





























Last Updated on April 14, 2022
Doppelte Daten sind ein ernsthaftes Problem, das den Einblick in ein Unternehmen beeinträchtigt, teuren Speicherplatz verschlingt, Kundeninformationen durcheinander bringt und das Unternehmen zu fehlerhaften Entscheidungen verleitet. IT-Manager, Datenanalysten und Geschäftsanwender sind sich der Duplikate bewusst – sie haben jedes Mal damit zu tun, wenn sie Daten für ein Projekt extrahieren, aber eine unternehmensweite Auswirkung ist erst dann zu spüren, wenn doppelte und unsaubere Daten die Ursache für eine ins Stocken geratene oder gescheiterte Geschäftsinitiative sind.
Der Prozess der Entfernung von Duplikaten wird als Datendeduplizierung bezeichnet, und das Ziel besteht darin, zu verhindern, dass sich ein Problem mit doppelten Daten zu einer Krise entwickelt.
In diesem Leitfaden behandle ich Themen wie:
- Die wahre Bedeutung von Datenduplikaten und deren Typen
- Einige häufige Ursachen für doppelte Datensätze
- Herausforderungen bei der Bereinigung/Entfernung von Duplikaten
- Was ist Datendeduplizierung und wie funktioniert sie?
- Gibt es eine einfachere Möglichkeit, Daten zu dedizieren?
- Wie DataMatch Enterprise hilft
Fangen wir gleich damit an.
Doppelte Daten, ihre Arten und Gründe für ihr Auftreten
Die einfache Definition: Eine Kopie eines Originaldatensatzes ist ein Duplikat. Wenn das der Fall wäre, wäre die Auflösung von Duplikaten nie ein Problem gewesen.
Doppelte Daten sind viel komplexer, als wir uns vorstellen können. Im Folgenden finden Sie einige Arten und relevante Beispiele, die Ihnen helfen, das Ausmaß von Problemen mit doppelten Daten zu verstehen.
Typ 1: Exakte Duplikate in derselben Quelle
Dies ist auf Fehler bei der Dateneingabe zurückzuführen, z. B. durch Kopieren/Einfügen von Informationen aus einer Quelle in eine andere. Wenn Sie beispielsweise Informationen aus einem Marketing-Tool eines Drittanbieters in das CRM-System kopieren, kann es sein, dass Sie dieselben Informationen doppelt erfassen. Exakte Duplikate sind leicht zu erkennen.
Beispiel:
CRM-Datensatz Zeile 1 und Zeile 5 enthalten Duplikate, wobei der letzte Datensatz einen zusätzlichen Buchstaben im Vornamen enthält.
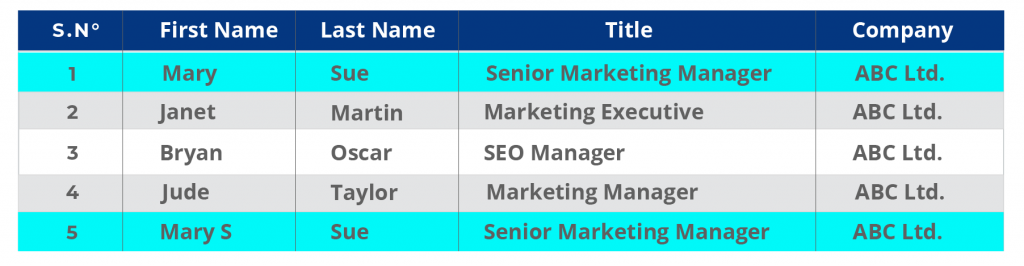
Beachten Sie, dass die letzte Zeile ebenfalls einen versehentlichen Tippfehler enthält. Der Vorname lautet Mary S., statt Mary.
