





























Last Updated on mars 28, 2022
La duplication des données est un problème sérieux qui affecte les connaissances d’une organisation, consomme de l’espace de stockage coûteux, brouille les informations sur les clients et conduit l’entreprise à prendre des décisions erronées. Les responsables informatiques, les analystes de données et les utilisateurs professionnels sont conscients des doublons – ils y sont confrontés chaque fois qu’ils extraient des données pour un projet, mais l’impact sur l’ensemble de l’entreprise ne se fait sentir que lorsque les données dupliquées et sales deviennent la cause du blocage ou de l’échec d’une initiative commerciale.
Le processus de suppression des doublons est appelé déduplication des données et l’objectif est d’éviter qu’un problème de doublons de données ne se transforme en crise.
Dans ce guide, je traiterai des sujets suivants :
- La véritable signification des données dupliquées et leurs types
- Quelques causes courantes de doublons
- Difficultés rencontrées par les utilisateurs pour nettoyer/supprimer les doublons
- Qu’est-ce que la déduplication des données et comment fonctionne-t-elle ?
- Existe-t-il un moyen plus simple de déduire des données ?
- Comment DataMatch Enterprise aide-t-il
Allons-y.
Les données dupliquées, leurs types et pourquoi elles se produisent
La définition simple – une copie d’un document original est un duplicata. Si tel était le cas, la résolution des doublons n’aurait jamais été un problème.
La duplication des données est beaucoup plus complexe que ce que l’on peut imaginer. Voici quelques types et exemples pertinents pour vous aider à comprendre l’étendue des problèmes de données dupliquées.
Type 1 : Duplicatas exacts dans la même source
Cela est dû à des erreurs de saisie de données, notamment le copier/coller d’informations d’une source à l’autre. Par exemple, si vous copiez des informations d’un outil de marketing tiers dans le CRM, vous risquez d’enregistrer deux fois la même information. Les doublons exacts sont faciles à détecter.
Exemple :
Les enregistrements CRM de la rangée 1 et de la rangée 5 ont des doublons où le dernier enregistrement a une lettre supplémentaire dans le prénom.
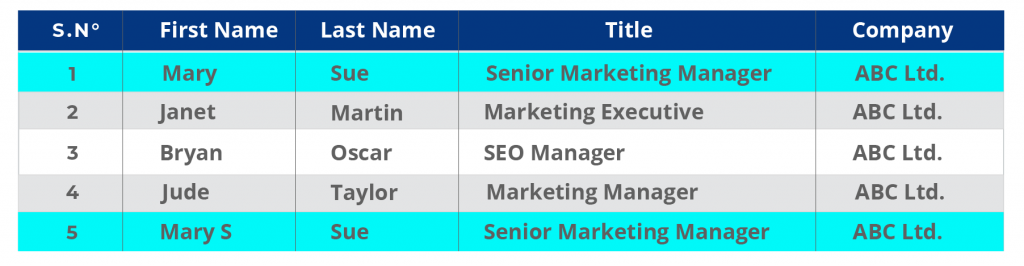
Remarquez que la dernière ligne comporte également une faute de frappe accidentelle. Le prénom est Mary S, au lieu de Mary.
Type 2 : Duplicatas exacts dans des sources multiples
La sauvegarde des données est souvent la principale cause de doublons exacts dans des sources multiples. Les entreprises sont souvent réticentes à l’idée de supprimer des données. Elles ont donc tendance à conserver des listes dans de multiples formats et sources. Par exemple, les dossiers locaux de l’entreprise peuvent contenir une feuille Excel périmée d’enregistrements créés lorsque l’entreprise a essayé de migrer une source de données de l’ERP vers un CRM. Au fil du temps, les copies de ces données causent d’importants problèmes de stockage sur le disque et de performances du système. L’une des principales motivations des utilisateurs informatiques pour déduire des données est de libérer de l’espace de stockage !
