





























Last Updated on April 14, 2022
Jeder Datenexperte wird zustimmen, dass genaue, saubere und konsistente Daten für das Erreichen von Geschäftszielen entscheidend sind. Doch nur eine Handvoll Unternehmen – laut Chief Marketing 16 % – behauptet selbstbewusst, dass ihre Daten einem hohen Standard entsprechen. In der Gartner-Umfrage zu Marketingdaten und -analysen im Jahr 2020 nannten Marketingverantwortliche auf C-Level und leitende Angestellte „schlechte Datenqualität“ als einen der drei Hauptgründe, warum Analysen für die Entscheidungsfindung nicht effektiv sind.
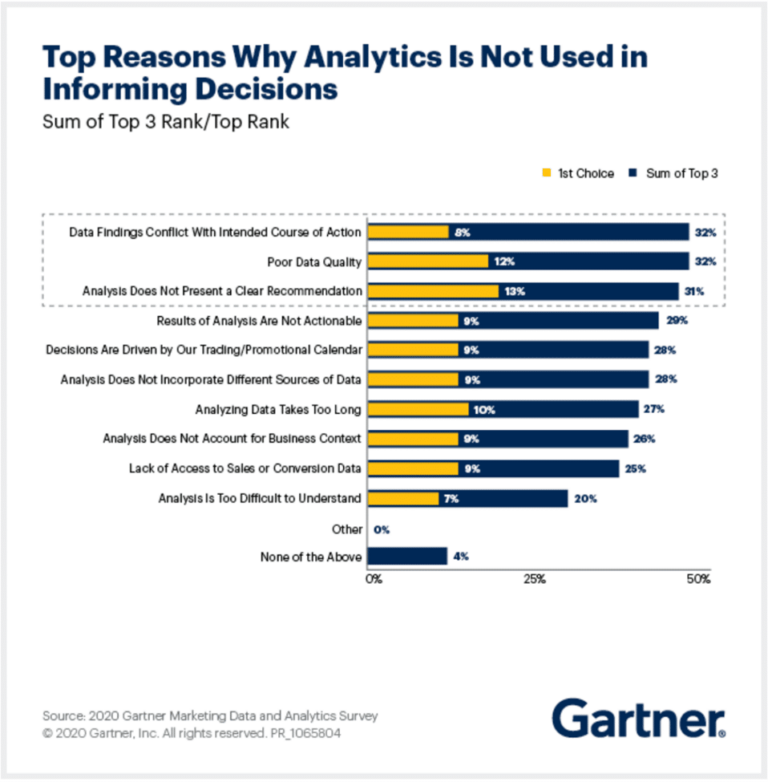
Wie können Unternehmen also die Qualität ihrer Daten im Auge behalten, bevor es zu spät ist? Lassen Sie uns einen Blick auf die Bedeutung der Datenprofilierung werfen und darauf, warum Unternehmen sie als ein notwendiges Instrument für die Datenqualität und das Datenmanagement betrachten sollten.
Was ist Datenprofilierung?
Der Data-Warehouse-Experte Ralph Kimball definiert Datenprofilierung wie folgt:
„Die systematische Vorab-Analyse des Inhalts einer Datenquelle, angefangen beim Zählen der Bytes und der Überprüfung der Kardinalitäten bis hin zu einer sorgfältigen Diagnose, ob die Daten die übergeordneten Ziele des Data Warehouse erfüllen können.“
Mit anderen Worten: Datenprofilierung ist der Prozess der Diagnose des Zustands von Geschäftsdaten, um sicherzustellen, dass sie für die weitere Verarbeitung geeignet sind, z. B. für Analysen, Migration oder Data Warehouse-Zwecke. Sie ist eine Vorstufe zur Datenbereinigung, bei der die in der Datenprofilierungsphase gefundenen Fehler entfernt und bereinigt werden.
Die Erstellung von Datenprofilen ist ein entscheidender Schritt für die Offenlegung der Daten und die Aufdeckung verschiedener Anomalien, die sonst in Form von fehlenden, ungültigen, unvollständigen oder ungenauen Daten verborgen bleiben könnten. Auf diese Weise kann das Unternehmen die Lücken viel besser einschätzen und Maßnahmen zur Bereinigung oder Vernichtung von Daten ergreifen, um negative Auswirkungen zu vermeiden.
