




























Last Updated on marzo 9, 2022
Los datos duplicados son un grave problema que afecta a la información de una organización, consume un costoso espacio de almacenamiento, desordena la información de los clientes y lleva a la empresa a tomar decisiones erróneas. Los responsables de TI, los analistas de datos y los usuarios de la empresa son conscientes de la existencia de duplicidades: se enfrentan a ellas cada vez que extraen datos para un proyecto, pero el impacto en toda la empresa sólo se percibe cuando los datos duplicados y sucios se convierten en la causa de un estancamiento o del fracaso de una iniciativa empresarial.
El proceso de eliminación de duplicados se llama deduplicación de datos y el objetivo es evitar que un problema de datos duplicados se convierta en una crisis.
En esta guía, cubriré temas sobre:
- El verdadero significado de los datos duplicados y sus tipos
- Algunas causas comunes de los registros duplicados
- Desafíos a los que se enfrentan los usuarios al limpiar/eliminar duplicados
- ¿Qué es la deduplicación de datos y cómo funciona?
- ¿Existe una manera más fácil de desduplicar los datos?
- Cómo ayuda DataMatch Enterprise
Entremos de lleno.
Datos duplicados, sus tipos y por qué se producen
La definición fácil: una copia de un registro original es un duplicado. Si así fuera, la resolución de duplicados nunca habría sido un problema.
Los datos duplicados son mucho más complejos de lo que podemos imaginar. A continuación se presentan algunos tipos y ejemplos relevantes para ayudarle a comprender el alcance de los problemas de duplicación de datos.
Tipo 1: Duplicados exactos en la misma fuente
Esto se debe a errores de introducción de datos, como copiar/pegar información de una fuente a otra. Por ejemplo, si está copiando información de una herramienta de marketing de terceros en el CRM, podría registrar la misma información dos veces. Los duplicados exactos son fáciles de detectar.
Ejemplo:
Las filas 1 y 5 del registro CRM tienen duplicados en los que el último registro tiene una letra adicional en el nombre.
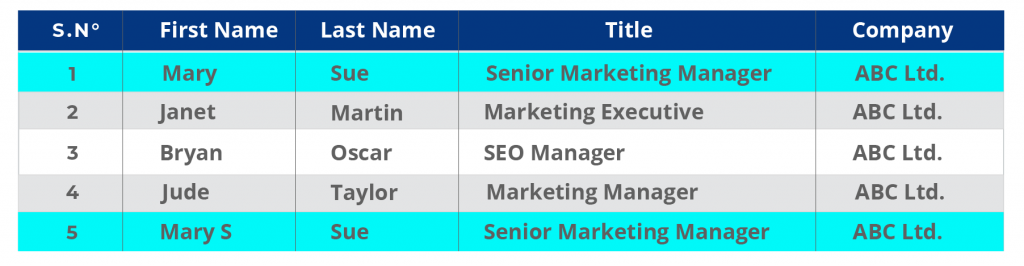
Fíjese en que la última fila también tiene una errata accidental. El nombre es Mary S, en lugar de Mary.
Tipo 2: Duplicados exactos en múltiples fuentes
La copia de seguridad de los datos suele ser la principal causa de duplicados exactos en múltiples fuentes. Las empresas suelen resistirse a eliminar los datos, por lo que tienden a guardar las listas en múltiples formatos y fuentes. Por ejemplo, las carpetas locales de la empresa pueden contener una hoja de Excel obsoleta de registros que se crearon cuando la empresa intentó migrar una fuente de datos del ERP a un CRM. Con el tiempo, las copias de estos datos causan importantes problemas de almacenamiento en disco y de rendimiento del sistema. Una de las motivaciones más importantes para que los usuarios de TI deduzcan los datos es liberar espacio de almacenamiento.