Exemple :
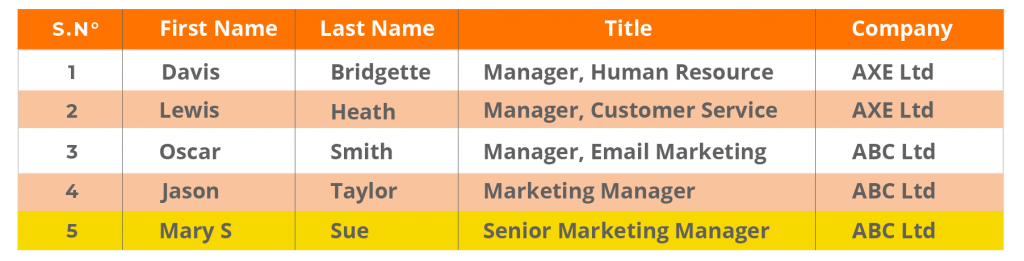
Duplicatas exacts dans la base de données de la CRM et des entreprises. Remarquez que la structure de la base de données est différente de celle du CRM. Lorsque les données sont déplacées du CRM vers la base de données, elles peuvent rencontrer ces problèmes, ce qui entraîne des données inexactes et dupliquées difficiles à détecter.
Données CRM :
Base de données de l’entreprise :
Type 3 : doublons avec des informations variables dans plusieurs sources
Dans ce cas, les différentes informations d’un même utilisateur sont stockées dans plusieurs sources. Cela se produit lorsque l’entité est enregistrée comme une nouvelle entrée en raison d’une nouvelle adresse électronique, d’une nouvelle adresse ou d’un nouvel intitulé de poste.
Exemple :
Reprenons l’exemple ci-dessus avec des informations actualisées.
Données CRM :
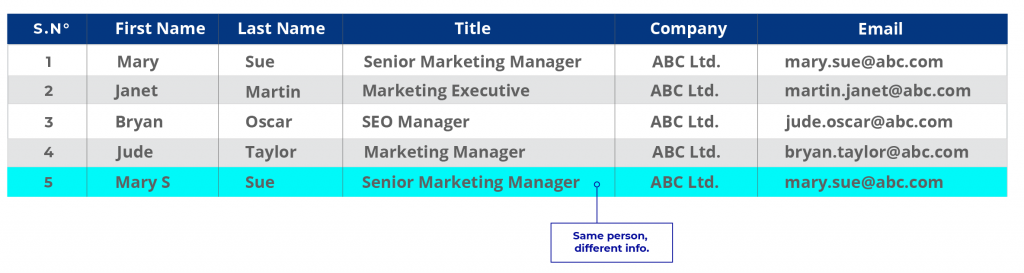

Dans le premier cas, Marie peut être un ancien client dont les données ont été stockées dans la base de données de l’entreprise mais n’ont jamais été mises à jour. Dans le CRM, l’information est nouvelle. En supposant que l’entreprise veuille mettre à jour sa base de données, l’enregistrement de Mme Mary Sue est un doublon. Lorsque les entreprises disposent de plusieurs sources de données disparates et que chacune d’entre elles stocke les informations différemment, les doublons de cette nature sont fréquents.
Type 4 : Duplicatas non exacts
C’est le problème le plus courant et aussi le plus difficile à attraper. Cela se produit lorsque les informations d’une entité sont écrites de plusieurs façons.
Supposons que le nom complet de Mary Sue soit Mary Susan Sue, voici comment ses données seront saisies dans des enregistrements multiples.
CRM : Mary J. Sue
Dossiers de commercialisation : Mary Jane
Saisie accidentelle d’un raccourci par un commercial dans une fiche départementale : MJ Sue.
Maintenant, supposons que Mary Jane Sue est un médecin. Si les règles de saisie des données de l’organisation n’autorisent que Ms/Mrs/Mr, son titre de Dr. ne peut pas être ajouté !
Pour corser le tout, que faire si elle a changé de numéro, d’adresse électronique ou de lieu de travail deux fois en deux ans ? Et chaque fois qu’elle fait affaire avec l’entreprise, elle est enregistrée comme un nouveau client.
Causes des doublons
Les doublons comme ceux de type 3 et 4 ne sont pas faciles à détecter par les techniques de comparaison de données exactes qui reposent sur des champs ayant des valeurs exactes pour détecter une correspondance. Même si vous avez mis en place une stratégie de déduplication des données, il y aura toujours des doublons.
Voici quelques raisons pour lesquelles :
Duplication causée par les fusions et acquisitions
Lorsque les entreprises fusionnent des données provenant de sources multiples pour effectuer une migration massive, le niveau de duplication devient dangereusement compliqué. La structure des données des deux entreprises peut différer, même si elles partagent les mêmes informations sur les clients.
Par exemple, un utilisateur de Microsoft est aussi un utilisateur de LinkedIn et les deux plateformes peuvent avoir presque les mêmes données individuelles. Par conséquent, les doublons peuvent se produire à un niveau plus profond si les entreprises fusionnent leurs données sans mettre en place une solide stratégie de qualité des données qui implique la préparation des données, leur nettoyage, leur consolidation et leur déduplication.
