





























Last Updated on mars 25, 2022
Tout professionnel des données conviendra qu’il est essentiel de disposer de données précises, propres et cohérentes pour atteindre les objectifs de l’entreprise. Et pourtant, vous n’entendrez parler que d’une poignée d’entreprises – 16 % selon Chief Marketing – affirmant avec confiance que leurs données sont conformes à une norme élevée. En fait, le personnel de niveau C et le personnel marketing senior de l’enquête 2020 de Gartner sur les données et les analyses marketing ont cité la « mauvaise qualité des données » comme l’une des trois principales raisons pour lesquelles l’analyse n’est pas efficace pour la prise de décision.
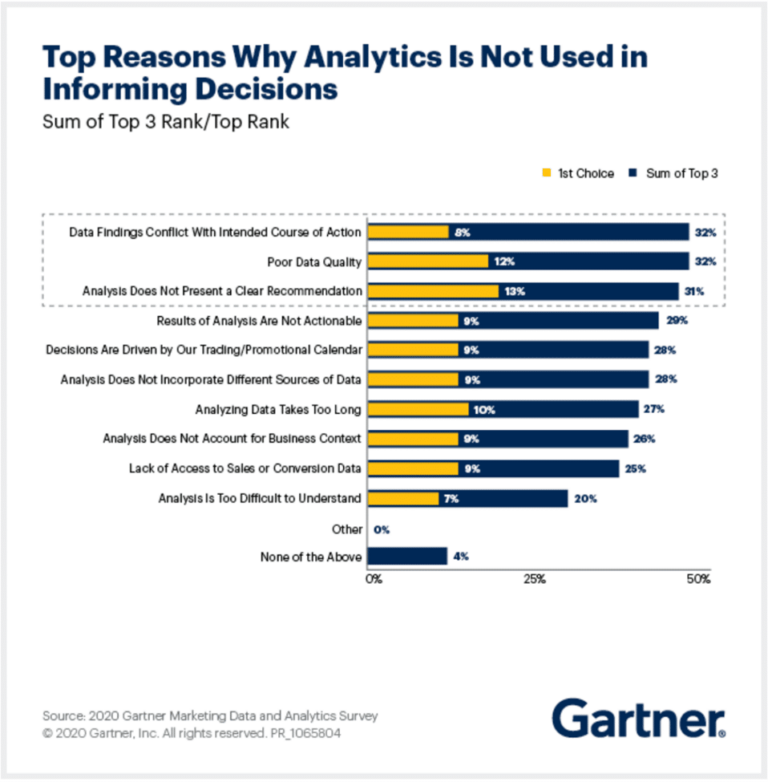
Alors comment les entreprises peuvent-elles s’assurer de la qualité de leurs données avant qu’il ne soit trop tard ? Examinons l’importance du profilage des données et pourquoi les entreprises devraient le considérer comme un instrument nécessaire à la qualité et à la gestion des données.
Qu’est-ce que le profilage des données ?
Ralph Kimball, expert en entrepôts de données, définit le profilage des données comme suit :
« L’analyse systématique en amont du contenu d’une source de données, depuis le comptage des octets et la vérification des cardinalités jusqu’au diagnostic le plus réfléchi pour savoir si les données peuvent répondre aux objectifs de haut niveau de l’entrepôt de données. »
En d’autres termes, le profilage des données est le processus qui consiste à diagnostiquer la santé des données d’entreprise afin de s’assurer qu’elles sont à la hauteur pour un traitement ultérieur, comme dans le cas de l’analyse, de la migration ou de l’entrepôt de données. Il s’agit d’un précurseur du nettoyage des données, au cours duquel les erreurs découvertes lors de l’étape de profilage des données sont supprimées et nettoyées.