Ejemplo:
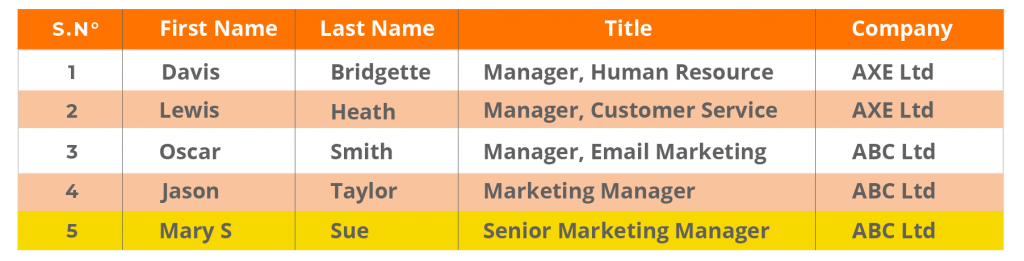
Duplicados exactos en el CRM y en la base de datos de la empresa. Observe cómo la estructura de la base de datos es diferente a la del CRM. Cuando los datos se trasladan del CRM a la base de datos, pueden encontrarse con estos problemas, lo que da lugar a datos inexactos y duplicados que son difíciles de detectar.
Datos de CRM:
Base de datos de la empresa:
Tipo 3: Duplicados con información variable en varias fuentes
En este caso, la información variable del mismo usuario se almacena en múltiples fuentes. Esto ocurre cuando la entidad se registra como una nueva entrada debido a un nuevo ID de correo electrónico, una nueva dirección o un nuevo cargo.
Ejemplo:
Utilicemos el ejemplo anterior con información actualizada.
Datos de CRM:
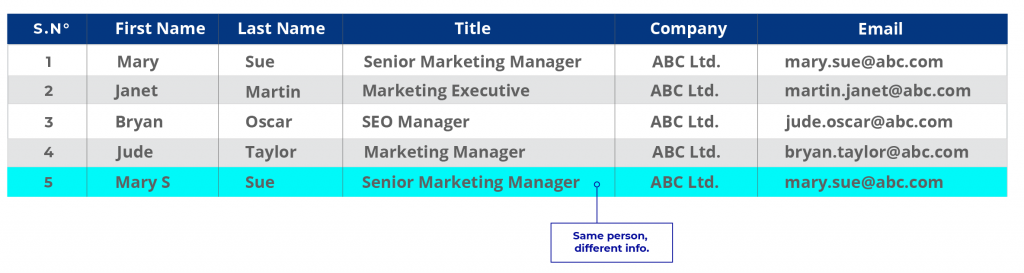

En el primer caso, María puede haber sido una antigua clienta cuyos registros se almacenaron en la base de datos de la empresa pero nunca se actualizaron. En el CRM, la información es nueva. Suponiendo que la empresa quiera actualizar su base de datos, el registro de la Sra. Mary Sue es un duplicado. Cuando las empresas tienen múltiples fuentes de datos dispares y cada una de ellas almacena la información de forma diferente, son frecuentes las duplicidades de este tipo.
Tipo 4: Duplicados no exactos
Este es el problema más común y también el más difícil de detectar. Esto ocurre cuando la información de una entidad se escribe de múltiples maneras.
Suponiendo que el nombre completo de Mary Sue es Mary Susan Sue, así es como se introducirán sus datos en los registros múltiples.
CRM: Mary J. Sue
Registros de marketing: Mary Jane
Escritura accidental de un atajo por parte de un representante de ventas en un registro departamental: MJ Sue.
Ahora, asumamos que Mary Jane Sue es una doctora. Algunos registros tendrán su título como Sra. mientras que otros Dr. Si las reglas de entrada de datos de la organización sólo permiten Sra. / Sr. / Sr., su título como Dr. no puede ser añadido.
Para hacerlo más difícil, ¿qué pasa si ha cambiado de número, de dirección de correo electrónico o de lugar de trabajo dos veces en dos años? Y cada vez que hace negocios con la empresa, queda registrada como un nuevo cliente.
Causas de los duplicados
Los duplicados de los tipos 3 y 4 no son fáciles de detectar mediante técnicas de comparación de datos exactos que dependen de que los campos tengan valores exactos para detectar una coincidencia. Incluso si tiene una estrategia de deduplicación de datos, se producirán duplicados.
He aquí algunas razones:
Duplicación causada por las fusiones y adquisiciones
Cuando las empresas fusionan datos de múltiples fuentes para realizar una migración masiva, el nivel de duplicación se complica peligrosamente. La estructura de datos de ambas empresas puede ser diferente aunque compartan la misma información sobre los clientes.
Por ejemplo, un usuario de Microsoft es también un usuario de LinkedIn y ambas plataformas pueden tener casi los mismos datos individuales. Por lo tanto, los duplicados pueden producirse a un nivel más profundo si las empresas fusionan sus datos sin una sólida estrategia de calidad de datos que implique la preparación, la limpieza, la consolidación y la deduplicación de los mismos.
