




























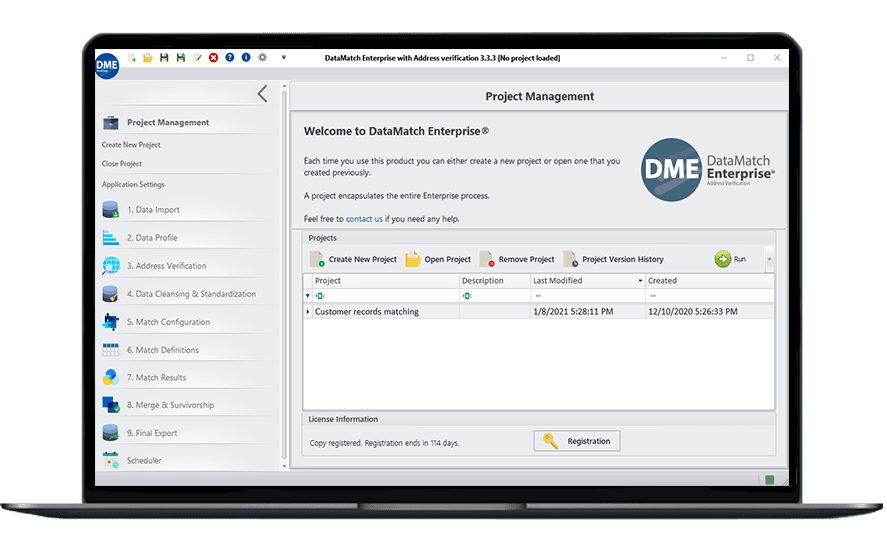






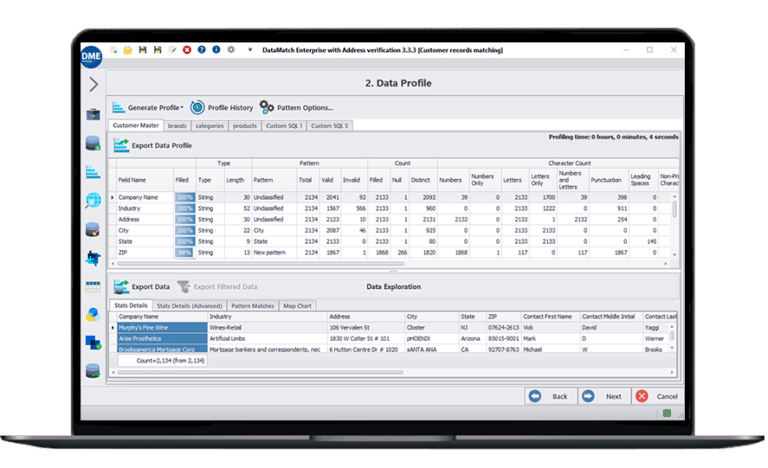
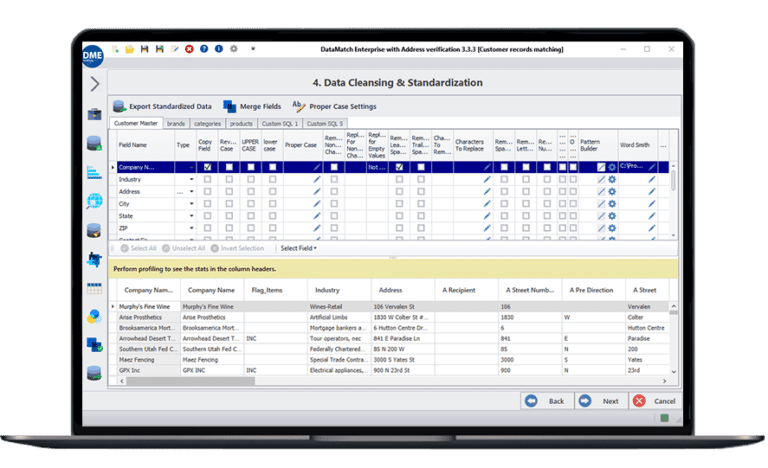
