































Last Updated on December 9, 2025
Any data professional will agree that having accurate, clean, and consistent data is critical for meeting business objectives. And yet, you will hear about only a handful of companies – 16% according to Chief Marketing – confidently claiming that their data conforms to a high standard. In fact, C-level and senior marketing personnel from the 2020 Gartner Marketing Data and Analytics Survey, cited ‘Poor Data Quality’ as one of the top three reasons for why analytics isn’t effective for decision making.
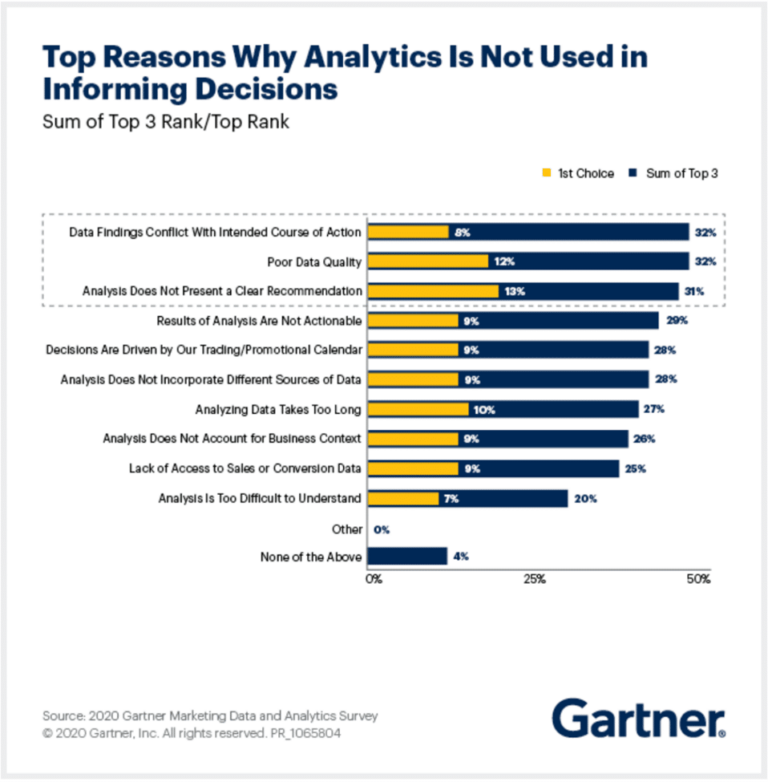
So how can businesses keep track of the quality of their data before it’s too late? Let us look at the importance of data profiling and why businesses should consider it as a necessary instrument for data quality and management.
What is Data Profiling?
Data warehouse expert Ralph Kimball defines data profiling as:
“The systematic up-front analysis of the content of a data source, all the way from counting the bytes and checking cardinalities up to the most thoughtful diagnosis of whether the data can meet the high-level goals of the data warehouse.”
In other words, data profiling is the process of diagnosing the health of business data to ensure it is up to the mark for further processing such as in the case of analytics, migration, or data warehouse purposes. It is a precursor to data cleansing in which the errors found in the data profiling stage are removed and cleaned.
Data profiling forms a crucial step for exposing the data and uncovering various anomalies that could otherwise be hidden in the form of missing, invalid, incomplete, or inaccurate data. By doing so, the company can have a much better assessment of the loopholes and take measures to clean or discard data to avoid any negative repercussions.
An Example of a Data Profiling Use-Case
An established clothing company decides to run a Christmas season newsletter and direct mail campaign and finds that the contacts in its CRM come from multiple sources, each with different data entry and validation checks (or lack of). To avoid reaching out to the wrong contacts and run the risk of hard bounces and failed deliveries, it decides to profile the data to find invalid emails, duplicates, punctuation errors and other problems.