Typ 2: Exakte Duplikate in mehreren Quellen
Die Datensicherung ist häufig die Hauptursache für exakte Duplikate in mehreren Quellen. Unternehmen sind oft nicht gewillt, Daten zu löschen, weshalb sie dazu neigen, Listen in verschiedenen Formaten und Quellen zu speichern. Die lokalen Ordner des Unternehmens können beispielsweise eine veraltete Excel-Tabelle mit Datensätzen enthalten, die erstellt wurden, als das Unternehmen versuchte, eine Datenquelle vom ERP zu einem CRM zu migrieren. Im Laufe der Zeit verursachen die Kopien dieser Daten erhebliche Probleme mit dem Plattenspeicher und der Systemleistung. Einer der wichtigsten Beweggründe für IT-Anwender, Daten zu dedizieren, ist die Freigabe von Speicherplatz!
Beispiel:
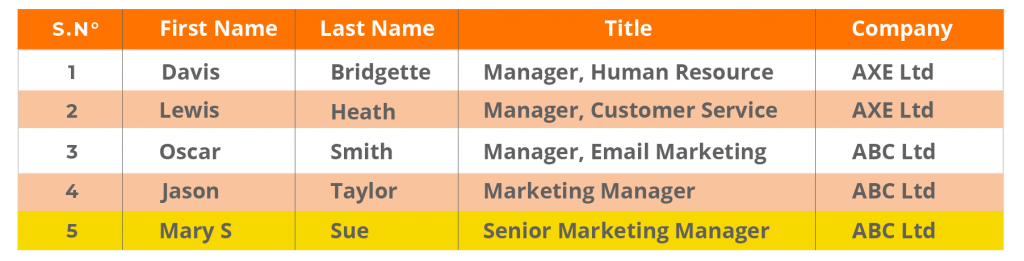
Exakte Duplikate in CRM und Unternehmensdatenbank. Beachten Sie, dass sich die Struktur der Datenbank von derjenigen des CRM unterscheidet. Wenn Daten vom CRM in die Datenbank verschoben werden, können diese Probleme auftreten, was zu ungenauen und doppelten Daten führt, die schwer zu erkennen sind.
CRM-Daten:
Unternehmensdatenbank:
Typ 3: Duplikate mit variierenden Informationen in mehreren Quellen
In diesem Fall werden unterschiedliche Informationen desselben Benutzers in mehreren Quellen gespeichert. Dies geschieht, wenn die Entität aufgrund einer neuen E-Mail-ID, einer neuen Adresse oder einer neuen Berufsbezeichnung als neuer Eintrag erfasst wird.
Beispiel:
Nehmen wir das obige Beispiel mit aktualisierten Informationen.
CRM-Daten:
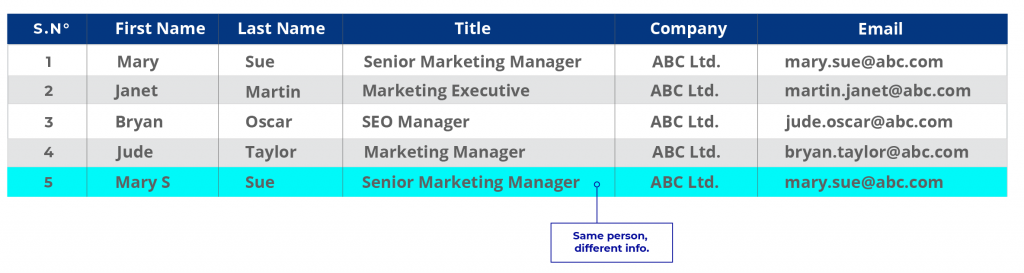

Im ersten Fall könnte es sich bei Maria um eine alte Kundin handeln, deren Daten in der Datenbank des Unternehmens gespeichert, aber nie aktualisiert wurden. Im CRM sind die Informationen neu. Angenommen, das Unternehmen möchte seine Datenbank aktualisieren, dann ist der Datensatz von Frau Mary Sue ein Duplikat. Wenn Unternehmen über mehrere unterschiedliche Datenquellen verfügen und jede dieser Quellen Informationen auf unterschiedliche Weise speichert, kommt es häufig zu Duplikaten dieser Art.
Typ 4: Nicht exakte Duplikate
Dies ist das häufigste Problem und auch das am schwierigsten zu lösende. Dies ist der Fall, wenn die Informationen eines Unternehmens auf mehrere Arten geschrieben werden.
Angenommen, der vollständige Name von Mary Sue lautet Mary Susan Sue, so werden ihre Daten in mehreren Datensätzen eingegeben.