Le profilage des données constitue une étape cruciale pour exposer les données et découvrir diverses anomalies qui pourraient autrement être cachées sous la forme de données manquantes, invalides, incomplètes ou inexactes. Ce faisant, l’entreprise peut avoir une bien meilleure évaluation des failles et prendre des mesures pour nettoyer ou éliminer les données afin d’éviter toute répercussion négative.
Un exemple de cas d’utilisation du profilage des données
Une entreprise de vêtements bien établie décide de lancer une lettre d’information et une campagne de publipostage à l’occasion de la période de Noël. Elle constate que les contacts contenus dans son système de gestion de la relation client proviennent de plusieurs sources, chacune ayant des contrôles de saisie et de validation différents (ou l’absence de contrôle). Pour éviter d’atteindre les mauvais contacts et de courir le risque de rebonds et d’échecs de livraison, il décide de profiler les données pour trouver les courriels invalides, les doublons, les erreurs de ponctuation et autres problèmes.
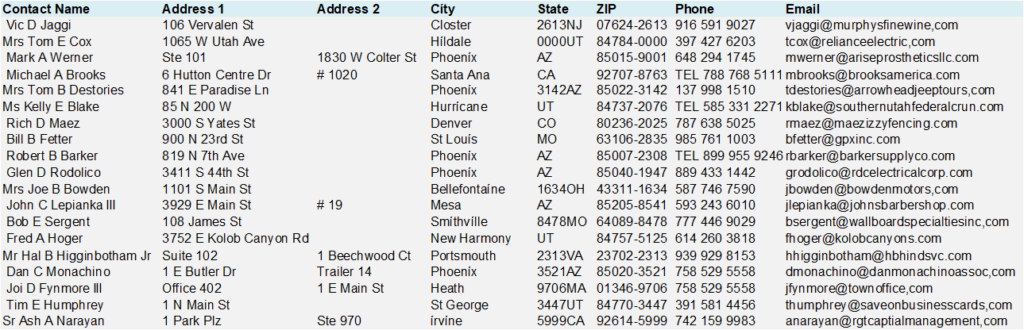
En exécutant un profil de données sur un petit sous-ensemble de données, il peut trouver que :
- Le format des noms et adresses de contact n’est pas cohérent.
- Plusieurs entrées de contact sont constituées d’espaces de tête
- De nombreux enregistrements de l’adresse 2 sont manquants ou incomplets
- Les champs État et Téléphone contiennent des lettres et
- Les enregistrements de courriels sont constitués de signes de ponctuation (,) et bien plus encore.
Le nombre d’erreurs trouvées sur un si petit sous-ensemble de données peut suffire à diminuer les performances des campagnes de courrier électronique et de publipostage de l’entreprise, entraînant des pertes de ventes et de réputation de la marque. Toutefois, grâce au profilage des données, l’entreprise peut éviter de telles conséquences en nettoyant les données ou en les supprimant complètement.
Pourquoi le profilage des données est-il essentiel pour une entreprise ?
L’importance de l’établissement du profil des données est étroitement liée à la découverte de données mauvaises et sales. Ces problèmes peuvent survenir dans une organisation pour diverses raisons, dont les suivantes
- Erreurs de saisie des données : il s’agit d’erreurs que chacun d’entre nous peut commettre lors de la saisie d’informations, qu’il s’agisse d’une lettre manquante, d’une faute d’orthographe ou de ponctuation, d’une erreur de casse, de doublons, etc.
- Entrées multiples d’utilisateurs : cela peut se produire lorsque plusieurs personnes accèdent au même système, surtout si un format ou une validation clairs ne leur sont pas communiqués. Par exemple, l’utilisateur 1 peut saisir sa date de naissance sous la forme JJ/MM/AAAA, mais l’utilisateur 2 peut opter pour MM/JJ/AAAA. D’autres exemples peuvent être « NJ » et « New Jersey » pour l’état et « Jon Adams Smith » et « J.A. Smith » pour le nom du contact.
