





























Last Updated on janvier 1, 2026
Si l’idée de faire correspondre les adresses d’une demi-douzaine de sources vous a déjà traversé l’esprit, vous savez que c’est tout sauf une promenade de santé. Vous avez des milliers (voire des millions) d’adresses stockées dans des PDF, des fichiers Excel, des bases de données – dont la plupart ne correspondent à aucun format spécifique. Vous passez de longues heures frustrantes à relier des enregistrements, mais – pour ajouter l’insulte à l’injure – vos efforts de saisie manuelle exacerbent les erreurs de données, vous noyant davantage dans le chaos.
Aussi importantes que soient les listes d’adresses propres pour vos besoins professionnels au sens large, une correspondance d’adresses de qualité utilisant des algorithmes flous peut s’avérer une méthode bien plus efficace. Voyons pourquoi il en est ainsi.
Qu’est-ce que la correspondance d’adresses ?
La correspondance d’adresses (également connue sous le nom de géocodage d’adresses) est le processus qui consiste à déterminer les détails de l’emplacement spatial sous la forme de coordonnées de localisation (par exemple, longitude et latitude, UTM, local, plan de l’État et autres) pour une adresse donnée. Par exemple, la correspondance d’adresses peut utiliser les champs Adresse, Ville, État et Code postal pour obtenir Plus 4, le chiffre de contrôle du point de livraison, la latitude géocode et la longitude géocode, comme le montre la figure 1 ci-dessous.
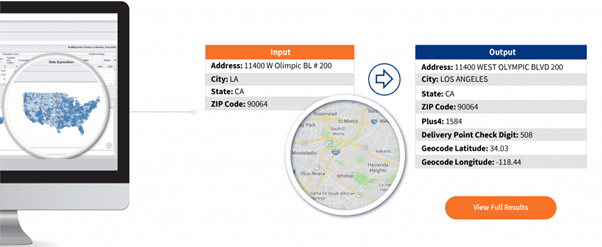
La mise en correspondance consiste à faire correspondre les adresses stockées dans une source de données avec un ensemble de données de référence spatiale (codes postaux, rues, parcelles, ville, etc.). Les adresses sont analysées en incréments plus petits qui sont ensuite comparés aux détails des adresses dans l’ensemble de données de référence.
Une fois l’adresse mise en correspondance avec les données de référence spatiale, elle est interpolée ou se voit attribuer des coordonnées cartographiques par le biais d’une valeur estimée.
Pour les grandes entreprises et les entreprises, cela peut aller jusqu’à la mise en correspondance des adresses à travers des sources de données disparates pour identifier les adresses redondantes et dupliquées afin de déterminer une vue unique du client.
Applications de la correspondance d’adresses
La correspondance d’adresses est utilisée par des entreprises dans un large éventail de secteurs, du marketing à l’immobilier en passant par la police et les écoles. Voici quelques exemples :
- Analyse marketing pour la zone de service : Une entreprise de services de livraison souhaite connaître les rues où les commandes sont les plus nombreuses afin de minimiser le rayon de livraison autour de groupes d’emplacements spécifiques.
- Analyse de la criminalité par lieu : Un service de police peut vouloir vérifier quels sont les endroits à l’intérieur et à l’extérieur des villes qui présentent les taux de criminalité les plus élevés afin d’allouer le budget et les ressources en personnel en conséquence.
- Gestion des données clients : Les entreprises qui décident d’investir dans une vision globale de leurs clients, depuis des détails tels que les habitudes d’achat jusqu’aux informations démographiques, y compris la rue, l’adresse et la localisation, autant d’éléments qu’elles peuvent utiliser pour la segmentation.
- Bus pour les écoliers : les écoles trouveront également la correspondance d’adresses utile pour identifier le nombre de bus pour tous les écoliers.
Correspondance d’adresses déterministe
La correspondance d’adresses, comme tout autre type de correspondance de données, dépend de la correspondance déterministe et probabiliste pour obtenir une grande précision de correspondance, comme le montre la figure 2.
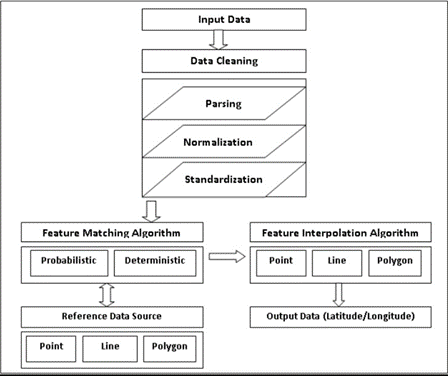
La correspondance déterministe ou exacte n’est généralement pas très fiable, car les fautes de frappe, les fautes d’orthographe, les espaces en fin de ligne et en tête de ligne, ainsi que d’autres anomalies peuvent empêcher la correspondance exacte de deux enregistrements par ailleurs similaires. Bien que les localisateurs d’adresses qui définissent les paramètres d’interprétation et de mise en correspondance des données d’adresses pour maximiser les valeurs d’interpolation constituent une bonne pratique, le problème de la correspondance exacte demeure.