CRM: Mary J. Sue
Marketingunterlagen: Mary Jane
Versehentliches Eintippen einer Abkürzung durch einen Handelsvertreter in einem Abteilungsdatensatz: MJ Sue.
Nehmen wir einmal an, Mary Jane Sue ist Ärztin. In einigen Datensätzen wird ihr Titel Frau, in anderen Frau Dr. lauten. Wenn die Dateneingabevorschriften der Organisation nur Frau/Frau/Herr zulassen, kann ihr Titel Frau Dr. nicht hinzugefügt werden!
Was wäre, wenn sie innerhalb von zwei Jahren zweimal ihre Telefonnummer, E-Mail-Adresse oder ihren Arbeitsplatz gewechselt hat? Und jedes Mal, wenn sie mit dem Unternehmen Geschäfte macht, wird sie als neuer Kunde registriert.
Ursachen für Duplikate
Duplikate wie Typ 3 und 4 sind mit exakten Datenabgleichstechniken, die darauf angewiesen sind, dass die Felder exakte Werte haben, nicht leicht zu erkennen. Selbst wenn Sie eine Strategie zur Datendeduplizierung haben, werden Duplikate auftreten.
Hier sind einige Gründe dafür:
Überschneidungen aufgrund von Fusionen und Übernahmen
Wenn Unternehmen Daten aus mehreren Quellen zusammenführen, um eine umfangreiche Migration durchzuführen, wird das Ausmaß der Duplizierung gefährlich kompliziert. Die Datenstruktur der beiden Unternehmen kann sich unterscheiden, auch wenn sie dieselben Kundeninformationen haben.
Ein Microsoft-Nutzer ist zum Beispiel auch ein LinkedIn-Nutzer, und beide Plattformen können fast die gleichen individuellen Daten haben. Daher können Duplikate auf einer tieferen Ebene auftreten, wenn die Unternehmen ihre Daten ohne eine solide Datenqualitätsstrategie zusammenführen, die Datenaufbereitung, Datenbereinigung, Datenkonsolidierung und Datendeduplizierung umfasst.
Schlechte Dateneingabeprozesse und fehlende Data Governance
Unternehmen, die keine strengen Data-Governance-Richtlinien einführen oder keine strategischen Datenqualitätssysteme einsetzen, haben oft schmutzige, doppelte Daten.
Es ist nicht ungewöhnlich, dass mehrere Mitglieder eines Teams auf das CRM zugreifen und Daten nach Belieben eingeben/bearbeiten/anpassen. Das bedeutet, dass es keine Rechenschaftspflicht oder Rückverfolgbarkeit gibt, keinen Hinweis darauf, wer für die korrekte Dateneingabe verantwortlich ist, und keine Richtlinien für die korrekte Dateneingabe.
All dies führt zu Problemen wie doppelten oder mehrfachen Einträgen für einen einzigen Datensatz, die keine Genauigkeit garantieren. Wenn die Daten für Einblicke oder Berichte verwendet werden sollen, muss sich die verantwortliche Person den Kopf zerbrechen, um aus all den Daten einen Sinn zu machen. Schlechte Praktiken bei der Dateneingabe haben schwerwiegende Auswirkungen auf nachgelagerte Anwendungen, die sich auf die Ineffizienz auswirken und auch die Hauptursache für Konflikte zwischen Abteilungen sind.
Daten von Drittanbietern und Integrationen mit Partnerportalen
Daten von Drittanbietern, z. B. von Partnerportalen, Netzwerken oder Communities, oder auch von Website-Registrierungsformularen führen zu einer erheblichen Anzahl von Duplikaten. Oftmals können Personen, die ein Formular ausfüllen, mehrere E-Mail-IDs oder Telefonnummern verwenden, was zu mehreren Einträgen einer Person führt. Andererseits können externe Daten eine andere Version derselben Entität enthalten, aber dieselben Informationen werden in den bestehenden Datensätzen nicht aktualisiert und stattdessen wird ein neuer Datensatz erstellt. Während dies zu diesem Zeitpunkt kein Problem zu sein scheint, führt es später zu verzerrten Analysen.