Mauvais processus de saisie des données et manque de gouvernance des données
Les organisations qui ne mettent pas en œuvre des politiques strictes de gouvernance des données ou qui ne disposent pas de systèmes stratégiques de qualité des données se retrouvent souvent avec des données sales et dupliquées.
Il n’est pas rare que plusieurs membres d’une équipe puissent accéder au CRM et remplir/modifier/personnaliser les données à volonté. Cela signifie qu’il n’y a pas d’obligation de rendre des comptes ou de traçabilité, pas d’indication de la personne responsable de la saisie exacte des données, pas de directives sur la manière de saisir correctement les données.
Tout cela entraîne des problèmes tels que des entrées doubles ou multiples pour un seul enregistrement qui ne garantissent pas l’exactitude. Lorsque les données doivent être utilisées pour des analyses ou des rapports, la personne responsable devra se creuser les méninges pour essayer de donner un sens à toutes ces données. Les mauvaises pratiques en matière de données lors de la phase d’entrée des données ont de graves répercussions sur les applications en aval qui affectent l’inefficacité et sont également la principale cause des conflits entre départements.
Données de tiers et intégrations avec les portails de partenaires
Les données provenant de tiers, telles que les données obtenues à partir de portails, de réseaux ou de communautés de partenaires, ou même à partir de formulaires d’inscription à des sites web, sont à l’origine d’un nombre élevé de doublons. Souvent, les personnes qui remplissent un formulaire peuvent utiliser plusieurs identifiants de messagerie ou numéros de téléphone, ce qui entraîne des entrées multiples pour une seule personne. D’autre part, les données externes peuvent avoir une version différente de la même entité, mais les mêmes informations ne sont pas mises à jour dans les enregistrements existants et un nouvel enregistrement est créé à la place. Bien que cela ne semble pas être un problème sur le moment, cela entraîne par la suite des analyses faussées.
Par exemple, une entreprise peut croire qu’elle a obtenu 100 pistes grâce à une campagne, mais comme les entrées ont été dupliquées, il ne s’agit peut-être que de 60 pistes valides, les 40 autres étant incomplètes, dupliquées ou inexactes.
En supposant que chaque piste vaut 100 $ x 40 = 4 000 $.
En supposant que le coût de chaque piste est de 50 $ x 40 = 2 000 $.
Perte : 6 000 $ au total !
Bugs logiciels et erreurs système
Les bogues logiciels et les erreurs administratives ou de système dans le CRM et dans les applications associées peuvent entraîner des milliers d’enregistrements en double. Cette situation est fréquente lors des activités de migration de systèmes ou de données et, bien qu’elle puisse être rectifiée, elle pose un sérieux problème de qualité des données.
Chaque source de données contient une certaine quantité de données en double. Les experts estiment que jusqu’à 5% de duplication est tolérable. Tout ce qui dépasse ce seuil constitue une menace pour les applications en aval. Les rapports deviennent trompeurs. Les clients s’énervent. Les utilisateurs et les employés deviennent frustrés. Selon le DSI, « les systèmes comportant 25 % d’enregistrements en double peuvent menacer des carrières » .
Selon Natik Ameen, expert en marketing chez Canz Marketing, les données en double dans le CRM de l’entreprise sont dues à toute une série de raisons.d’une erreur humaine à des clients fournissant des informations légèrement différentes à différents moments dans la base de données de l’organisation. Par exemple, un consommateur inscrit son nom en tant que Jonathan Smith sur un formulaire et Jon Smith sur l’autre. Le défi est exacerbé par une base de données en pleine expansion. Il est souvent de plus en plus difficile pour les administrateurs d’assurer le suivi de la DB ainsi que celui des données pertinentes. Il est de plus en plus difficile de s’assurer que la BD de l’organisation reste exacte.‘.
Vous avez besoin d’une stratégie de déduplication des données pour relever le défi des données dupliquées.
Qu’est-ce que la déduplication des données et comment fonctionne-t-elle ?
La déduplication des données est le processus de comparaison, de rapprochement et de suppression des doublons pour créer un enregistrement consolidé. La déduplication des données se fait en trois étapes :
Comparaison et mise en correspondance : différentes listes et différents enregistrements sont comparés et mis en correspondance pour détecter les doublons exacts et non exacts. Par exemple, une liste CRM est mise en correspondance avec une liste de base de données interne afin de s’assurer que les mêmes enregistrements ne sont pas téléchargés deux fois dans la base de données centrale.