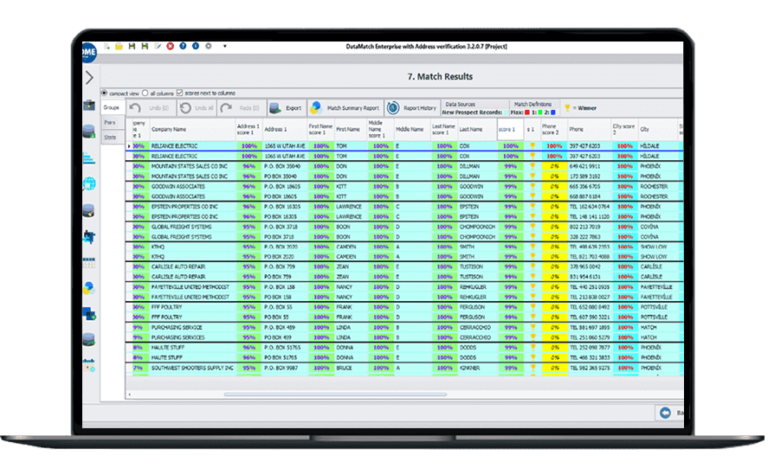
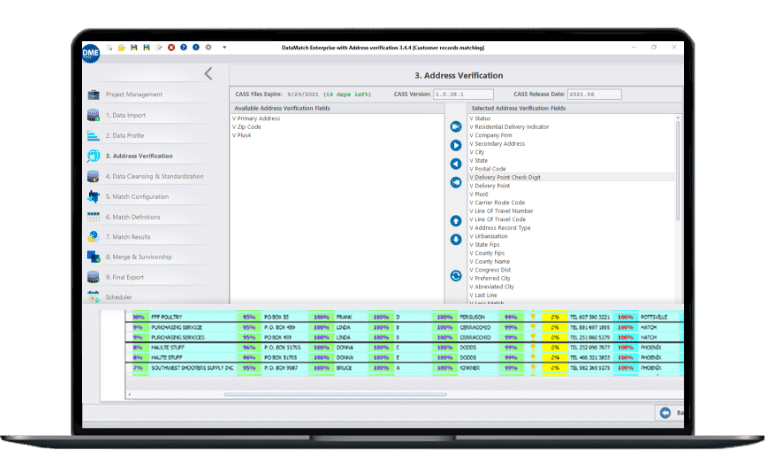
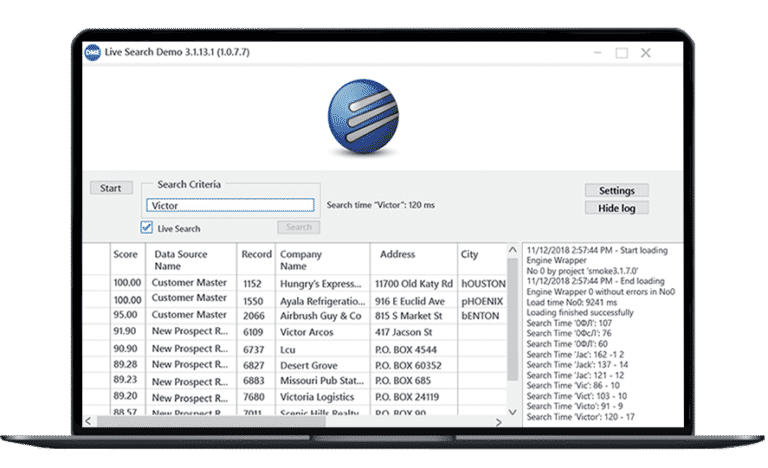
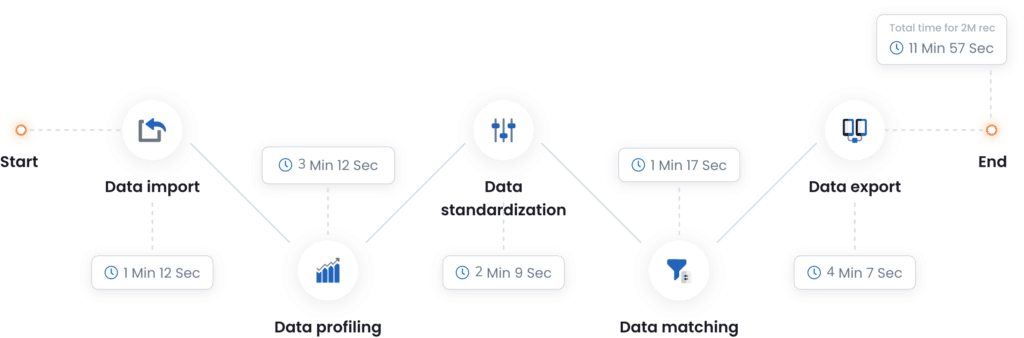