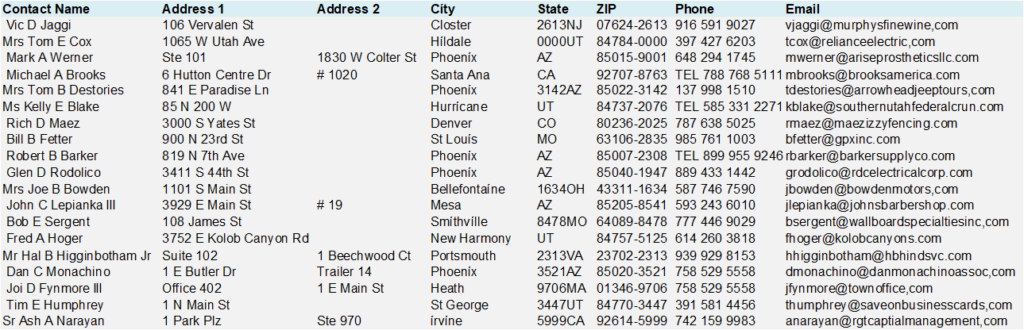
Upon running a data profile on a small subset of data, it can find that:
- The format of contact names and address is inconsistent
- Several contact entries consist of leading spaces
- Many Address 2 records are missing or incomplete
- State and Phone fields contain letters and
- Email records consist of punctuation marks (,) and much more.
Looking at the number of errors found on such a small subset of data can be enough to diminish the company’s email and direct mail campaign performance, costing sales and brand reputation. However, through data profiling the company can avert such consequences by cleaning the data or discarding it altogether.
Why Data Profiling is Critical for an Enterprise?
The importance of data profiling is closely linked with the discovery of bad and dirty data. These can arise in an organization due to several reasons some of which include:
- Data entry errors: these are mistakes any of us can make when entering information either by missing a letter, misspellings, punctuation errors, wrong case, duplicates, and so on.
- Multiple user entries: this can occur due to multiple people accessing the same system especially when a clear format or validation is not communicated to them. For example, user 1 may enter birthdate as DD/MM/YYYY but user 2 may resort to MM/DD/YYYY. Other examples can be ‘NJ’ and ‘New Jersey’ for state and ‘Jon Adams Smith’ and ‘J.A. Smith’ for contact name.
- Falsified data: data such as telephone numbers and company are often faked to download a case study, attend a webinar, or signup for a product trial. Businesses that don’t use stringent data validation checks can cause false data to pile up in the company database.
- System errors: It is also possible for the data residing in the database or application to become corrupted due to a lack of built-in redundancy as it interacts with multiple computers and systems. For example, when a record gets updated in a database due to an external transaction, it is possible sometimes for it to get rejected.
Considering how these errors surface in an organization’s database, CRM, and other data sources, doing a health check-up using data profiling can signal warning signs to a company for different use-cases.
Sales and Marketing
Data profiling can expose how clean the information of leads and prospects are for marketing and sales campaign effectiveness. By identifying missing emails, addresses, and phone numbers, a business can avoid sending spam emails, missed postal deliveries, and time wasted of sales representatives calling invalid numbers.
Fraud Prevention and Compliance
Data profiling can equally be useful for profiling national databases for tax fraud prevention or for compliance with new regulations. In the case of tax fraud, profiling can reveal how many contacts have missing details or whether their ZIP code and plus 4 data conform to the right field validation or not.
Patient Matching and Healthcare
Healthcare organizations also can benefit from checking the extent of data errors of their electronic health records for patient matching and other use-cases. A healthcare provider that has sufficient information on patients’ history will be better equipped to offer the proper diagnosis and treatment.
Finance and Banking
Profiling data for banks and financial institutions can involve identifying the consistency of data across multiple formats and systems for a cohesive customer view.
Common Data Profiling Techniques
There are several approaches that underpin data profiling such as:
- Column profiling: involves looking through the data tables within a column to see the number of times a record is repeated for data patterns.