Ein Beispiel für einen Anwendungsfall von Data Profiling
Ein etabliertes Bekleidungsunternehmen beschließt, in der Weihnachtszeit eine Newsletter- und Direktmailing-Kampagne durchzuführen, und stellt fest, dass die Kontakte in seinem CRM aus verschiedenen Quellen stammen, die jeweils unterschiedliche Dateneingabe- und Validierungsprüfungen (oder deren Fehlen) aufweisen. Um zu vermeiden, dass die falschen Kontakte erreicht werden und das Risiko von Bounces und fehlgeschlagenen Zustellungen besteht, wird ein Profil der Daten erstellt, um ungültige E-Mails, Duplikate, Zeichensetzungsfehler und andere Probleme zu finden.
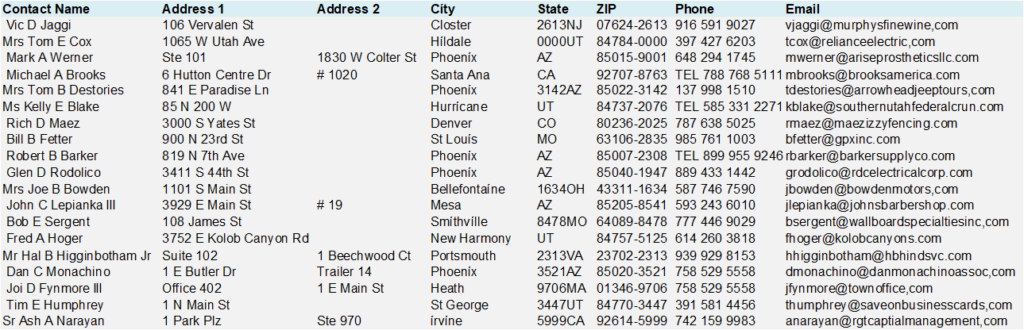
Bei der Durchführung eines Datenprofils auf einer kleinen Teilmenge von Daten kann dies festgestellt werden:
- Das Format der Kontaktnamen und der Adresse ist uneinheitlich
- Mehrere Kontakteinträge bestehen aus führenden Leerzeichen
- Viele Address 2-Datensätze fehlen oder sind unvollständig
- Die Felder Staat und Telefon enthalten Buchstaben und
- E-Mail-Datensätze bestehen aus Satzzeichen (,) und vielem mehr.
Die Anzahl der Fehler, die bei einer so kleinen Teilmenge von Daten gefunden werden, kann ausreichen, um die Leistung der E-Mail- und Direktmailing-Kampagnen des Unternehmens zu beeinträchtigen, was den Umsatz und den Ruf der Marke kostet. Durch die Erstellung von Datenprofilen kann das Unternehmen solche Folgen jedoch abwenden, indem es die Daten bereinigt oder ganz verwirft.
Warum ist Data Profiling für ein Unternehmen von entscheidender Bedeutung?
Die Bedeutung der Erstellung von Datenprofilen ist eng mit der Entdeckung von schlechten und schmutzigen Daten verbunden. Diese können in einer Organisation aus verschiedenen Gründen entstehen, von denen einige folgende sind:
- Fehler bei der Dateneingabe: Jeder von uns kann bei der Eingabe von Informationen Fehler machen, sei es, dass ein Buchstabe fehlt, Rechtschreibfehler, Interpunktionsfehler, falsche Groß- und Kleinschreibung, Duplikate usw.
- Mehrfache Benutzereingaben: Dies kann vorkommen, wenn mehrere Personen auf dasselbe System zugreifen, insbesondere wenn ihnen kein klares Format oder keine Validierung mitgeteilt wird. Beispielsweise kann Benutzer 1 sein Geburtsdatum als TT/MM/JJJJ eingeben, während Benutzer 2 auf MM/TT/JJJJ zurückgreifen kann. Weitere Beispiele sind „NJ“ und „New Jersey“ für den Bundesstaat und „Jon Adams Smith“ und „J.A. Smith“ für den Kontaktnamen.
- Gefälschte Daten: Daten wie Telefonnummern und Unternehmen werden oft gefälscht, um eine Fallstudie herunterzuladen, an einem Webinar teilzunehmen oder sich für einen Produkttest anzumelden. Unternehmen, die keine strengen Datenvalidierungsprüfungen durchführen, können dazu führen, dass sich falsche Daten in der Unternehmensdatenbank ansammeln.
