pas d’enfants laissent la colonne [No .of Children] vide. Ces personnes peuvent être structurellement exclues de la conclusion sans que cela n’ait d’impact sur le résultat d’une étude, car logiquement, elles n’ont pas besoin de remplir ce champ.
Données manquantes complètement au hasard (MCAR) : Les colonnes avec des données manquantes n’ont pas d’interdépendance.
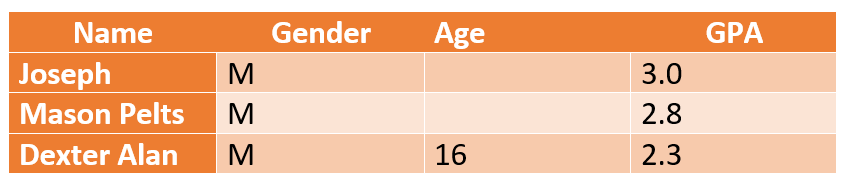
Exemple: les valeurs d’âge manquantes ne sont pas liées aux résultats de la moyenne générale d’un élève dans une étude mesurant les performances scolaires des élèves de la maternelle à la terminale. Les chercheurs peuvent supposer un âge médian (par exemple 16 à 18 ans pour la maternelle et le secondaire) et continuer à conclure un rapport sans que cela n’affecte sa crédibilité.
Manquant au hasard (MAR) : Contrairement à la MCAR, où il n’y a aucun lien entre les valeurs manquantes et le sujet de l’étude, la MAR nous permet de prédire un modèle en utilisant d’autres informations sur la personne.
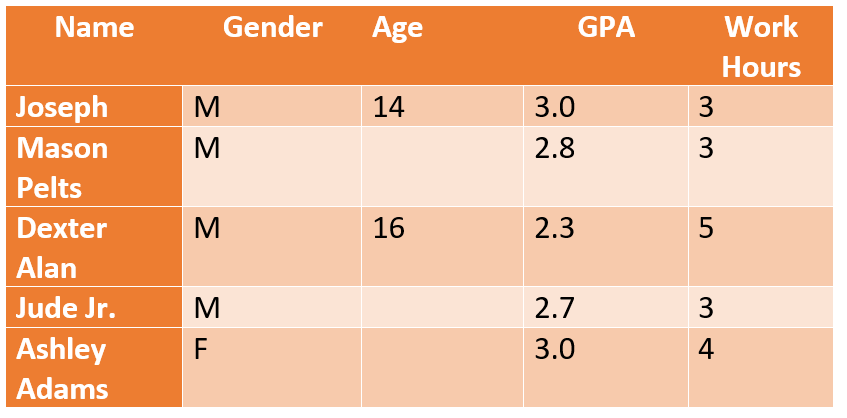
Exemple : Si l’on se réfère à l’exemple ci-dessus, l’âge n’est pas lié aux notes de GPA, mais il a un impact sur l’emploi. Les chercheurs peuvent conclure que les élèves de plus de 14 ans peuvent avoir des résultats scolaires inférieurs en raison d’un emploi à temps partiel qui affecte leurs heures d’étude et leur capacité mentale.
Données manquantes non aléatoires (MNAR) : Légèrement déroutant, MNAR se réfère aux données qui sont volontairement manquantes – c’est-à-dire que les personnes refusent de répondre. Par exemple, dans l’étude ci-dessus, la plupart des jeunes de 14 ans *pourraient* refuser de remplir leurs heures de travail réelles. Les données MNAR sont très problématiques car vous ne pouvez pas conclure ou supposer une raison spécifique et vous ne pouvez pas non plus utiliser les méthodes standard de traitement des données manquantes pour obtenir une réponse concluante.
Dans le monde des affaires, la nature des données manquantes ou incomplètes est différente. Bien que vous n’ayez pas à vous occuper des problèmes de MAR et de MNAR, vous devez vous occuper des informations de contact manquantes. (numéros de téléphone, noms de famille, adresses électroniques, adresses, codes postaux, etc.)
Comment les données manquantes sont-elles identifiées ?
Les chercheurs qui travaillent avec des programmes statistiques tels que SAS, SPSS, Stata doivent utiliser des procédures statistiques manuelles pour identifier, supprimer et remplacer les valeurs manquantes. Mais il y a un problème.