- Cross-column profiling: this involves identifying the parent and child relationships across columns through performing key and dependency analysis. The former looks at finding records within a table to identify a primary key whereas the latter looks at records that are dependent on that primary key.
- Cross-table profiling: this looks for foreign keys that may potentially exist as well as redundancies in data and potential mappings through examining differences in syntax and data types.
Challenges of Conventional Data Profiling
As important data profiling is, conventional approaches have its fair share of challenges. Firstly, the users tasked with data profiling often don’t have the full scope of data or how it will be utilized for decision making. For example, a data engineer is unlikely to know which records pertaining to personal or proprietary numbers will be accurate or inconsistent.
Secondly, the scale of data, especially in the context of big data, can make profiling extremely challenging. Analyzing inaccurate or uncorrupted records across millions of records can be daunting and take far more time than the project demands.
Also, outliers or extreme values can be difficult to spot across large volumes of data. It is not uncommon to find datasets containing outliers that can skew analyses and identifying the number of such records under manual profiling is often a major challenge.
Performing Data Profiling Using DataMatch Enterprise
Considering that manual profiling is sought with many limitations, data profiling tools such as Data Ladder’s DataMatch Enterprise (DME) can be a suitable alternative.
Unlike other data profiling tools, DME comes equipped with regular expressions (RegEx) patterns to automatically detect valid and invalid patterns as well as a range of anomalies such as:
- Missing or null values
- Leading and trailing spaces
- Errors in punctuation
- Lower case, reversal, and Block capitals case errors
- Numbers in letters and letters in numbers and much more
To get started with data profiling using DME, first go to the PROJECT MANAGEMENT tab on the upper left corner and create a new project.
Afterwards, you will see the DATA IMPORT module in where you import the relevant data sources (Excel, Oracle, SQL Server, etc.) for your project.
After choosing the data sources, select Generate Profile for each source after which DME will build a profile as shown here.
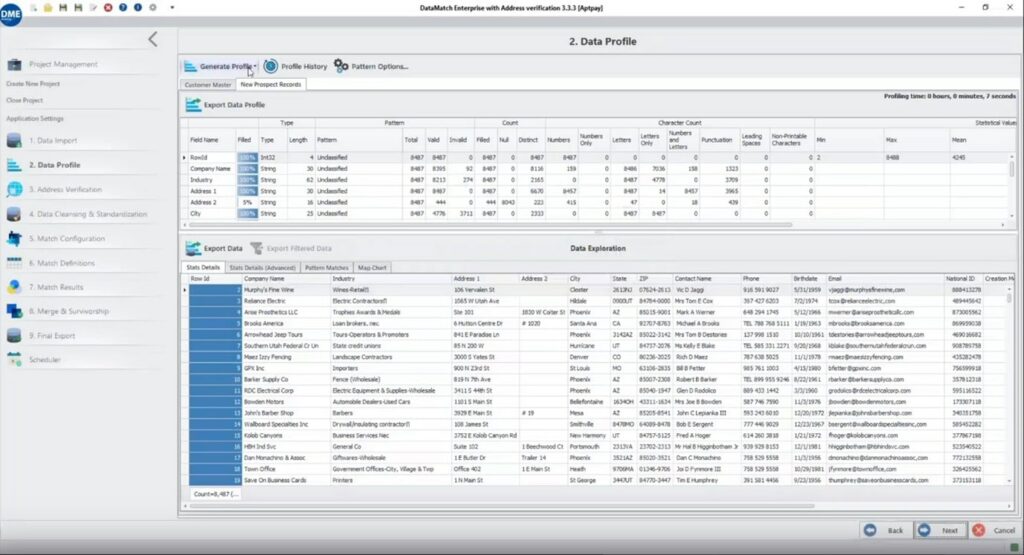
You can then closely analyze the data profile in accordance with the RegEx patterns it detects, create a pattern of your own for proprietary data, and flag records that are not in conformity with your data validation requirements.
For more information on how DME can profile and find errors in your data for data matching, data migration and data warehouse needs, please contact us or download free trial today.

