































Last Updated on June 4, 2026
Duplicate data is a serious problem that affects an organization’s insights, eats up expensive storage space, messes up customer information & leads the business into making flawed decisions. IT managers, data analysts, and business users are aware of duplicates – they deal with it every time they extract data for a project but a company-wide impact is only felt when duplicate and dirty data becomes the cause of a stalled or failed business initiative.
The process of removing duplicates is called data deduplication and the goal is to prevent a duplicate data problem from turning into a crisis.
In this guide, I’ll cover topics on:
- The true meaning of duplicate data & its types
- Some common causes for duplicate records
- Challenges users face when cleaning/removing duplicates
- What is data deduplication and how does it work
- Is there an easier way to dedupe data?
- How DataMatch Enterprise helps
Let’s jump right in.
Duplicate Data, its Types & Why They Occur
The easy definition – a copy of an original record is a duplicate. If that were the case, resolving duplicates would never have been a problem.
Duplicate data is much more complex than we can imagine. Here are some types and relevant examples to help you understand the extent of duplicate data problems.
Type 1: Exact Duplicates in the Same Source
This is caused by data entry errors including copy/pasting information from one source into the other. For instance, if you’re copying information from a third-party tool marketing tool into the CRM, you might record the same information twice. Exact duplicates are easy to detect.
Example:
CRM Record Row 1 and Row 5 have duplicates where the last record has an additional letter in the first name.
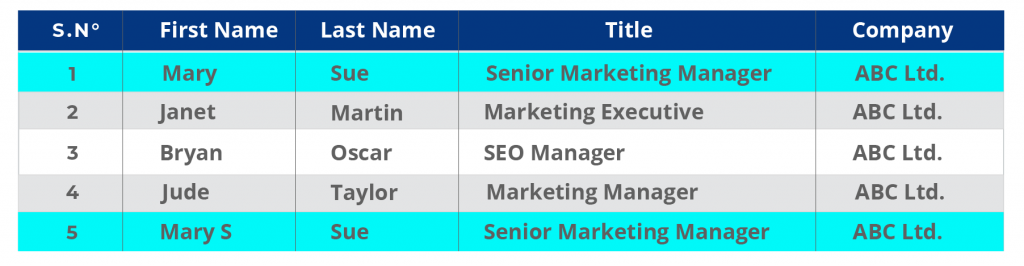
Notice the last row also has an accidental typo. The first name is Mary S, instead of Mary.
Type 2: Exact Duplicates in Multiple Sources
Data backup is often the leading cause of exact duplicates in multiple sources. Companies are often resistant to removing data, so they tend to keep saving lists in multiple formats and sources. For instance, the company’s local folders may contain an outdated Excel sheet of records that were created when the company tried migrating a data source from the ERP to a CRM. Over time, copies of these data cause significant problems with disk storage and system performance. One of the most important motivations for IT users to dedupe data is to free up storage space!
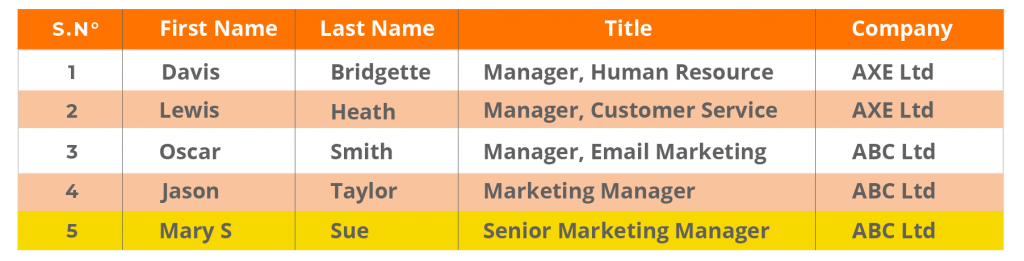
Example:
Exact Duplicates in CRM and Company Database. Notice how the structure of the database is different from that of the CRM. When data is moved from the CRM to the database, it can encounter these problems, resulting in inaccurate and duplicated data that is hard to detect.
CRM Data:
Company Database:
Type 3: Duplicates with Varying Information in Multiple Sources
In this instance, varying information of the same user is stored in multiple sources. This occurs when the entity is recorded as a new entry because of a new email ID, a new address or a new job title.