- Données falsifiées : des données telles que les numéros de téléphone et l’entreprise sont souvent falsifiées pour télécharger une étude de cas, participer à un webinaire ou s’inscrire à l’essai d’un produit. Les entreprises qui n’utilisent pas de contrôles rigoureux de la validation des données risquent d’accumuler des données erronées dans la base de données de l’entreprise.
- Erreurs de système : Il est également possible que les données résidant dans la base de données ou l’application soient corrompues en raison d’un manque de redondance intégrée lors de l’interaction avec plusieurs ordinateurs et systèmes. Par exemple, lorsqu’un enregistrement est mis à jour dans une base de données en raison d’une transaction externe, il est parfois possible qu’il soit rejeté.
Compte tenu de la manière dont ces erreurs apparaissent dans les bases de données, les systèmes de gestion de la relation client (CRM) et d’autres sources de données d’une organisation, un bilan de santé effectué à l’aide du profilage des données peut signaler des signes d’alerte à une entreprise pour différents cas d’utilisation.
Ventes et marketing
Le profilage des données peut révéler dans quelle mesure les informations des prospects et des clients potentiels sont propres pour l’efficacité des campagnes de marketing et de vente. En identifiant les courriels, adresses et numéros de téléphone manquants, une entreprise peut éviter l’envoi de courriels non sollicités, les livraisons postales manquées et la perte de temps des représentants commerciaux qui appellent des numéros non valides.
Prévention de la fraude et conformité
Le profilage des données peut également être utile pour profiler les bases de données nationales afin de prévenir la fraude fiscale ou de se conformer à de nouvelles réglementations. Dans le cas de la fraude fiscale, le profilage peut révéler combien de contacts ont des détails manquants ou si leur code postal et leurs données plus 4 sont conformes ou non à la bonne validation de champ.
Appariement des patients et soins de santé
Les organismes de soins de santé peuvent également tirer profit de la vérification de l’étendue des erreurs de données de leurs dossiers médicaux électroniques pour le rapprochement des patients et d’autres cas d’utilisation. Un prestataire de soins de santé qui dispose d’informations suffisantes sur les antécédents des patients sera mieux à même de proposer un diagnostic et un traitement appropriés.
Finance et banque
Le profilage des données pour les banques et les institutions financières peut impliquer l’identification de la cohérence des données à travers plusieurs formats et systèmes pour une vue cohérente du client.
Techniques courantes de profilage des données
Il existe plusieurs approches qui sous-tendent le profilage des données, telles que :
- Profilage de colonne : consiste à examiner les tableaux de données d’une colonne pour voir le nombre de fois qu’un enregistrement est répété pour trouver des modèles de données.
- Profilage inter-colonnes : il s’agit d’identifier les relations parents-enfants entre les colonnes en effectuant une analyse des clés et des dépendances. La première consiste à trouver des enregistrements dans une table pour identifier une clé primaire, tandis que la seconde s’intéresse aux enregistrements qui dépendent de cette clé primaire.
- Profilage inter-table : il s’agit de rechercher les clés étrangères qui pourraient exister, ainsi que les redondances dans les données et les mappings potentiels en examinant les différences de syntaxe et de types de données.
Les défis du profilage conventionnel des données
Aussi important que soit le profilage des données, les approches conventionnelles comportent leur lot de difficultés. Tout d’abord, les utilisateurs chargés du profilage des données n’ont souvent pas une vue d’ensemble des données ni de la manière dont elles seront utilisées pour la prise de décision. Par exemple, il est peu probable qu’un ingénieur des données sache quels enregistrements relatifs à des numéros personnels ou exclusifs seront exacts ou incohérents.
Deuxièmement, l’échelle des données, notamment dans le contexte du big data, peut rendre le profilage extrêmement difficile. L’analyse de millions d’enregistrements inexacts ou non peut être décourageante et prendre beaucoup plus de temps que ce que le projet exige.
