





























Last Updated on Januar 1, 2026
Wenn Ihnen der Gedanke an einen Adressabgleich über ein halbes Dutzend Quellen hinweg schon einmal in den Sinn gekommen ist, wissen Sie, dass dies alles andere als ein Spaziergang ist. Sie haben Tausende (wenn nicht sogar Millionen) von Adressen in PDF-Dateien, Excel-Dateien und Datenbanken gespeichert, von denen die meisten keinem bestimmten Format zuzuordnen sind. Sie verbringen viele frustrierende Stunden damit, Datensätze zu verknüpfen, aber – und das ist das Schlimmste – Ihre manuellen Eingaben verschlimmern die Datenfehler und lassen Sie weiter im Chaos versinken.
So wichtig saubere Adresslisten für Ihren allgemeinen Geschäftsbedarf auch sind, ein qualitativ hochwertiger Adressabgleich mit Fuzzy-Algorithmen kann sich als weitaus effektivere Methode erweisen. Sehen wir uns an, warum das so ist.
Was ist der Adressabgleich?
Der Adressabgleich (auch Adressgeokodierung genannt) ist der Prozess der Bestimmung räumlicher Standortdetails in Form von Standortkoordinaten (z. B. Längen- und Breitengrad, UTM, lokale Koordinaten, Landesebene usw.) für eine bestimmte Adresse. Beim Adressabgleich können beispielsweise die Felder Adresse, Ort, Bundesland und Postleitzahl verwendet werden, um Plus 4, die Prüfziffer des Zustellpunkts, den Geocode Breitengrad und den Geocode Längengrad zu ermitteln (siehe Abbildung 1).
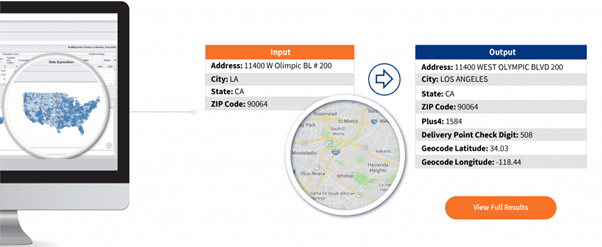
Beim Abgleich werden die in einer Datenquelle gespeicherten Adressen mit einem räumlichen Referenzdatensatz (z. B. Postleitzahlen, Straßen, Flurstücke, Städte usw.) abgeglichen. Die Adressen werden in kleinere Inkremente zerlegt, die dann mit den Adressangaben im Referenzdatensatz verglichen werden.
Sobald die Adresse mit den räumlichen Referenzdaten abgeglichen ist, wird sie interpoliert oder ihr werden Kartenkoordinaten durch einen Schätzwert zugewiesen.
Bei großen Unternehmen und Konzernen kann dies bis zum Abgleich von Adressen aus verschiedenen Datenquellen gehen, um redundante und doppelte Adressen zu identifizieren und eine einheitliche Kundensicht zu ermitteln.
Anwendungen des Adressabgleichs
Der Adressabgleich wird von Unternehmen in einem breiten Spektrum von Branchen genutzt, von Marketing und Immobilien bis hin zu Polizei und Schulen. Hier sind einige Beispiele:
- Marketing-Analyse für ein Servicegebiet: Ein Lieferservice-Unternehmen möchte die Straßen mit den meisten Bestellungen kennen, um den Lieferradius um bestimmte Ortscluster zu minimieren.
- Analyse der Kriminalität nach Ort: Eine Polizeibehörde kann prüfen, an welchen Orten innerhalb und außerhalb der Stadt die höchsten Kriminalitätsraten zu verzeichnen sind, um die Haushalts- und Personalressourcen entsprechend zu verteilen.
- Verwaltung von Kundendaten: Unternehmen, die sich dazu entschließen, in eine ganzheitliche Sicht auf ihre Kunden zu investieren, von Details wie dem Kaufverhalten bis hin zu demografischen Informationen wie Straße, Adresse und Standort, die alle zur Segmentierung verwendet werden können.
- Busse für Schulkinder: Auch für Schulen ist der Adressabgleich nützlich, um die Anzahl der Busse für alle schulpflichtigen Kinder zu ermitteln.
Deterministischer Adressabgleich
Der Adressabgleich ist wie jede andere Art des Datenabgleichs von deterministischem und probabilistischem Abgleich abhängig, um eine hohe Treffergenauigkeit zu erzielen (siehe Abbildung 2).
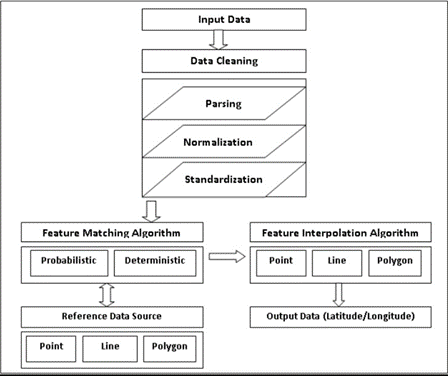
Deterministischer oder exakter Abgleich ist in der Regel nicht sehr zuverlässig, da Tippfehler, Rechtschreibfehler, Leerzeichen am Ende und am Anfang sowie andere Anomalien verhindern können, dass zwei ansonsten ähnliche Datensätze genau übereinstimmen. Obwohl Adresslokatoren, die die Parameter für die Interpretation und den Abgleich von Adressdaten definieren, um die Interpolationswerte zu maximieren, eine optimale Vorgehensweise darstellen, bleibt das Problem des exakten Abgleichs bestehen.