La plupart de ces programmes suppriment automatiquement les valeurs manquantes de toute analyse que vous exécutez, ce qui explique pourquoi différentes variables présentent des quantités différentes de données manquantes. Les chercheurs doivent donc vérifier qu’il n’y a pas de données manquantes dans un ensemble de données avant de pouvoir décider de ce qu’il faut supprimer. Ce processus est manuel et exige des connaissances spécifiques de la plateforme en plus de la maîtrise de Python – le langage utilisé pour coder les algorithmes de détection des données manquantes.
Déterminer les données manquantes n’est que la première étape du problème. Vous devrez effectuer un codage supplémentaire pour remplacer les valeurs manquantes par des imputations (c’est-à-dire utiliser la moyenne, la médiane pour remplacer les valeurs manquantes). Vous devrez faire correspondre manuellement les colonnes, écrire des codes et répéter le processus jusqu’à ce que le résultat souhaité soit atteint. À une époque où la rapidité est la norme, vous ne pouvez pas vous permettre de passer des mois à identifier les valeurs manquantes et à les résoudre.
Le même problème s’applique également aux environnements professionnels. Les CRM étaient censés alléger la charge de la gestion des données, mais les problèmes de données manquantes restent un défi important. Les utilisateurs doivent identifier manuellement les valeurs manquantes et les nettoyer en exportant les données vers un format XLS pour effectuer des modifications en masse. S’il ne s’agit que d’informations de contact de base manquantes, cela peut être corrigé avec Excel, mais que faire si la nature des données manquantes va au-delà des informations de contact ? Et s’il s’agit de données firmographiques ou psychographiques ?
Comment découvrir des noms de sociétés incomplets (tels que BOSE [a brand] ou BOSE Corporation [a company]). Pas si facile à faire manuellement !
La question la plus importante à laquelle il faut répondre est la suivante : comment limiter les problèmes de données manquantes et garantir l’exhaustivité des données ?
Qu’est-ce que l’exhaustivité des données et comment la mesurer ?
Dans le cadre de la qualité des données, l’exhaustivité des données fait référence au degré de disponibilité de toutes les données d’un ensemble de données. Une mesure de l’exhaustivité des données est le pourcentage d’entrées de données manquantes.
Par exemple, une colonne de 500 avec 100 champs manquants a un degré de complétude de 80%. En fonction de votre activité, 20 % d’entrées manquantes peuvent se traduire par la perte de centaines de milliers de dollars de prospects et de pistes !
Cela dit, l’exhaustivité des données ne consiste pas à garantir que 100 % de vos champs sont complets. Il s’agit de déterminer quels éléments d’information sont essentiels et lesquels sont facultatifs. Par exemple, vous aurez certainement besoin de numéros de téléphone, mais peut-être pas de numéros de fax.
L’exhaustivité indique le niveau d’informations et de connaissances dont vous disposez sur votre client et le degré d’exactitude de ces informations. Par exemple, dans les données de contact, les enfants et les personnes âgées peuvent ne pas avoir d’adresse électronique ou certains contacts peuvent ne pas avoir de numéro de téléphone fixe ou de travail.
L’exhaustivité des données n’implique donc pas que tous les attributs des données doivent être présents ou renseignés. Vous devrez plutôt classer et choisir les ensembles de données qu’il est important de conserver et ceux qui peuvent être ignorés.
Comment l’exhaustivité des données est-elle évaluée ?
Traditionnellement, dans l’entrepôt de données, la complétude des données est évaluée par des tests ETL qui utilisent des fonctions d’agrégation telles que (somme, max, min, nombre) pour évaluer la complétude moyenne d’une colonne ou d’un enregistrement. En outre, la validation du profil des données est également effectuée par des instructions manuelles à l’aide de commandes telles que :

pour comparer des valeurs distinctes et le nombre de lignes pour chaque valeur distincte. Cependant, avant d’exécuter les commandes, l’utilisateur devra déterminer le type d’incomplétude auquel il a affaire et établir le type de problème de qualité des données qui affecte les données. Par exemple, si tous les numéros de téléphone ne comportent pas d’indicatif de ville, il peut s’agir d’un problème de qualité des données au niveau de l’entrée. Si plus de 50 % de l’auditoire ne fournit pas de réponse à un problème spécifique, il peut s’agir d’un problème MNAR (missing not at random).