Example:
Let’s use the example above with updated information.
CRM Data:
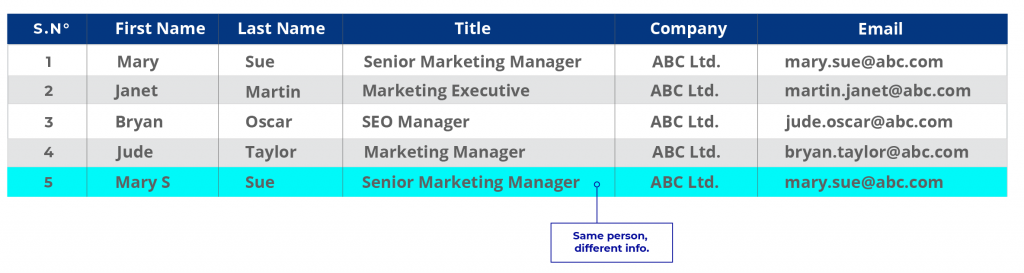

In the first instance, Mary may have been an old customer whose records were stored in the company database but never updated. In the CRM, the information is new. Assuming the company wants to update its database, Ms. Mary Sue’s record is a duplicate. When companies have multiple disparate data sources and each of them stores information differently, duplicates of this nature are frequent.
Type 4: Non-Exact Duplicates
This is the most common problem and also the most difficult to catch. This happens when one entity’s information is written in multiple ways.
Supposing Mary Sue’s complete name is Mary Susan Sue, this is how her data will be entered in multiple records.
CRM: Mary J. Sue
Marketing records: Mary Jane
Accidental shortcut typing by sales rep in a departmental record: MJ Sue.
Now, let’s assume Mary Jane Sue is a doctor. Some records will have her title as Ms. While others Dr. If the organization’s data entry rules only allow for Ms/Mrs/Mr, her title as Dr. cannot be added!
To make it challenging, what if she has changed numbers, email addresses, or her workplace twice in two years? And each time she does business with the company, she is recorded as a new customer.
Causes of Duplicates
Duplicates like Type 3 and 4 are not easy to detect through exact data matching techniques that rely on fields to have exact values to detect a match. Even if you have a data deduplication strategy in place, duplicates will occur.
Here are a few reasons why:
Duplication Caused by Mergers & Acquisitions
When companies merge data from multiple sources to perform a massive migration, the level of duplication becomes dangerously complicated. Both the companies’ data structure may differ even though they may share the same customer information.
For instance, a Microsoft user is also a LinkedIn user and both platforms may have almost the same individual data. Therefore, duplicates can occur at a deeper level if the companies merge their data without a strong data quality strategy in place that will involve data preparation, data cleaning, data consolidation, and data deduplication.
Poor Data Entry Processes & Lack of Data Governance
Organizations that don’t implement stringent data governance policies or do not have strategic data quality systems in place often end up with dirty, duplicated data.
It’s not uncommon for multiple members of a team to access the CRM and fill/edit/customize data at will. This means there is no accountability or traceability, no indication of who is responsible for accurate data entry, no guidelines on how to enter data correctly.
All of this leads to problems like duplicated or multiple entries for a single record that do not guarantee accuracy. When the data is to be used for insights or reports, the person responsible will have to rack their brains trying to make sense of all the data. Poor data practices at the data entry phase have serious implications in downstream applications that affect inefficiency and also are the leading cause of departmental conflicts.
Third-Party Data and Integrations with Partner Portals
Third-party data such as data obtained from partner portals, networks, or communities, or even from website registration forms cause significantly high levels of duplicates. Often people filling a form can use multiple email IDs or phone numbers leading to multiple entries of one individual. On the other hand, external data may have a different version of the same entity but the same information is not updated in existing records and a new record is created instead. While this doesn’t seem to be a problem at the time, it later results in skewed analytics.
For instance, a company may believe it has secured 100 leads with a campaign, but because the entries have been duplicated, it may just be only 60 valid leads, with the remaining 40 either incomplete, duplicated, or inaccurate.
Assuming each lead is worth a $100 x 40 = $4K
Assuming the cost of each lead is $50 x 40 = 2K
Loss: $6k in total!
