































Last Updated on December 23, 2025
If the thought of address matching across half a dozen sources has crossed your mind before, you know it is anything but a walk in the park. You have thousands (if not millions) of addresses stored across PDFs, Excel files, databases – the bulk of which do not fall in any specific format. You spend long frustrating hours to link records, but – to add insult to injury – your manual input efforts exacerbate data errors, further drowning you in chaos.
As important clean address lists are for your wider business needs, quality address matching using fuzzy algorithms can prove to be a far more effective method. Let us look at why this is so.
What is Address Matching?
Address matching (also known as address geocoding) is the process of determining spatial location details in the form of location coordinates (e.g. longitude and latitude, UTM, local, State plane and more) for a given address. For example, address matching can use Address, City, State, and ZIP Code fields to yield Plus 4, Delivery Point Check Digit, Geocode Latitude and Geocode Longitude as shown in Figure 1 below.
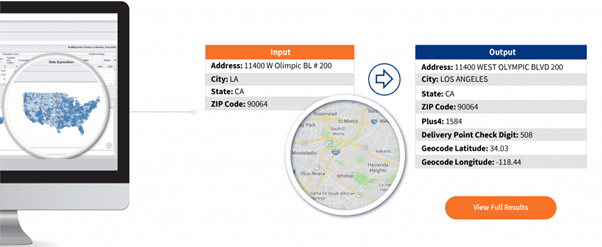
The matching part involves matching addresses stored in a data source with a spatial reference data set (such as ZIP codes, streets, parcels, city, and so on). The addresses are parsed into smaller increments which are then compared across the address details in the reference data set.
Once the address is matched with the spatial reference data, it is interpolated or assigned map coordinates through an estimated value.
For large businesses and enterprises, this can extend to matching addresses across disparate data sources to identify redundant and duplicated addresses to determine a single customer view.
Applications of Address Matching
Address matching is used by businesses across a wide spectrum of sectors from marketing and real estate to police and schools. Here are a few examples:
- Marketing analysis for service area: A delivery service company wants to understand streets with highest orders to minimize delivery radius around specific location clusters.
- Crime analysis by location: A police department may want to check which locations within, and outside cities have the highest crime rates to allocate budget and staff resources accordingly.
- Customer data management: Companies that decide to invest in a holistic view of its customers from details such as purchasing patterns to demographic information including street, address, and location all of which it may use for segmentation.
- Buses for schoolchildren: schools will also find address matching useful in identifying number of buses for all school going children.
Deterministic Address Matching
Address Matching, like any other kind of data matching, is dependent on deterministic and probabilistic matching for high match accuracy as shown in Figure 2.
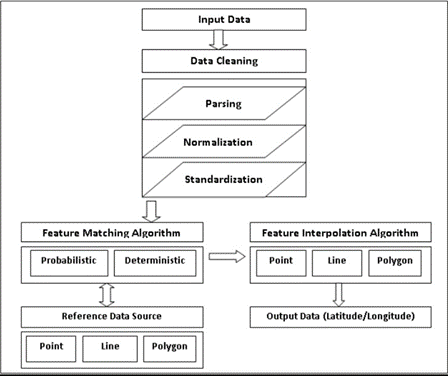
Deterministic or exact matching tends not be very reliable since typos, misspellings, trailing and leading spaces, and other anomalies can prevent two otherwise similar records from matching accurately. Although address locators that define the parameters for interpreting and matching address data to maximize interpolation values is a best practice, the problem of exact matching remains.
The case of varied address formats and addresses without any set order complicates address matching. Relative addresses in comparison with absolute addresses can make finding exact matches far more difficult and time-consuming.
An example of an absolute address can be:
11400 West Olympic Boulevard 200
122 Main Street, New York, NY 10030
A relative address, on the other hand, can be:
Opposite city mall
Across the street
Behind main landmark
In the case of deterministic matching, relative addresses as the one shown above will not be matched exactly against the used reference data consisting of other spatial locations.
How is Fuzzy Address Matching Different?
Fuzzy logic or fuzzy matching is a set of algorithms that allow you to match addresses based on likelihood rather than a yes or no logic.
This means that even addresses with a slight variance in wording that would seem incorrect at first glance have a chance of being matched unlike in the case of deterministic or exact address matching.
Algorithms such as Levensthein Distance, Damerau-Levenshtein distance, and others help establish relevance and find non-exact matches far more accurately.
Benefits of Fuzzy Address Matching
As fuzzy logic algorithms are based on probabilistic matching, there are several benefits it can offer to address matching for businesses. These include:
Better matching accuracy: fuzzy algorithms provide higher match accuracy by linking address information such as apartment numbers and directionals with other address data that would otherwise be missed entirely using exact matching.
Takes formatting errors and misspellings into account: fuzzy algorithms also consider address information with multiple anomalies for matching. For example, for ‘Main Street’, addresses containing typos (e.g. Man Street), reversals (e.g. Niam Street), and leading spaces (e.g. Main Street) can also be picked up and matched for better address standardization.
Useful in the absence of a unique identifier: unlike exact matching that requires a unique identifier (such as SSN or email to be consistent), fuzzy matching is far more practical when dealing with data without any consistent unique identifier data.
Limitations of Fuzzy Address Matching
As beneficial fuzzy matching is it has its fair share of drawbacks and limitations. Some of these are:
Doesn’t detect addresses with phonetic variations: phonetic variations such as Main Street vs. Mane Street can’t be detected by fuzzy algorithms. This can be a problem since many spell address information based on what it sounds rather than its actual spelling.
Can detect incorrect variations in matches: while it is useful to detect matches with slight typo and other variations, it can also include false positives (e.g. Maple Street and Staple Street) that are wrong in its matching.
How DataMatch Enterprise Makes Use of Fuzzy Address Matching
Data Ladder’s DataMatch Enterprise (DME) is a CASS-Certified address matching solution that utilizes a wide range of fuzzy matching algorithms (e.g. Levensthein Distance, Damerau-Levenshtein Distance, Jaro-Wrinkler Distance, Jaccard Index, and more) along with phonetic matching to establish higher match accuracy.
DME parses address data into different smaller increments such as street number, name, city name, and other details which it matches against its USPS database for address verification and standardization.
For more information on DME, check out address matching or contact us for enquiries.

How best in class fuzzy matching solutions work: Combining established and proprietary algorithms
Download