Traitement des enregistrements obsolètes : Les enregistrements en double obsolètes sont soit mis à jour avec de nouvelles informations, soit supprimés. Dans d’autres cas, les données sont consolidées (si un enregistrement a des poignées de médias sociaux alors que l’autre n’en a pas) et de nouvelles règles ou colonnes sont créées pour stocker ces informations supplémentaires.
Création d’enregistrements consolidés : Une fois que les doublons ont été supprimés, un enregistrement consolidé composé de données propres et traitées est créé et peut être utilisé comme « enregistrement d’or », sur la base duquel les enregistrements existants peuvent être modelés.
Des outils tels qu’Excel peuvent être excellents pour supprimer les doublons exacts au sein d’une même source de données, mais ils ne parviennent pas à identifier les doublons similaires.
Pour voir comment supprimer les doublons exacts dans Excel, suivez ce guide :
https://www.excel-easy.com/examples/remove-duplicates.html
Pour supprimer les doublons en Python, vous pouvez utiliser la bibliothèque Dedupe pour trouver des enregistrements dans des ensembles de données appartenant à la même entité. Voici un excellent guide sur la déduplication des données à l’aide de Python :
https://recordlinkage.readthedocs.io/en/latest/notebooks/data_deduplication.html
Existe-t-il un moyen plus simple de dédupliquer des données ?
Python, bien que puissant, prend beaucoup de temps.
Par exemple, pour faire correspondre un simple enregistrement entre deux sources, vous devez charger ou importer des modules, créer des paires d’enregistrements (ce qui est un processus long en soi), puis créer un code pour comparer les enregistrements au niveau des attributs. Vous devrez alors examiner manuellement chaque instance de la comparaison pour identifier quel enregistrement appartient à la même personne.
Ce processus doit être modifié et répété pour chaque nouvelle exigence au niveau des attributs.
Si vous êtes un analyste de données responsable des données d’une entreprise, vous ne pouvez pas prendre des mois pour déduire des données.
Vous ne pouvez pas non plus risquer de perdre des données, ce qui est une possibilité réelle lorsque vous essayez de tester différents codes pour trouver la bonne correspondance.
Eric McGee, ingénieur réseau senior chez TRG DataCenters, pense que le plus gros problème lors du nettoyage/suppression des données est la possibilité de perdre des données lors de la rationalisation des champs de données. Il pense également qu’au niveau de l’entreprise, l’exactitude de la correspondance des données peut devenir très importante, ou l’ensemble du cabinet peut compromettre des données cruciales.
Une solution plus simple, mais à laquelle peu d’ingénieurs système sont prêts à s’adapter, consiste à utiliser un outil de déduplication des données, surtout s’il ne fait pas partie de leur plateforme de gestion des données. Le problème est que la plupart des plateformes de gestion des données ne disposent pas de solides capacités de rapprochement des données qui peuvent aider les utilisateurs à identifier les doublons. Les analystes et les ingénieurs finissent par déduire manuellement les données, ce qui représente une perte de temps considérable.
Les meilleurs outils de déduplication des données utilisent des algorithmes avancés de correspondance floue et des algorithmes propriétaires pour faire correspondre les données à un niveau plus profond – une capacité que toutes les solutions de gestion des données n’offrent pas. C’est pourquoi la plupart des entreprises et des clients du Fortune 500 avec lesquels nous avons travaillé préfèrent utiliser un outil tel que
DataMatch Enterprise
en conjonction avec leurs plateformes de gestion de données.
En raison de ses capacités d’intégration faciles et de ses puissants algorithmes de correspondance floue, DataMatch Enterprise a été l’outil préféré de la plupart des organisations pour déduire les données au sein de leur plate-forme de base de données.
Si vous souhaitez en savoir plus sur les entreprises que nous avons aidées en matière de déduplication des données, consultez nos études de cas.
Par exemple, voyez comment nous avons travaillé avec Bell Bank pour supprimer les doublons et consolider les données clients provenant de sources multiples.
Ou comment Cleveland Brothers, un détaillant mondial, a gagné du temps en gérant plusieurs listes de clients avec DataMatch Enterprise.
|
|
|


Conclusion – Développer une approche méthodique de la déduplication des données
L’évolution de la nature des données s’accompagne d’une augmentation de la complexité des problèmes de qualité. Les doublons deviendront difficiles à traiter avec des méthodes manuelles. La demande d’informations en temps réel fera qu’il ne sera plus possible de passer des semaines à élaborer le code parfait. Il est donc impératif pour les entreprises de mettre continuellement à jour leur arsenal d’outils de qualité des données et de plateformes de gestion pour garantir l’exactitude et l’intégrité des données.