Tout cela est formidable. Mais il y a une étape importante que tous les utilisateurs ratent :
Vous ne pouvez pas nettoyer, supprimer ou remplacer les valeurs manquantes si vous ne savez pas ce qui manque et quel pourcentage de ces données manquantes est tolérable.
Et cela se fait par le biais du profilage des données !
Profilage des données – La première étape pour vérifier l’exhaustivité des données et identifier les valeurs manquantes au niveau des attributs
Le profilage des données est le processus d’évaluation de votre ensemble de données pour identifier une série de problèmes, notamment :
- Valeurs et enregistrements manquants
- Erreurs de données telles que des fautes de frappe
- Anomalies au niveau des attributs (utilisation de signes de ponctuation ou d’espaces négatifs dans les champs)
- Problèmes de normalisation (incohérence des formats NYC vs New York)
et plus encore.
Le profilage des données est une tâche exhaustive.
Idéalement, vous souhaitez pouvoir jeter un coup d’œil aux données des clients et identifier facilement ou rapidement les valeurs nulles dans les données. Vous pouvez le faire manuellement en examinant chaque colonne indépendamment ou en utilisant des algorithmes.
Python permet à l’utilisateur de trier ses données en fonction de sa perception et de sa compréhension. Si cela est idéal en termes de contrôle et de personnalisation, ce n’est pas l’idéal si vous êtes pressé par le temps et la précision.
Vous devrez constamment créer et réviser les codes. Vous devrez continuer à tester, mesurer et analyser les résultats. Non seulement cela est contre-productif, mais cela va à l’encontre de l’objectif d’utiliser les données pour atteindre des objectifs en temps réel.
Vos équipes marketing peuvent-elles attendre 4 mois pour que vous nettoyiez, déduisiez et consolidiez les données clients provenant de sources multiples ?
Votre organisation peut-elle se permettre de perdre du ROI à chaque jour qui passe et qui entraîne une perte de ROI ? Pas vraiment.
Utilisation d’une solution basée sur le ML comme DataMatch Enterprise par rapport aux scripts Python ou aux outils ETL
Les outils de scripting et d’ETL en Python sont idéaux parce que vous en avez le contrôle. L’utilisation d’un outil automatisé ne signifie pas que vous abandonnez le contrôle ou que vous renoncez à l’utilité de ces plateformes. Cela signifie simplement que vous accélérez le processus et que vous l’automatisez si nécessaire.
Une solution d’apprentissage automatique comme DataMatch Enterprise de Data Ladder – une solution de gestion de la qualité des données qui vous permet d’identifier les valeurs manquantes et les informations incomplètes sans avoir besoin de codes ou de scripts.