- Systemfehler: Es ist auch möglich, dass die in der Datenbank oder Anwendung gespeicherten Daten aufgrund fehlender eingebauter Redundanz beschädigt werden, da sie mit mehreren Computern und Systemen interagieren. Wenn zum Beispiel ein Datensatz in einer Datenbank aufgrund einer externen Transaktion aktualisiert wird, kann es vorkommen, dass er abgelehnt wird.
Wenn man bedenkt, wie diese Fehler in den Datenbanken, im CRM und in anderen Datenquellen eines Unternehmens auftauchen, kann ein Gesundheitscheck mithilfe der Datenprofilierung einem Unternehmen Warnzeichen für verschiedene Anwendungsfälle geben.
Vertrieb und Marketing
Die Erstellung von Datenprofilen kann aufzeigen, wie sauber die Informationen von Leads und potenziellen Kunden für die Wirksamkeit von Marketing- und Vertriebskampagnen sind. Durch die Identifizierung fehlender E-Mails, Adressen und Telefonnummern kann ein Unternehmen den Versand von Spam-E-Mails, verpasste Postzustellungen und die Zeitverschwendung durch Anrufe von Vertriebsmitarbeitern bei ungültigen Nummern vermeiden.
Betrugsprävention und Compliance
Die Erstellung von Datenprofilen kann auch für die Erstellung von Profilen in nationalen Datenbanken zur Verhinderung von Steuerbetrug oder zur Einhaltung neuer Vorschriften nützlich sein. Im Falle von Steuerbetrug kann das Profiling aufzeigen, bei wie vielen Kontakten Angaben fehlen oder ob die Postleitzahl und die Plus-4-Daten mit der richtigen Feldvalidierung übereinstimmen oder nicht.
Patientenanpassung und Gesundheitswesen
Organisationen des Gesundheitswesens können auch von der Überprüfung des Ausmaßes von Datenfehlern in ihren elektronischen Gesundheitsakten für den Patientenabgleich und andere Anwendungsfälle profitieren. Ein Gesundheitsdienstleister, der über ausreichende Informationen zur Krankengeschichte des Patienten verfügt, ist besser in der Lage, die richtige Diagnose und Behandlung zu stellen.
Finanzen und Bankwesen
Bei der Profilierung von Daten für Banken und Finanzinstitute kann es darum gehen, die Konsistenz von Daten über mehrere Formate und Systeme hinweg zu ermitteln, um eine kohärente Kundensicht zu erhalten.
Gängige Daten-Profiling-Techniken
Es gibt verschiedene Ansätze, die der Erstellung von Datenprofilen zugrunde liegen, z. B:
- Spaltenprofilierung: Durchsuchen der Datentabellen innerhalb einer Spalte, um festzustellen, wie oft ein Datensatz nach Datenmustern wiederholt wird.
- Spaltenübergreifende Profilerstellung: Hierbei werden die über- und untergeordneten Beziehungen zwischen den Spalten durch die Durchführung von Schlüssel- und Abhängigkeitsanalysen identifiziert. Erstere sucht nach Datensätzen innerhalb einer Tabelle, um einen Primärschlüssel zu identifizieren, während letztere nach Datensätzen sucht, die von diesem Primärschlüssel abhängig sind.
- Tabellenübergreifende Profilerstellung: Hierbei wird nach potenziell vorhandenen Fremdschlüsseln sowie nach Redundanzen in Daten und potenziellen Zuordnungen gesucht, indem Unterschiede in der Syntax und den Datentypen untersucht werden.
Herausforderungen der konventionellen Datenprofilierung
So wichtig die Erstellung von Datenprofilen auch ist, die konventionellen Ansätze haben ihre Tücken. Erstens haben die mit der Erstellung von Datenprofilen beauftragten Benutzer oft nicht den vollen Umfang der Daten oder wissen nicht, wie sie für die Entscheidungsfindung verwendet werden. Es ist zum Beispiel unwahrscheinlich, dass ein Dateningenieur weiß, welche Datensätze, die sich auf persönliche oder geschützte Nummern beziehen, korrekt oder inkonsistent sind.
Zweitens kann der Umfang der Daten, insbesondere im Zusammenhang mit Big Data, die Profilerstellung zu einer großen Herausforderung machen. Die Analyse von ungenauen oder unkorrigierten Datensätzen in Millionen von Datensätzen kann entmutigend sein und weit mehr Zeit in Anspruch nehmen, als das Projekt erfordert.