So kann ein Unternehmen beispielsweise glauben, mit einer Kampagne 100 Leads gewonnen zu haben. Da die Einträge jedoch dupliziert wurden, handelt es sich möglicherweise nur um 60 gültige Leads, während die restlichen 40 entweder unvollständig, dupliziert oder ungenau sind.
Angenommen, jede Spur ist $100 x 40 = $4K wert.
Angenommen, die Kosten für jedes Blei betragen 50 $ x 40 = 2K
Verlust: $6k insgesamt!
Software-Bugs und Systemfehler
Software-Bugs und Verwaltungs- oder Systemfehler im CRM und in den damit verbundenen Anwendungen können zu Tausenden von doppelten Datensätzen führen. Dies kommt häufig bei System- oder Datenmigrationen vor und kann zwar behoben werden, stellt aber eine ernsthafte Herausforderung für die Datenqualität dar.
Jede Datenquelle enthält einen gewissen Anteil an doppelten Daten. Experten halten bis zu 5 % Doppelungen für tolerierbar. Alles, was darüber hinausgeht, stellt eine Gefahr für nachgelagerte Anwendungen dar. Berichte werden irreführend. Die Kunden sind verärgert. Nutzer und Mitarbeiter werden frustriert. Dem CIO zufolge können „Systeme mit 25 % doppelten Datensätzen Karrieren gefährden “ .
Laut Natik Ameen, Marketingexperte bei Canz Marketing, sind doppelte Daten im CRM des Unternehmens auf eine Reihe von Gründen zurückzuführen.von menschlichem Versagen bis hin zu Kunden, die zu unterschiedlichen Zeitpunkten leicht abweichende Informationen in die Unternehmensdatenbank eingeben. Ein Verbraucher gibt beispielsweise auf einem Formular seinen Namen als Jonathan Smith und auf dem anderen als Jon Smith an. Die Herausforderung wird durch eine wachsende Datenbank noch verschärft. Für Administratoren wird es immer schwieriger, den Überblick über die DB zu behalten und die relevanten Daten zu erfassen. Es wird immer schwieriger, sicherzustellen, dass die DB der Organisation korrekt bleibt.‚.
Sie benötigen eine Strategie zur Datendeduplizierung, um das Problem der doppelten Daten zu lösen.
Was ist Daten-Deduplizierung und wie funktioniert sie?
Bei der Datendeduplizierung werden Duplikate verglichen, abgeglichen und entfernt, um einen konsolidierten Datensatz zu erstellen. Die Deduplizierung von Daten erfolgt in drei Schritten:
Vergleich und Abgleich: Verschiedene Listen und Datensätze werden verglichen und abgeglichen, um exakte und nicht exakte Duplikate zu erkennen. So wird beispielsweise eine CRM-Liste mit einer internen Datenbankliste abgeglichen, um sicherzustellen, dass die gleichen Datensätze nicht zweimal in die zentrale Datenbank hochgeladen werden.
Behandlung veralteter Datensätze: Veraltete doppelte Datensätze werden entweder mit neuen Informationen aktualisiert oder entfernt. In anderen Fällen werden Daten konsolidiert (wenn ein Datensatz Handles für soziale Medien enthält, der andere aber nicht) und neue Regeln oder Spalten erstellt, um diese zusätzlichen Informationen zu speichern.
Erstellen konsolidierter Datensätze: Nach dem Entfernen von Duplikaten wird ein konsolidierter Datensatz mit sauberen, aufbereiteten Daten erstellt, der als „goldener Datensatz“ verwendet werden kann, auf dessen Grundlage bestehende Datensätze nachgebildet werden können.
Tools wie Excel eignen sich hervorragend zum Entfernen von exakten Duplikaten innerhalb derselben Datenquelle, versagen jedoch bei der Identifizierung ähnlicher Duplikate.
Wie Sie exakte Duplikate in Excel entfernen können, erfahren Sie in dieser Anleitung:
https://www.excel-easy.com/examples/remove-duplicates.html
Um Duplikate in Python zu entfernen, können Sie die Dedupe Library verwenden, um Datensätze in Datensätzen zu finden, die zur gleichen Entität gehören. Hier finden Sie einen hervorragenden Leitfaden zum Deduplizieren von Daten mit Python:
https://recordlinkage.readthedocs.io/en/latest/notebooks/data_deduplication.html
Gibt es eine einfachere Möglichkeit, Daten zu deduplizieren?
