






Ingestión
Reunir los datos en un solo lugar, ya que están dispersos en fuentes dispares, y resolver cualquier cambio conflictivo en los esquemas de las bases de datos para permitir su posterior procesamiento.

Normalización de datos
Solucionar los problemas de estandarización de datos señalados en el paso anterior, incluyendo el relleno de datos vacíos, la sustitución de información inexacta o no válida, la estandarización de valores con respecto a patrones y formatos definidos, etc.


Descubrimiento de datos
Descubrir y resaltar cualquier anomalía estadística que pueda estar presente en forma de valores de datos faltantes, incompletos o inválidos.

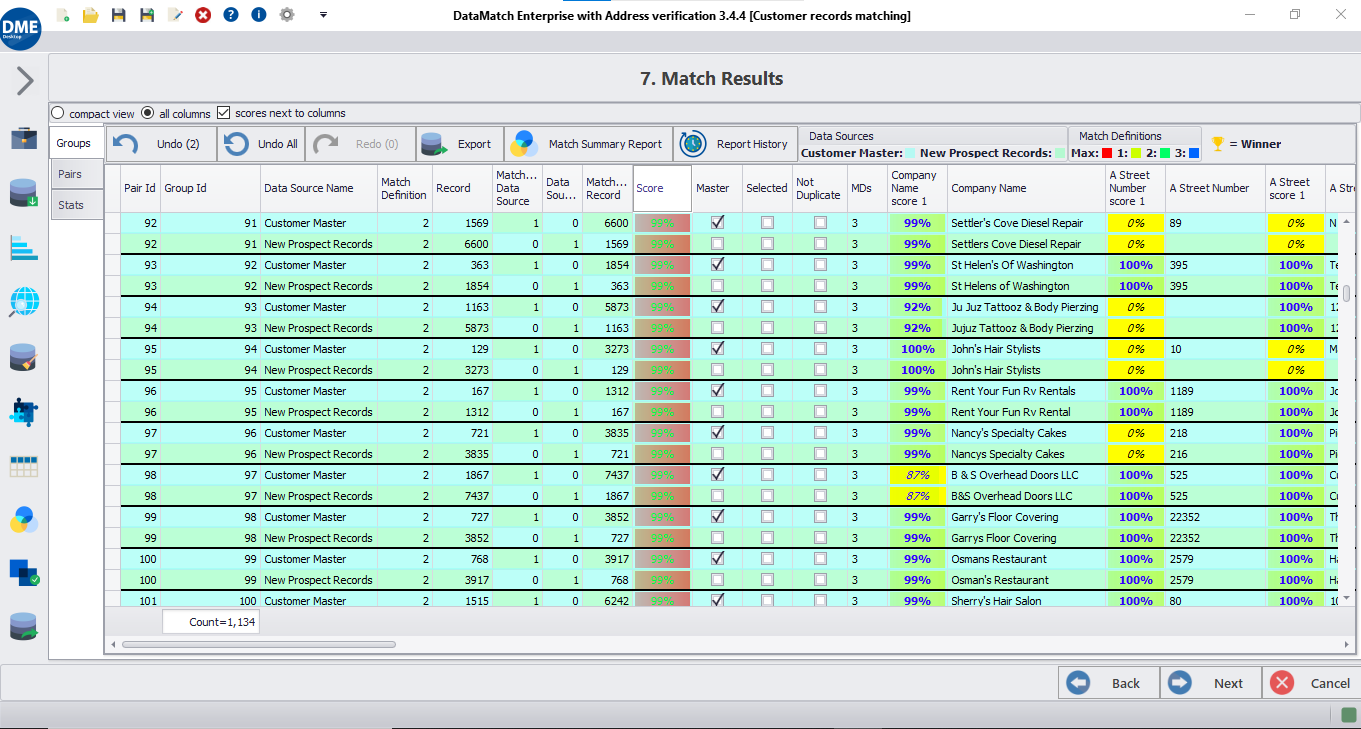
Vinculación de registros de entidades
Cotejar los registros dentro de las bases de datos y entre ellas, e identificar los registros potenciales que se relacionan con la misma entidad. Los conjuntos de datos suelen carecer de atributos estandarizados de identificación única, por lo que puede ser necesaria una combinación de algoritmos inteligentes de coincidencia difusa para aumentar la precisión.