Software Bugs and System Errors
Software bugs and administrative or system errors in the CRM and in associated applications can result in thousands of duplicate records. This is a common occurrence during system or data migration activities and while this can be rectified it causes a serious data quality challenge.
Every data source will contain some amount of duplicate data. Experts believe that up to 5% of duplication is tolerable. Anything above that poses a threat to downstream applications. Reports become misleading. Customers become annoyed. Users and employees become frustrated. According to the CIO, ‘systems with 25% duplicate records can threaten careers.’
According to Natik Ameen, Marketing Expert at Canz Marketing, duplicate data in the company’s CRM happens due to a range of reasons, ‘from a human error to customers providing slightly different information at different points in time in the organizational database. For example, a consumer lists his name as Jonathan Smith on one form and Jon Smith on the other. The challenge is exacerbated by a growing database. It is often increasingly tough for administrators to keep track of DB and as well as track the relevant data. It gets more and more challenging to ensure that organization’s DB remains accurate’.
You need a data deduplication strategy to handle duplicate data challenges.
What is Data Deduplication and How Does it Work?
Data deduplication is the process of comparing, matching, and removing duplicates to create a consolidated record. There are three steps in deduplicating data:
Comparing and matching: Different lists and records are compared and matched to detect exact and non-exact duplicates. For instance, a CRM list is matched with an internal database list to ensure that the same records are not uploaded twice into the central database.
Handling obsolete records: Obsolete duplicate records are either updated with new information or removed. In other instances, data is consolidated (if one record has social media handles while the other doesn’t) and new rules or columns are created to store this additional information.
Creating consolidated records: Once duplicates have been removed, a consolidated record consisting of clean, treated data is created which can be used as a ‘golden record,’ based on which existing records can be modeled after.
Tools like Excel can be great for removing exact duplicates within the same data source, however, it fails at identifying similar duplicates.
To see how you can remove exact duplicates in Excel, follow this guide:
To remove duplicates in Python, you can use the Dedupe Library to find records in datasets belonging to the same entity. Here’s an excellent guide on deduping data using Python:
Is There an Easier Way to Dedupe Data?
Python though powerful is time-consuming.
For instance, to match a simple record between two sources, you have to load or import modules, make record pairs (which is a time-consuming process in itself), then create a code to compare records on an attribute level. You will then have to manually review every instance of the comparison to identify which record belongs to the same person.
This process has to be modified and repeated for every new requirement at an attribute level.
If you’re a data analyst responsible for the data of an enterprise, you cannot take months to dedupe data.
You can’t also risk losing data, which is a real possibility when you’re trying to test different codes to make the right match.
Eric McGee, Senior Network Engineer, at TRG DataCenters, believes the biggest problem while cleaning/removing data is the possibility of losing data when streamlining data fields. He also believes at the enterprise-level, the accuracy of data matching can become very important, or the entire practice can compromise crucial data.
An easier way, but one not many system engineers are prepared to adapt to is the use of a data deduplication tool, especially if it is not part of their data management platform. The problem is, most data management platforms do not have robust data matching abilities that can help users to identify duplicates. Analysts and engineers eventually do end up manually deduping data, which is a significant waste of time.
Best data deduplication tools make use of advanced fuzzy matching algorithms and proprietary algorithms to match data at a deeper level – an ability, not all data management solutions offer. This is why most enterprise-level and Fortune 500 clients we’ve worked with prefer to use a tool like DataMatch Enterprise in conjunction with their data management platforms.
Because of its easy integration abilities and powerful fuzzy matching algorithms, DataMatch Enterprise has been a preferred tool for most organizations to dedupe data within their database platform.
If you’d like to know more about the companies, we’ve helped with data deduplication, visit our case studies.
For instance, see how we worked with Bell Bank to remove duplicates and consolidate customer data from multiple sources.
Or how Cleveland Brothers, a global retailer saved time by managing multiple customer lists with DataMatch Enterprise.


Conclusion – Develop a Methodical Approach to Data Deduplication
As the nature of data evolves, so will the increase in the complexities of quality issues. Duplicates will become hard to tackle with manual methods. Demand for real-time insights will make it impractical to spend weeks coming up with the perfect code. Hence, it’s imperative for companies to continually update their arsenal of data quality tools and management platforms to ensure data accuracy and integrity.