Le cas de formats d’adresses variés et d’adresses sans ordre précis complique le rapprochement des adresses. Les adresses relatives par rapport aux adresses absolues peuvent rendre la recherche de correspondances exactes beaucoup plus difficile et longue.
Un exemple d’adresse absolue peut être :
11400 West Olympic Boulevard 200
122 Main Street, New York, NY 10030
Une adresse relative, par contre, peut l’être :
En face du centre commercial
De l’autre côté de la rue
Derrière le point de repère principal
Dans le cas d’une correspondance déterministe, les adresses relatives telles que celle présentée ci-dessus ne seront pas exactement comparées aux données de référence utilisées, constituées d’autres emplacements spatiaux.
En quoi la correspondance d’adresses floue est-elle différente ?
La logique floue ou la correspondance floue est un ensemble d’algorithmes qui vous permettent de faire correspondre des adresses en fonction de leur probabilité plutôt que d’une logique de oui ou de non.
Cela signifie que même les adresses dont le libellé varie légèrement et qui sembleraient incorrectes à première vue ont une chance d’être appariées, contrairement à ce qui se passe dans le cas de la correspondance déterministe ou exacte des adresses.
Des algorithmes tels que la distance de Levensthein, la distance de Damerau-Levenshtein et d’autres aident à établir la pertinence et à trouver des correspondances non exactes avec beaucoup plus de précision.
Avantages de la correspondance d’adresses floue
Comme les algorithmes de logique floue sont basés sur la correspondance probabiliste, ils peuvent offrir plusieurs avantages à la correspondance d’adresses pour les entreprises. Il s’agit notamment de :
Meilleure précision de la correspondance : les algorithmes flous offrent une meilleure précision de la correspondance en reliant des informations d’adresse telles que les numéros d’appartement et les indicateurs de direction à d’autres données d’adresse qui, autrement, seraient entièrement manquées en utilisant la correspondance exacte.
Prise en compte des erreurs de formatage et des fautes d’orthographe : les algorithmes flous prennent également en compte les informations d’adresse présentant de multiples anomalies pour la mise en correspondance. Par exemple, pour « Main Street », les adresses contenant des fautes de frappe (par exemple, Man Street), des inversions (par exemple, Niam Street) et des espaces avant (par exemple, Main Street) peuvent également être détectées et mises en correspondance pour une meilleure normalisation des adresses.
Utile en l’absence d’un identifiant unique : contrairement à la correspondance exacte qui nécessite un identifiant unique (tel que le SSN ou l’adresse électronique pour être cohérent), la correspondance floue est beaucoup plus pratique lorsqu’il s’agit de données sans identifiant unique cohérent.
Limites de la correspondance d’adresses floue
Aussi bénéfique que soit la correspondance floue, elle a son lot d’inconvénients et de limites. En voici quelques-unes :
Ne détecte pas les adresses avec des variations phonétiques : les variations phonétiques telles que Main Street vs Mane Street ne peuvent pas être détectées par les algorithmes flous. Cela peut poser problème, car de nombreuses personnes épellent les adresses en se basant sur leur consonance plutôt que sur leur orthographe réelle.
Peut détecter des variations incorrectes dans les correspondances : s’il est utile de détecter les correspondances comportant de légères fautes de frappe et d’autres variations, il peut également inclure des faux positifs (par exemple, Maple Street et Staple Street) qui sont erronés dans leur correspondance.
Comment DataMatch Enterprise utilise la correspondance d’adresses floue
DataMatch Enterprise (DME ) de Data Ladder est une solution de rapprochement d’adresses certifiée CASS qui utilise une large gamme d’algorithmes de rapprochement flous (par exemple, la distance de Levensthein, la distance de Damerau-Levenshtein, la distance de Jaro-Wrinkler, l’indice de Jaccard, et plus encore) ainsi que le rapprochement phonétique pour établir une correspondance plus précise.
DME analyse les données d’adresse en différents incréments plus petits tels que le numéro de rue, le nom, le nom de la ville et d’autres détails qu’il compare à sa base de données USPS pour la vérification et la normalisation des adresses.
Pour plus d’informations sur le DME, consultez la correspondance des adresses ou contactez-nous pour toute demande de renseignements.

Comment fonctionnent les meilleures solutions de correspondance floue de leur catégorie : Combinaison d’algorithmes établis et exclusifs
Commencez votre essai gratuit aujourd’hui