Procesos de entrada de datos deficientes y falta de gobernanza de los datos
Las organizaciones que no aplican políticas estrictas de gobernanza de datos o no cuentan con sistemas estratégicos de calidad de datos suelen acabar con datos sucios y duplicados.
No es raro que varios miembros de un equipo accedan al CRM y rellenen/editen/personalicen los datos a voluntad. Esto significa que no hay responsabilidad ni trazabilidad, ni indicación de quién es el responsable de la introducción de datos exactos, ni directrices sobre cómo introducir los datos correctamente.
Todo esto lleva a problemas como la duplicación o las múltiples entradas de un mismo registro que no garantizan la exactitud. Cuando los datos se vayan a utilizar para obtener información o informes, el responsable tendrá que devanarse los sesos tratando de dar sentido a todos los datos. Las malas prácticas en la fase de introducción de datos tienen serias implicaciones en las aplicaciones posteriores que afectan a la ineficacia y también son la principal causa de conflictos departamentales.
Datos de terceros e integraciones con portales de socios
Los datos de terceros, como los obtenidos de portales, redes o comunidades de socios, o incluso de formularios de registro de sitios web, provocan niveles de duplicación significativamente altos. A menudo, las personas que rellenan un formulario pueden utilizar varios identificadores de correo electrónico o números de teléfono, lo que da lugar a múltiples entradas de una persona. Por otro lado, los datos externos pueden tener una versión diferente de la misma entidad, pero la misma información no se actualiza en los registros existentes y en su lugar se crea un nuevo registro. Si bien esto no parece ser un problema en el momento, más tarde resulta en un análisis sesgado.
Por ejemplo, una empresa puede creer que ha conseguido 100 clientes potenciales con una campaña, pero debido a que las entradas se han duplicado, puede que sólo sean 60 clientes potenciales válidos, y los 40 restantes estén incompletos, duplicados o sean inexactos.
Suponiendo que cada pista vale 100 dólares x 40 = 4.000 dólares
Suponiendo que el coste de cada pista es de 50 dólares x 40 = 2.000
Pérdida: ¡6 mil dólares en total!
Errores de software y del sistema
Los fallos de software y los errores administrativos o del sistema en el CRM y en las aplicaciones asociadas pueden dar lugar a miles de registros duplicados. Esto es algo habitual durante las actividades de migración de sistemas o datos y, aunque se puede rectificar, supone un grave problema de calidad de los datos.
Todas las fuentes de datos contienen cierta cantidad de datos duplicados. Los expertos creen que hasta un 5% de duplicación es tolerable. Todo lo que esté por encima de eso supone una amenaza para las aplicaciones posteriores. Los informes se vuelven engañosos. Los clientes se molestan. Los usuarios y los empleados se frustran. Según el CIO, «los sistemas con un 25% de registros duplicados pueden amenazar las carreras».
Según Natik Ameen, experto en marketing de Canz Marketing, la duplicación de datos en el CRM de la empresa se debe a una serie de razones, ‘desde un error humano hasta que los clientes proporcionen información ligeramente diferente en distintos momentos de la base de datos de la organización. Por ejemplo, un consumidor pone su nombre como Jonathan Smith en un formulario y Jon Smith en el otro. El reto se ve agravado por una base de datos cada vez mayor. A menudo es cada vez más difícil para los administradores hacer un seguimiento de la base de datos y también de los datos relevantes. Cada vez es más difícil garantizar que la base de datos de la organización sea precisa‘.
Se necesita una estrategia de deduplicación de datos para hacer frente a los desafíos de los datos duplicados.
¿Qué es la deduplicación de datos y cómo funciona?
La deduplicación de datos es el proceso de comparar, cotejar y eliminar duplicados para crear un registro consolidado. La deduplicación de datos consta de tres pasos:
Comparación y cotejo: Se comparan y cotejan diferentes listas y registros para detectar duplicados exactos y no exactos. Por ejemplo, una lista de CRM se coteja con una lista de la base de datos interna para garantizar que los mismos registros no se carguen dos veces en la base de datos central.
Tratamiento de los registros obsoletos: Los registros duplicados obsoletos se actualizan con nueva información o se eliminan. En otros casos, los datos se consolidan (si un registro tiene mangos de redes sociales y el otro no) y se crean nuevas reglas o columnas para almacenar esta información adicional.
