




























Last Updated on enero 1, 2026
Si la idea de cotejar las direcciones de media docena de fuentes se le ha pasado por la cabeza alguna vez, sabrá que es cualquier cosa menos un paseo por el parque. Tienes miles (si no millones) de direcciones almacenadas en PDFs, archivos de Excel, bases de datos – la mayor parte de las cuales no corresponden a ningún formato específico. Usted pasa largas y frustrantes horas para vincular los registros, pero -para colmo de males- sus esfuerzos de introducción manual agravan los errores de datos, ahogándole aún más en el caos.
Por muy importantes que sean las listas de direcciones limpias para sus necesidades empresariales más amplias, la comparación de direcciones de calidad mediante algoritmos difusos puede resultar un método mucho más eficaz. Veamos por qué es así.
¿Qué es la concordancia de direcciones?
El cotejo de direcciones (también conocido como geocodificación de direcciones) es el proceso de determinar los detalles de la ubicación espacial en forma de coordenadas de localización (por ejemplo, longitud y latitud, UTM, local, plano del Estado y más) para una dirección dada. Por ejemplo, la coincidencia de direcciones puede utilizar los campos Dirección, Ciudad, Estado y Código postal para obtener el Plus 4, el Dígito de control del punto de entrega, la Latitud de geocodificación y la Longitud de geocodificación, tal y como se muestra en la Figura 1.
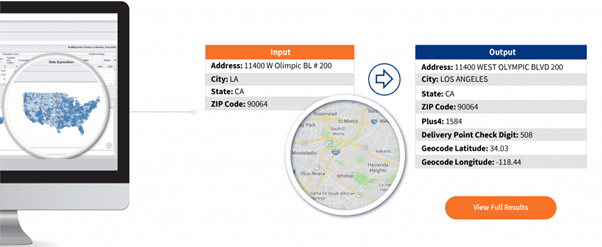
La parte de cotejo consiste en cotejar las direcciones almacenadas en una fuente de datos con un conjunto de datos de referencia espacial (como códigos postales, calles, parcelas, ciudad, etc.). Las direcciones se analizan en incrementos más pequeños que luego se comparan con los detalles de las direcciones en el conjunto de datos de referencia.
Una vez que la dirección coincide con los datos de referencia espacial, se interpola o se le asignan coordenadas cartográficas mediante un valor estimado.
En el caso de los grandes negocios y empresas, esto puede extenderse a la coincidencia de direcciones a través de fuentes de datos dispares para identificar las direcciones redundantes y duplicadas para determinar una visión única del cliente.
Aplicaciones de la concordancia de direcciones
El cotejo de direcciones es utilizado por empresas de un amplio espectro de sectores, desde el marketing y el sector inmobiliario hasta la policía y las escuelas. He aquí algunos ejemplos:
- Análisis de marketing para el área de servicio: Una empresa de servicios de entrega quiere conocer las calles con más pedidos para minimizar el radio de entrega en torno a grupos de localidades específicas.
- Análisis de la delincuencia por localidades: Un departamento de policía puede querer comprobar qué lugares dentro y fuera de las ciudades tienen los mayores índices de delincuencia para asignar los recursos presupuestarios y de personal en consecuencia.
- Gestión de los datos de los clientes: Las empresas que deciden invertir en una visión holística de sus clientes, desde detalles como los patrones de compra hasta la información demográfica, incluyendo la calle, la dirección y la ubicación, todo lo cual puede utilizar para la segmentación.
- Autobuses para escolares: los colegios también encontrarán útil el cotejo de direcciones para identificar el número de autobuses para todos los escolares.
Correspondencia de direcciones determinista
El cotejo de direcciones, como cualquier otro tipo de cotejo de datos, depende del cotejo determinista y probabilístico para obtener una alta precisión de cotejo, como se muestra en la Figura 2.
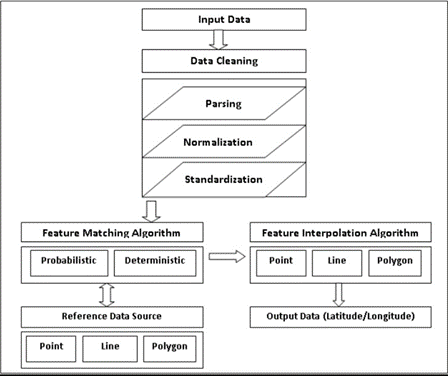
Las coincidencias deterministas o exactas no suelen ser muy fiables, ya que las erratas, los errores ortográficos, los espacios al final y al principio y otras anomalías pueden impedir que dos registros, por lo demás similares, coincidan con exactitud. Aunque los localizadores de direcciones que definen los parámetros para interpretar y hacer coincidir los datos de las direcciones con el fin de maximizar los valores de interpolación es una buena práctica, sigue existiendo el problema de la coincidencia exacta.
