




































DME le permite preparar sus datos antes de deducirlos, lo que implica un perfilado, limpieza y estandarización de datos avanzados. Con DME, puede ejecutar los pasos necesarios para garantizar la precisión de la deduplicación, como el reconocimiento de patrones, el reemplazo de palabras, la transformación de mayúsculas y minúsculas y la estandarización de direcciones .
DME aprovecha las técnicas avanzadas de coincidencia de campos y registros que tienen en cuenta los errores ortográficos, los errores tipográficos humanos y las variaciones convencionales en los valores de los datos. DME puede evaluar la similitud entre registros hasta el nivel del personaje. Además, avanzado coincidencia difusa También se utilizan técnicas para comparar palabras y oraciones largas.
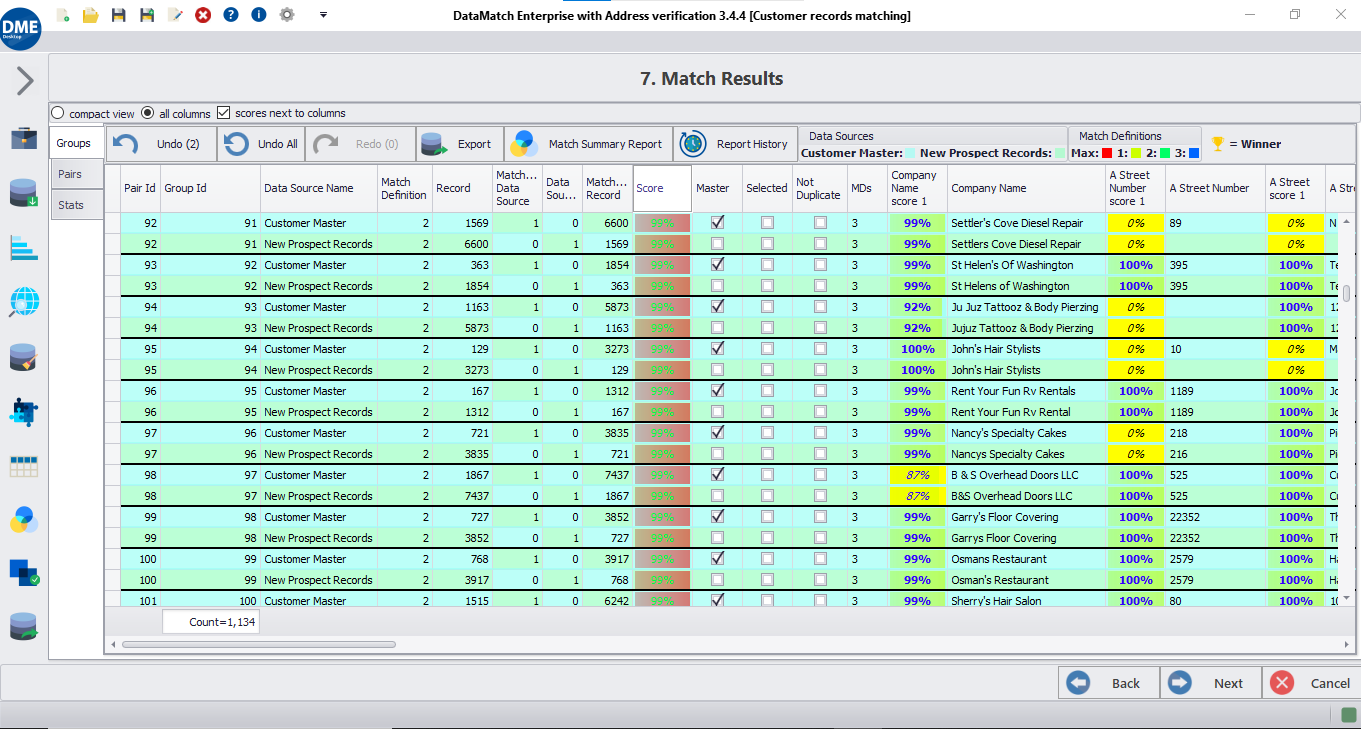
DME ejecuta potentes algoritmos de coincidencia de datos y categoriza los registros en grupos duplicados: todos los registros de un grupo duplicado son similares (o duplicados) entre sí. A cada registro duplicado también se le asigna una puntuación de coincidencia que brinda información sobre el nivel de confianza de coincidencia calculado para la coincidencia.
La revisión y selección manual del registro maestro es una tarea bastante tediosa. Es por eso que DME viene con una capacidad incorporada para configurar reglas que determinan automáticamente el registro maestro y sus duplicados. Por ejemplo, según su conjunto de datos, puede configurar el registro maestro para que sea el que tenga el nombre más largo o el que se creó más recientemente, etc.
DME puede ayudarlo a retener información importante de registros duplicados, de modo que no pierda datos y conserve una vista completa y única de su base de datos. Al configurar operaciones condicionales para fusionar y sobrescribir valores de datos, puede aprovechar al máximo sus datos.

Analistas de datos

Usuarios empresariales

Profesionales de TI

Usuarios novatos


Fusionar datos de varias fuentes: desafíos y soluciones

Guía rápida para la normalización y verificación de direcciones
¿Qué es la normalización de direcciones? La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus

8 mejores prácticas para garantizar la calidad de los datos en la empresa
En febrero de 2020, Facebook entregó un conjunto de datos anónimos a Social Science One, con el fin de obtener información sobre las comunicaciones y
Guía rápida para la normalización y verificación de direcciones
¿Qué es la normalización de direcciones? La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus
8 mejores prácticas para garantizar la calidad de los datos en la empresa
En febrero de 2020, Facebook entregó un conjunto de datos anónimos a Social Science One, con el fin de obtener información sobre las comunicaciones y

Guía de concordancia de patrones: ¿Qué significa y cómo hacerlo?
Last Updated on septiembre 13, 2022 Encontrar patrones es fácil en cualquier tipo de entorno rico en datos; eso es lo que hacen los jugadores
