






























DataMatch Enterprise fue mucho más fácil de usar que las otras soluciones que analizamos. Poder automatizar la limpieza y el emparejamiento de datos nos ha ahorrado cientos de horas-persona cada año.


DataMatch Enterprise es un software eficiente, eficaz y relativamente fácil de usar.
No pudimos hacer estos informes antes. ¡Ahora, DataMatch se ha convertido en un elemento básico en mi conjunto de herramientas con las que trabajo!

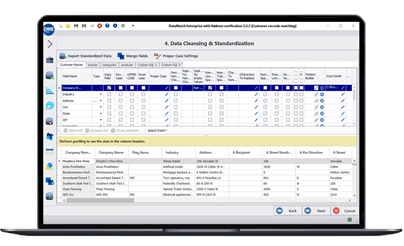
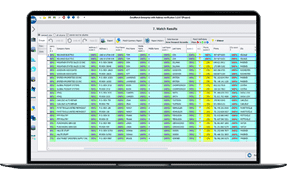

Fusionar datos de varias fuentes: desafíos y soluciones

Guía rápida para la normalización y verificación de direcciones
¿Qué es la normalización de direcciones? La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus

8 mejores prácticas para garantizar la calidad de los datos en la empresa
En febrero de 2020, Facebook entregó un conjunto de datos anónimos a Social Science One, con el fin de obtener información sobre las comunicaciones y
Guía rápida para la normalización y verificación de direcciones
¿Qué es la normalización de direcciones? La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus
8 mejores prácticas para garantizar la calidad de los datos en la empresa
En febrero de 2020, Facebook entregó un conjunto de datos anónimos a Social Science One, con el fin de obtener información sobre las comunicaciones y

Guía de concordancia de patrones: ¿Qué significa y cómo hacerlo?
Last Updated on septiembre 13, 2022 Encontrar patrones es fácil en cualquier tipo de entorno rico en datos; eso es lo que hacen los jugadores