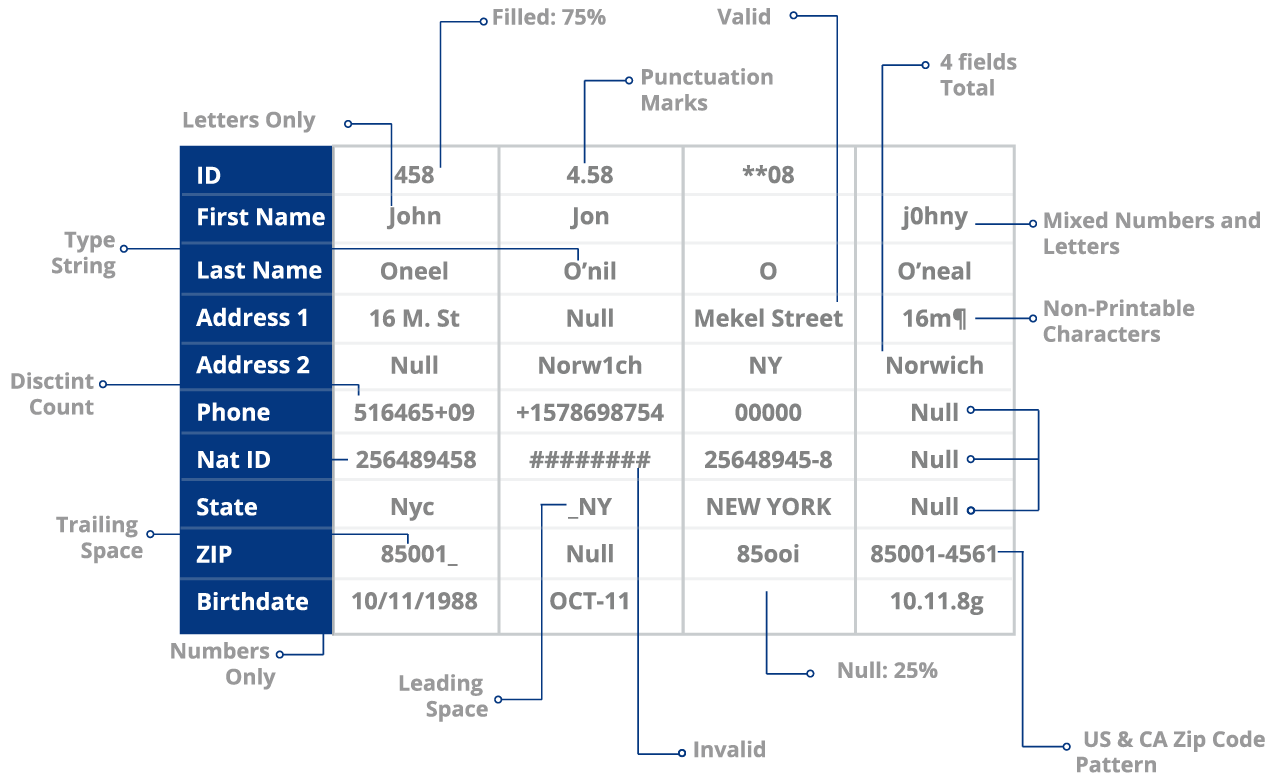
Grâce à la fonction de profilage des données de DME, vous pouvez vérifier le pourcentage de complétude des données au niveau des attributs (ce qui est complexe à réaliser via l’ETL ou le codage).
Par exemple, si 30 enregistrements sur 100 ont des valeurs manquantes, ils sont automatiquement mis en évidence pour que vous puissiez les examiner. Un score de santé vous est également attribué pour chaque colonne. Dans ce cas, votre colonne Nom a un score de santé de 70%. Tout cela se fait en l’espace de 10 minutes seulement. Vous vous épargnez des heures de révision manuelle, de test d’algorithmes et de rédaction/réécriture de définitions pour simplement vérifier l’exactitude ou l’exhaustivité de vos données.
Ce n’est pas tout.
Parfois, vous êtes également amené à consolider des données et à dédupliquer des données redondantes. Par exemple, vous découvrez que les informations relatives à votre client sont stockées dans deux sources de données distinctes. Une seule source contient tout ce dont vous avez besoin – numéros de téléphone, adresses électroniques, localisation, etc. L’autre source contient des informations dont vous n’avez pas nécessairement besoin – âge, sexe, numéros de fax, etc. Vous voulez combiner les deux, et soit fusionner ou purger ces informations pour assurer l’exhaustivité. Imaginez le temps et les processus que vous devrez passer pour y parvenir ? La simple pensée est épuisante.
Avec un outil comme DME, vous pouvez faire correspondre et déduire un million d’enregistrements en 20 minutes !
Le véritable objectif de l’exhaustivité des données
C’est facile de ignorer les valeurs manquantes et procéder à la compilation de rapports ou à la réalisation d’activités en sachant que vous avez des données manquantes. Il en résulte des tâches qui donnent lieu à des réponses médiocres (comme une campagne de marketing par courrier électronique qui n’a pas tenu compte des noms de famille manquants et qui a dû se battre avec des doublons), des rapports dont les conclusions sont trompeuses et qui ont un impact sur les politiques et les réformes essentielles, des plans d’affaires qui échouent et des erreurs qui ont des implications juridiques.
Cela dit, le véritable objectif de l’exhaustivité des données n’est donc pas d’avoir des données parfaites à 100 %. Il s’agit de s’assurer que les données essentielles à votre objectif sont valides, complètes, exactes et utilisables. Les outils que vous avez à votre disposition, tels que le DME, sont des technologies qui vous aideront à y parvenir.



