






Integración de datos
Conéctese a fuentes de datos y cargue datos de varias fuentes, como archivos locales, servidores de bases de datos relacionales, CRM u otras aplicaciones web.

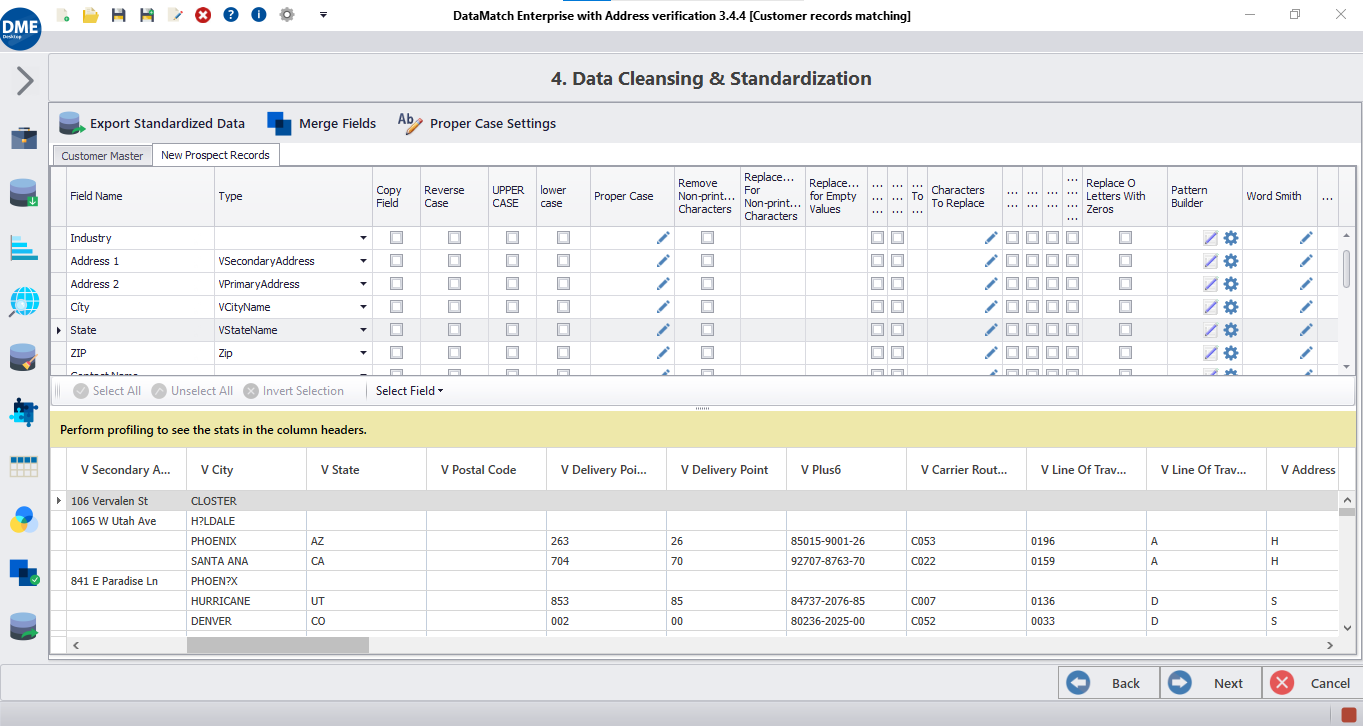
Limpieza de datos
Realice actividades de limpieza de datos para eliminar anomalías estadísticas y estructurales de los valores de los datos, como eliminar los espacios iniciales y finales, reemplazar valores nulos, corregir errores de puntuación y más.




Perfilado de datos
Ejecute comprobaciones de perfiles y validez para evaluar la calidad de los datos, crear informes de perfiles de datos actuales e identificar posibles oportunidades de limpieza de datos.

Reconocimiento y validación de patrones
Reconozca patrones ocultos en sus columnas de datos, ejecute comprobaciones de validación y transforme la información no válida para que todos los valores sigan el patrón válido.