Creación de registros consolidados: Una vez eliminados los duplicados, se crea un registro consolidado formado por datos limpios y tratados que puede utilizarse como «registro de oro», a partir del cual se pueden modelar los registros existentes.
Las herramientas como Excel pueden ser excelentes para eliminar los duplicados exactos dentro de la misma fuente de datos, sin embargo, fallan a la hora de identificar duplicados similares.
Para ver cómo puede eliminar los duplicados exactos en Excel, siga esta guía:
https://www.excel-easy.com/examples/remove-duplicates.html
Para eliminar duplicados en Python, puede utilizar la biblioteca Dedupe para encontrar registros en conjuntos de datos que pertenezcan a la misma entidad. Aquí hay una excelente guía sobre la deduplicación de datos usando Python:
https://recordlinkage.readthedocs.io/en/latest/notebooks/data_deduplication.html
¿Existe una forma más fácil de deduplicar los datos?
Python, aunque es potente, consume mucho tiempo.
Por ejemplo, para hacer coincidir un simple registro entre dos fuentes, hay que cargar o importar módulos, hacer pares de registros (lo cual es un proceso que lleva mucho tiempo en sí mismo), y luego crear un código para comparar registros a nivel de atributos. Entonces tendrá que revisar manualmente cada instancia de la comparación para identificar qué registro pertenece a la misma persona.
Este proceso debe modificarse y repetirse para cada nuevo requisito a nivel de atributos.
Si usted es un analista de datos responsable de los datos de una empresa, no puede tardar meses en desduplicar los datos.
Tampoco puedes arriesgarte a perder datos, lo que es una posibilidad real cuando intentas probar diferentes códigos para conseguir la coincidencia correcta.
Eric McGee, Ingeniero de Redes Senior, en TRG DataCenters, cree que el mayor problema al limpiar/eliminar datos es la posibilidad de perder datos al racionalizar los campos de datos. También cree que, a nivel empresarial, la exactitud del cotejo de datos puede llegar a ser muy importante, o toda la práctica puede comprometer datos cruciales.
Una forma más sencilla, pero a la que no muchos ingenieros de sistemas están dispuestos a adaptarse, es el uso de una herramienta de deduplicación de datos, especialmente si no forma parte de su plataforma de gestión de datos. El problema es que la mayoría de las plataformas de gestión de datos no cuentan con sólidas capacidades de cotejo de datos que puedan ayudar a los usuarios a identificar los duplicados. Los analistas e ingenieros acaban desduplicando manualmente los datos, lo que supone una importante pérdida de tiempo.
Las mejores herramientas de deduplicación de datos utilizan algoritmos avanzados de coincidencia difusa y algoritmos propios para hacer coincidir los datos a un nivel más profundo, una capacidad que no ofrecen todas las soluciones de gestión de datos. Por este motivo, la mayoría de los clientes de nivel empresarial y de la lista Fortune 500 con los que hemos trabajado prefieren utilizar una herramienta como
DataMatch para empresas
junto con sus plataformas de gestión de datos.
Gracias a su facilidad de integración y a sus potentes algoritmos de coincidencia difusa, DataMatch Enterprise ha sido la herramienta preferida por la mayoría de las organizaciones para desduplicar datos dentro de su plataforma de bases de datos.
Si quiere saber más sobre las empresas a las que hemos ayudado con la deduplicación de datos, visite nuestros casos prácticos.
Por ejemplo, vea cómo trabajamos con el Bell Bank para eliminar los duplicados y consolidar los datos de los clientes procedentes de múltiples fuentes.
O cómo Cleveland Brothers, un minorista global, ahorró tiempo al gestionar múltiples listas de clientes con DataMatch Enterprise.
|
|
|


Conclusión – Desarrollar un enfoque metódico para la deduplicación de datos
A medida que la naturaleza de los datos evoluciona, también aumenta la complejidad de los problemas de calidad. Los duplicados serán difíciles de abordar con métodos manuales. La demanda de información en tiempo real hará que no sea práctico pasar semanas ideando el código perfecto. Por ello, es imprescindible que las empresas actualicen continuamente su arsenal de herramientas de calidad de datos y plataformas de gestión para garantizar la precisión e integridad de los datos.