En outre, les valeurs aberrantes ou extrêmes peuvent être difficiles à repérer dans de grands volumes de données. Il n’est pas rare de trouver des ensembles de données contenant des valeurs aberrantes qui peuvent fausser les analyses et l’identification du nombre de ces enregistrements dans le cadre du profilage manuel est souvent un défi majeur.
Exécution du profilage des données à l’aide de DataMatch Enterprise
Considérant que le profilage manuel est recherché avec de nombreuses limitations, les outils de profilage de données tels que DataMatch Enterprise (DME ) de Data Ladder peuvent être une alternative appropriée.
Contrairement à d’autres outils de profilage des données, DME est équipé de modèles d’expressions régulières (RegEx) pour détecter automatiquement les modèles valides et invalides ainsi qu’une série d’anomalies telles que :
- Valeurs manquantes ou nulles
- Espaces de début et de fin de ligne
- Erreurs de ponctuation
- Erreurs de minuscules, d’inversion et de majuscules de bloc
- Des chiffres dans des lettres et des lettres dans des chiffres et bien plus encore
Pour commencer à établir des profils de données à l’aide de DME, allez d’abord à l’onglet GESTION DE PROJET dans le coin supérieur gauche et créez un nouveau projet.
Ensuite, vous verrez le module
IMPORTATION DE DONNÉES
dans lequel vous importez les sources de données pertinentes (Excel, Oracle, SQL Server, etc.) pour votre projet.
Après avoir choisi les sources de données, sélectionnez Générer un profil pour chaque source, après quoi DME créera un profil comme illustré ici.
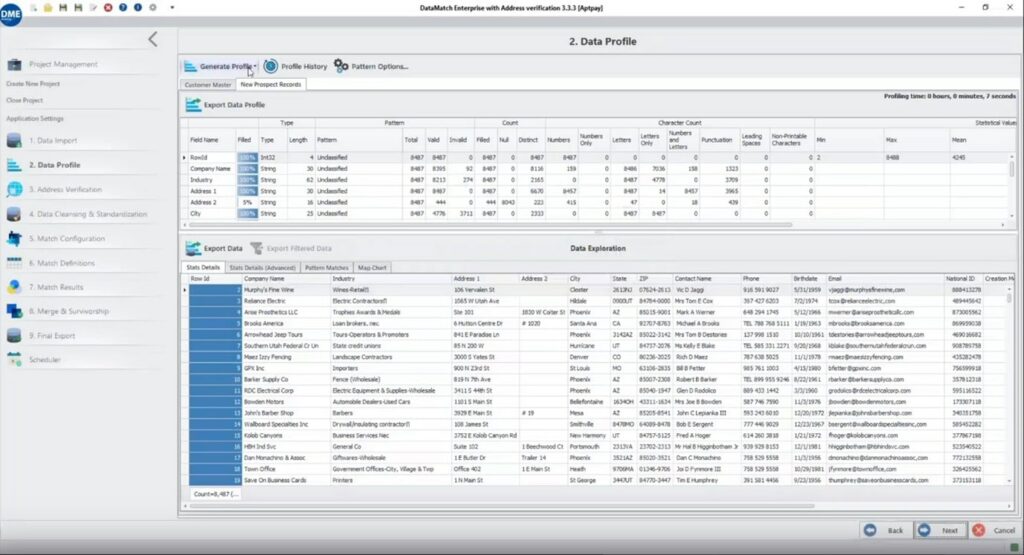
Vous pouvez ensuite analyser de près le profil des données en fonction des modèles RegEx qu’il détecte, créer votre propre modèle pour les données propriétaires et signaler les enregistrements qui ne sont pas conformes à vos exigences en matière de validation des données.
Pour plus d’informations sur la façon dont DME peut profiler et trouver des erreurs dans vos données pour les besoins de rapprochement, de migration et d’entrepôt de données, veuillez nous contacter ou télécharger l’essai gratuit dès aujourd’hui.