Außerdem können Ausreißer oder Extremwerte bei großen Datenmengen schwer zu erkennen sein. Es ist nicht ungewöhnlich, dass Datensätze Ausreißer enthalten, die die Analysen verzerren können, und die Ermittlung der Anzahl solcher Datensätze bei der manuellen Profilerstellung ist oft eine große Herausforderung.
Durchführen von Daten-Profiling mit DataMatch Enterprise
In Anbetracht der Tatsache, dass die manuelle Profilerstellung mit vielen Einschränkungen verbunden ist, können Datenprofilierungs-Tools wie DataMatch Enterprise (DME ) von Data Ladder eine geeignete Alternative darstellen.
Im Gegensatz zu anderen Datenprofilierungswerkzeugen ist DME mit regulären Ausdrücken (RegEx) ausgestattet, um automatisch gültige und ungültige Muster sowie eine Reihe von Anomalien zu erkennen, wie z. B.:
- Fehlende oder ungültige Werte
- Führende und abschließende Leerzeichen
- Fehler in der Zeichensetzung
- Fehler bei der Groß- und Kleinschreibung, bei der Umkehrung von Großbuchstaben und beim Blocksatz
- Zahlen in Buchstaben und Buchstaben in Zahlen und vieles mehr
Um mit der Erstellung von Datenprofilen mit DME zu beginnen, gehen Sie zunächst auf die Registerkarte PROJEKTVERWALTUNG in der oberen linken Ecke und erstellen Sie ein neues Projekt.
Anschließend sehen Sie das
DATENIMPORT
in dem Sie die relevanten Datenquellen (Excel, Oracle, SQL Server, etc.) für Ihr Projekt importieren.
Nachdem Sie die Datenquellen ausgewählt haben, wählen Sie Profil generieren für jede Quelle, woraufhin DME ein Profil wie hier gezeigt erstellt.
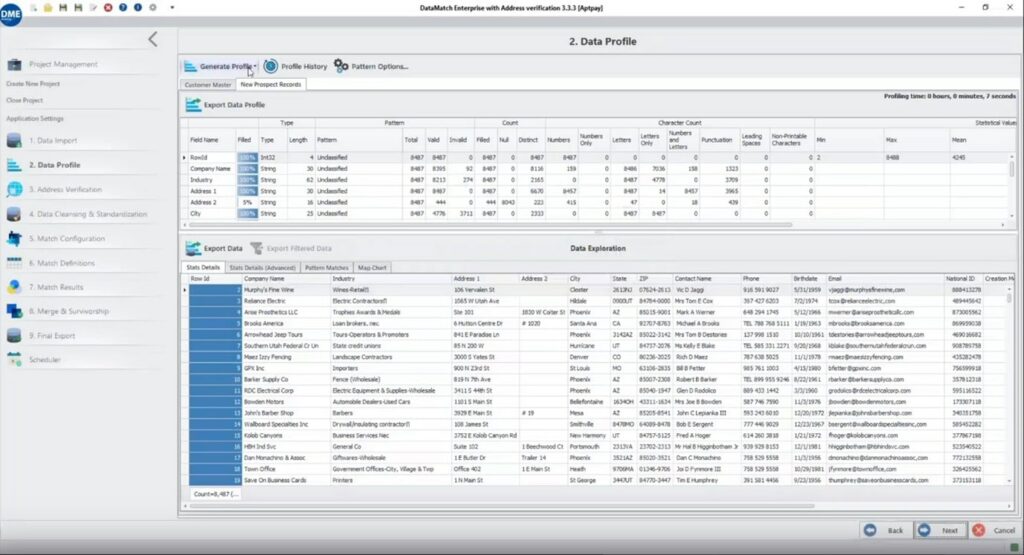
Sie können dann das Datenprofil anhand der erkannten RegEx-Muster genau analysieren, ein eigenes Muster für geschützte Daten erstellen und Datensätze kennzeichnen, die nicht mit Ihren Anforderungen an die Datenvalidierung übereinstimmen.
Wenn Sie mehr darüber erfahren möchten, wie DME ein Profil erstellen und Fehler in Ihren Daten für den Datenabgleich, die Datenmigration und das Data Warehouse finden kann, kontaktieren Sie uns bitte oder laden Sie noch heute eine kostenlose Testversion herunter.