Unterschiedliche Adressformate und Adressen ohne feste Reihenfolge erschweren den Adressabgleich. Relative Adressen im Vergleich zu absoluten Adressen können die Suche nach exakten Übereinstimmungen sehr viel schwieriger und zeitaufwändiger machen.
Ein Beispiel für eine absolute Adresse kann sein:
11400 West Olympic Boulevard 200
122 Main Street, New York, NY 10030
Eine relative Adresse hingegen kann sein:
Gegenüber dem Einkaufszentrum
Auf der anderen Straßenseite
Hinter dem Haupt-Wahrzeichen
Beim deterministischen Abgleich werden relative Adressen wie die oben gezeigte nicht exakt mit den verwendeten Referenzdaten, die aus anderen räumlichen Orten bestehen, abgeglichen.
Wie unterscheidet sich der Fuzzy-Adressabgleich?
Fuzzy-Logik oder Fuzzy-Matching ist eine Reihe von Algorithmen, die es ermöglichen, Adressen auf der Grundlage von Wahrscheinlichkeiten abzugleichen und nicht auf der Grundlage von Ja oder Nein.
Das bedeutet, dass auch auf den ersten Blick fehlerhafte Adressen mit leicht abweichendem Wortlaut eine Chance auf einen Abgleich haben, anders als beim deterministischen oder exakten Adressabgleich.
Algorithmen wie die Levensthein-Distanz, die Damerau-Levenshtein-Distanz und andere helfen dabei, Relevanz festzustellen und nicht exakte Übereinstimmungen viel genauer zu finden.
Vorteile des Fuzzy-Adressabgleichs
Da Fuzzy-Logik-Algorithmen auf probabilistischem Abgleich beruhen, bieten sie mehrere Vorteile für den Adressabgleich in Unternehmen. Dazu gehören:
Bessere Abgleichsgenauigkeit: Fuzzy-Algorithmen bieten eine höhere Abgleichsgenauigkeit, indem sie Adressinformationen wie Wohnungsnummern und Richtungsangaben mit anderen Adressdaten verknüpfen, die bei einem exakten Abgleich sonst völlig übersehen würden.
Berücksichtigung von Formatierungs- und Rechtschreibfehlern: Fuzzy-Algorithmen berücksichtigen beim Abgleich auch Adressdaten mit mehreren Anomalien. Für „Main Street“ können beispielsweise auch Adressen mit Tippfehlern (z. B. Man Street), Umkehrungen (z. B. Niam Street) und führenden Leerzeichen (z. B. Main Street) erfasst und abgeglichen werden, um eine bessere Adressstandardisierung zu erreichen.
Nützlich bei Fehlen eines eindeutigen Identifikators: Im Gegensatz zum exakten Abgleich, der einen eindeutigen Identifikator erfordert (z. B. SSN oder E-Mail), ist der unscharfe Abgleich weitaus praktischer, wenn es um Daten ohne konsistente eindeutige Identifikatordaten geht.
Einschränkungen des Fuzzy-Adressabgleichs
So vorteilhaft Fuzzy Matching auch ist, es hat auch seine Nachteile und Einschränkungen. Einige davon sind:
Adressen mit phonetischen Variationen werden nicht erkannt: phonetische Variationen wie Main Street vs. Mane Street können von Fuzzy-Algorithmen nicht erkannt werden. Dies kann ein Problem sein, da viele Adressdaten nach ihrem Klang und nicht nach ihrer tatsächlichen Schreibweise geschrieben werden.
Kann fehlerhafte Variationen in Übereinstimmungen erkennen: Es ist zwar nützlich, Übereinstimmungen mit leichten Tippfehlern und anderen Variationen zu erkennen, aber es kann auch falsch-positive Treffer enthalten (z. B. Maple Street und Staple Street), die falsch zugeordnet sind.
Wie DataMatch Enterprise den Fuzzy-Adressabgleich nutzt
DataMatch Enterprise (DME ) von Data Ladder ist eine CASS-zertifizierte Lösung für den Adressabgleich, die eine breite Palette von Fuzzy-Matching-Algorithmen (z. B. Levensthein-Distanz, Damerau-Levenshtein-Distanz, Jaro-Wrinkler-Distanz, Jaccard-Index usw.) zusammen mit phonetischem Abgleich verwendet, um eine höhere Treffergenauigkeit zu erzielen.
DME zerlegt die Adressdaten in verschiedene kleinere Einheiten, wie z. B. Straßennummer, Name, Stadtname und andere Details, die mit der USPS-Datenbank abgeglichen werden, um die Adressen zu überprüfen und zu standardisieren.
Weitere Informationen über DME finden Sie unter Adressabgleich oder kontaktieren Sie uns für weitere Informationen.

Wie die besten Fuzzy-Matching-Lösungen funktionieren: Kombination von bewährten und eigenen Algorithmen
Starten Sie noch heute Ihren kostenlosen Test