Python ist zwar leistungsstark, aber zeitaufwändig.
Um beispielsweise einen einfachen Datensatz zwischen zwei Quellen abzugleichen, müssen Sie Module laden oder importieren, Datensatzpaare bilden (was an sich schon ein zeitaufwändiger Prozess ist) und dann einen Code zum Vergleich von Datensätzen auf Attributsebene erstellen. Sie müssen dann jede Instanz des Vergleichs manuell überprüfen, um festzustellen, welcher Datensatz zu derselben Person gehört.
Dieser Prozess muss für jede neue Anforderung auf Attributsebene geändert und wiederholt werden.
Wenn Sie als Datenanalyst für die Daten eines Unternehmens verantwortlich sind, können Sie sich nicht monatelang Zeit nehmen, um Daten abzuziehen.
Sie können auch nicht riskieren, Daten zu verlieren, was eine reale Möglichkeit ist, wenn Sie versuchen, verschiedene Codes zu testen, um die richtige Übereinstimmung zu finden.
Eric McGee, Senior Network Engineer bei TRG DataCenters, sieht das größte Problem beim Bereinigen/Löschen von Daten darin, dass bei der Verschlankung von Datenfeldern Daten verloren gehen können. Er ist außerdem der Meinung, dass auf Unternehmensebene die Genauigkeit des Datenabgleichs sehr wichtig werden kann, da sonst die gesamte Praxis wichtige Daten gefährden könnte.
Ein einfacherer Weg, auf den sich jedoch nicht viele Systemingenieure einlassen wollen, ist die Verwendung eines Tools zur Datendeduplizierung, insbesondere wenn es nicht Teil ihrer Datenverwaltungsplattform ist. Das Problem ist, dass die meisten Datenverwaltungsplattformen nicht über robuste Datenabgleichsfunktionen verfügen, die den Benutzern bei der Ermittlung von Duplikaten helfen können. Analysten und Ingenieure müssen die Daten schließlich manuell deduplizieren, was eine erhebliche Zeitverschwendung darstellt.
Die besten Tools zur Datendeduplizierung nutzen fortschrittliche Fuzzy-Matching-Algorithmen und proprietäre Algorithmen, um Daten auf einer tieferen Ebene abzugleichen – eine Fähigkeit, die nicht alle Datenmanagementlösungen bieten. Aus diesem Grund bevorzugen die meisten Unternehmen und Fortune-500-Kunden, mit denen wir zusammengearbeitet haben, die Verwendung eines Tools wie
DataMatch Enterprise
in Verbindung mit ihren Datenmanagement-Plattformen.
Aufgrund seiner einfachen Integrationsfähigkeit und seiner leistungsstarken Fuzzy-Matching-Algorithmen ist DataMatch Enterprise für die meisten Unternehmen ein bevorzugtes Werkzeug zur Deduktion von Daten innerhalb ihrer Datenbankplattform.
Wenn Sie mehr über die Unternehmen erfahren möchten, denen wir bei der Datendeduplizierung geholfen haben, besuchen Sie unsere Fallstudien.
Sehen Sie zum Beispiel, wie wir mit der Bell Bank zusammengearbeitet haben, um Duplikate zu entfernen und Kundendaten aus verschiedenen Quellen zu konsolidieren.
Oder wie Cleveland Brothers, ein globales Einzelhandelsunternehmen, durch die Verwaltung mehrerer Kundenlisten mit DataMatch Enterprise Zeit sparte.
|
|
|


Schlussfolgerung – Entwicklung eines methodischen Ansatzes zur Datendeduplizierung
In dem Maße, in dem sich die Art der Daten weiterentwickelt, wird auch die Komplexität von Qualitätsfragen zunehmen. Duplikate sind mit manuellen Methoden nur schwer zu bewältigen. Die Nachfrage nach Echtzeit-Einblicken wird es unpraktisch machen, wochenlang an einem perfekten Code zu arbeiten. Daher ist es für Unternehmen unerlässlich, ihr Arsenal an Datenqualitätstools und Verwaltungsplattformen ständig zu aktualisieren, um die Genauigkeit und Integrität der Daten sicherzustellen.