Alto rendimiento
Características de rendimiento y escalabilidad excepcionales, que permiten limpiar, cotejar y procesar toneladas de datos bajo demanda.

Aplicación rápida
Sólo tiene que descargar e implantar la aplicación en cuestión de minutos con la ayuda de nuestro asistente de instalación guiada y empezar a emparejar.
Interfaz intuitiva
Una interfaz muy visual e intuitiva hecha para usuarios empresariales, especialistas en TI, analistas y científicos de datos, así como para usuarios principiantes.

Robusta tecnología de emparejamiento
Calificado como más rápido y preciso que IBM y SAS, el DME fue el que menos falsos positivos obtuvo en estudios independientes.

Integración perfecta
Integre fácilmente las funciones de calidad de datos más rápidas y precisas del mundo en sus aplicaciones personalizadas o de terceros.
Sincronización en tiempo real
Calcule coincidencias exactas, difusas e inteligentes en tiempo real, a través y dentro de múltiples fuentes de datos a una velocidad vertiginosa.

Perfilado rápido de datos
Selección del registro maestro
Orquestación del flujo de trabajo
Filtrado avanzado

Vista previa de los datos al instante y en directo

Vinculación y deduplicación de registros

Normalización del número de teléfono

Limpieza y estandarización a granel

Limpieza de la dirección de correo electrónico
Integración de datos sin fisuras
Correspondencia entre columnas

Correspondencia y reconocimiento de patrones

No es solo el software lo que funciona muy bien para nosotros, sino el enfoque y el conocimiento que Data Ladder aporta.


Gracias a Data Ladder, limpiamos y combinamos con éxito nuestro archivo de ventas interno con nuevos clientes potenciales, mejorando enormemente la eficiencia y las ventas.

No pudimos hacer estos informes antes. Ahora, DataMatch se ha convertido en un elemento básico en mi conjunto de herramientas con las que trabajo


Fusionar datos de varias fuentes: desafíos y soluciones

Guía rápida para la normalización y verificación de direcciones
¿Qué es la normalización de direcciones? La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus

8 mejores prácticas para garantizar la calidad de los datos en la empresa
En febrero de 2020, Facebook entregó un conjunto de datos anónimos a Social Science One, con el fin de obtener información sobre las comunicaciones y
Guía rápida para la normalización y verificación de direcciones
¿Qué es la normalización de direcciones? La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus
8 mejores prácticas para garantizar la calidad de los datos en la empresa
En febrero de 2020, Facebook entregó un conjunto de datos anónimos a Social Science One, con el fin de obtener información sobre las comunicaciones y

Guía de concordancia de patrones: ¿Qué significa y cómo hacerlo?
Last Updated on septiembre 13, 2022 Encontrar patrones es fácil en cualquier tipo de entorno rico en datos; eso es lo que hacen los jugadores