El caso de los formatos de dirección variados y de las direcciones sin orden establecido complica el cotejo de direcciones. Las direcciones relativas, en comparación con las absolutas, pueden hacer que la búsqueda de coincidencias exactas sea mucho más difícil y lenta.
Un ejemplo de dirección absoluta puede ser:
11400 West Olympic Boulevard 200
122 Main Street, Nueva York, NY 10030
Una dirección relativa, en cambio, puede serlo:
Frente al centro comercial de la ciudad
Al otro lado de la calle
Detrás del hito principal
En el caso de la concordancia determinista, las direcciones relativas como la mostrada anteriormente no se cotejarán exactamente con los datos de referencia utilizados que consisten en otras ubicaciones espaciales.
¿En qué se diferencia la concordancia de direcciones difusa?
La lógica difusa o fuzzy matching es un conjunto de algoritmos que permiten hacer coincidir las direcciones basándose en la probabilidad y no en una lógica de sí o no.
Esto significa que incluso las direcciones con una ligera variación en la redacción que parecería incorrecta a primera vista tienen una oportunidad de ser emparejadas, a diferencia de lo que ocurre en el caso de la coincidencia de direcciones determinista o exacta.
Algoritmos como la distancia Levensthein, la distancia Damerau-Levenshtein y otros ayudan a establecer la relevancia y a encontrar coincidencias no exactas con mucha más precisión.
Ventajas de la concordancia de direcciones difusa
Como los algoritmos de lógica difusa se basan en la concordancia probabilística, son varias las ventajas que puede ofrecer para abordar la concordancia en las empresas. Entre ellas se encuentran:
Mayor precisión de las coincidencias: los algoritmos difusos proporcionan una mayor precisión de las coincidencias al vincular la información de las direcciones, como los números de los apartamentos y las direcciones, con otros datos de las direcciones que, de otro modo, se perderían por completo utilizando la coincidencia exacta.
Tiene en cuenta los errores de formato y las faltas de ortografía: los algoritmos difusos también tienen en cuenta la información de las direcciones con múltiples anomalías para su cotejo. Por ejemplo, en el caso de «Main Street», las direcciones que contengan errores tipográficos (por ejemplo, Man Street), inversiones (por ejemplo, Niam Street) y espacios iniciales (por ejemplo, Main Street) también pueden recogerse y cotejarse para una mejor normalización de las direcciones.
Útil en ausencia de un identificador único: a diferencia de la concordancia exacta que requiere un identificador único (como el SSN o el correo electrónico para ser consistente), la concordancia difusa es mucho más práctica cuando se trata de datos sin ningún dato identificador único consistente.
Limitaciones de la comparación de direcciones difusa
Por muy beneficioso que sea el emparejamiento difuso, tiene su parte de inconvenientes y limitaciones. Algunas de ellas son:
No detecta las direcciones con variaciones fonéticas: las variaciones fonéticas, como la calle principal frente a la calle Mane, no pueden ser detectadas por los algoritmos difusos. Esto puede ser un problema, ya que muchos deletrean la información de la dirección basándose en lo que suena y no en su ortografía real.
Puede detectar variaciones incorrectas en las coincidencias: aunque es útil para detectar coincidencias con ligeras erratas y otras variaciones, también puede incluir falsos positivos (por ejemplo, la calle Maple y la calle Staple) que son erróneos en su coincidencia.
Cómo utiliza DataMatch Enterprise la concordancia de direcciones difusa
Data Ladder’s DataMatch Enterprise (DME) es una solución de cotejo de direcciones con certificación CASS que utiliza una amplia gama de algoritmos de cotejo difusos (por ejemplo, distancia Levensthein, distancia Damerau-Levenshtein, distancia Jaro-Wrinkler, índice Jaccard, etc.) junto con el cotejo fonético para establecer una mayor precisión de cotejo.
El ISD analiza los datos de las direcciones en diferentes incrementos más pequeños, como el número de la calle, el nombre, el nombre de la ciudad y otros detalles que coteja con su base de datos de USPS para la verificación y normalización de las direcciones.
Si desea más información sobre el ISD, consulte la sección de coincidencia de direcciones o póngase en contacto con nosotros para cualquier consulta.

Cómo funcionan las mejores soluciones de concordancia difusa de su clase: Combinando algoritmos establecidos y propios
Inicie su prueba gratuita hoy mismo



