





























Last Updated on April 13, 2022
Unsaubere, unstrukturierte strukturierte Daten, mehr als ein Dutzend Namensvarianten und inkonsistente Felddefinitionen in verschiedenen Quellen. Dieser Wurmfortsatz ist für jeden Datenanalysten, der an einem Projekt mit Tausenden von Datensätzen arbeitet, ein fast schon ständiges Berufsrisiko. Und die Auswirkungen sind alles andere als gewöhnlich:
- Globale Finanzinstitute wurden im Jahr 2020 wegen Nichteinhaltung von Compliance-Vorschriften mit Strafen in Höhe von 5,6 Milliarden Dollar belegt
- Eine Umfrage von Black Book Market Research hat ergeben, dass ein Drittel der Leistungsanträge in Gesundheitseinrichtungen wegen unzureichender Patientenzuordnung abgelehnt werden.
- Vertriebsmitarbeiter verlieren 25 % ihrer Zeit aufgrund von schlechten Interessentendaten.
Hier ist also die Schlüsselfrage: Gibt es einen besseren Weg, diese Probleme zu überwinden?
Im Gegensatz zu Entity-Resolution-Tools, die Daten von mehreren Punkten aus erfassen und nicht exakte Übereinstimmungen in beispielloser Geschwindigkeit finden können, erweist sich die manuelle Entity-Resolution von Daten mithilfe komplexer Algorithmen und Techniken als ein weitaus kostspieligeres (um nicht zu sagen anstrengendes) Unterfangen. Untersuchungen von Gartner haben ergeben, dass eine schlechte Datenqualität Unternehmen jedes Jahr 15 Millionen Dollar kostet – insbesondere bei Unternehmen, deren Geschäftstätigkeit sich über mehrere Gebiete und Geschäftseinheiten erstreckt.
In diesem detaillierten Leitfaden erfahren Sie, wie die Entitätsauflösung funktioniert, warum die manuelle Entitätsauflösung für Unternehmen problematisch ist und warum die Entscheidung für Entitätsauflösungstools optimal ist.
Was ist Entity Resolution?
Das Buch Entity Resolution and Information Quality beschreibt die Entitätsauflösung (ER) als „die Bestimmung, wann Verweise auf reale Entitäten äquivalent sind (sich auf dieselbe Entität beziehen) oder nicht äquivalent (sich auf verschiedene Entitäten beziehen)“.
Mit anderen Worten, es handelt sich um den Prozess der Identifizierung und Verknüpfung mehrerer Datensätze mit derselben Entität, wenn die Datensätze unterschiedlich beschrieben sind und umgekehrt.
Sie stellt zum Beispiel die Frage: Sind die Dateneinträge „Jon Snow“ und „John Snowden“ dieselbe Person oder handelt es sich um zwei völlig unterschiedliche Personen?
Dies gilt auch für Adressen, Post- und Postleitzahlen, Sozialversicherungsnummern usw.
ER wird durchgeführt, indem die Ähnlichkeit mehrerer Datensätze anhand eindeutiger Bezeichner überprüft wird. Dies sind Datensätze, die sich im Laufe der Zeit am wenigsten ändern (z. B. Sozialversicherungsnummern, Geburtsdatum, Postleitzahlen usw.). Um herauszufinden, ob diese Datensätze identisch sind oder nicht, müssen sie mit einem eindeutigen Bezeichner abgeglichen werden:
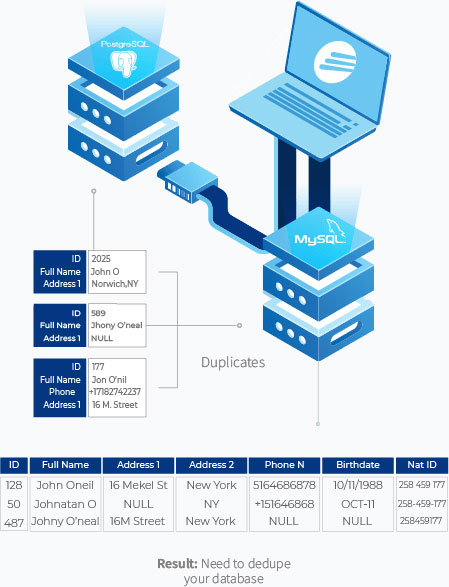
Im obigen Beispiel werden John Oneil, Johnathan O und Johny O’neal durch einen eindeutigen Identifikator, nämlich die nationale ID-Nummer, miteinander verglichen.
ER besteht in der Regel aus der Verknüpfung und dem Abgleich von Daten über mehrere Datensätze hinweg, um mögliche Duplikate zu finden und die übereinstimmenden Duplikate zu entfernen, weshalb es austauschbar mit verwendet wird:
- Verknüpfung von Datensätzen
- Fuzzy-Matching
- Zusammenführen/Säubern
- Clustering von Entitäten
- Deduplizierung und mehr
Wie die Entitätsauflösung in der Praxis funktioniert
Bei einer ER-Aktivität sind mehrere Schritte erforderlich. Schauen wir uns diese im Detail an.
Verschlucken
Dabei werden alle Daten aus verschiedenen Quellen in einer zentralen Ansicht zusammengefasst. Ein Unternehmen hat oft Daten, die über verschiedene Datenbanken, CRMs, Excel und PDFs verstreut sind und Datenformate wie String, Datum und beides enthalten.
Ein großes Hypotheken- und Finanzdienstleistungsunternehmen kann beispielsweise über eine zentrale Datenbank in MySQL, über Antragsformulardaten im PDF-Format und über die Liste seiner Hausbesitzer in Excel verfügen. Durch den Import von Daten aus all diesen Quellen wird die Grundlage für die Verknüpfung von Datensätzen und das Auffinden von Duplikaten geschaffen. Für weitere Informationen klicken Sie bitte hier.
In anderen Fällen kann die Kombination verschiedener Quellen zu einer einzigen auch bedeuten, dass das Schema der Datenbanken für die weitere Verarbeitung in ein einziges vordefiniertes Schema geändert wird.
Profilierung
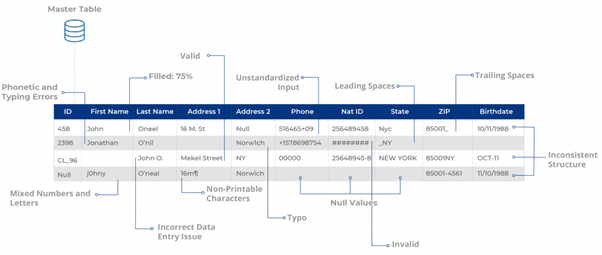
Nachdem die Datenquellen importiert wurden, wird in einem nächsten Schritt ihr Zustand überprüft, um statistische Anomalien in Form von fehlenden und ungenauen Daten sowie Probleme mit der Groß- und Kleinschreibung zu erkennen. Im Idealfall versucht ein Datenanalyst, potenzielle Problembereiche zu finden, die behoben werden müssen, bevor er irgendeine Art von Bereinigung und Entitätsauflösung vornimmt.
Hier kann ein Benutzer prüfen, ob die Felder mit RegEx übereinstimmen – reguläre Ausdrücke, die Zeichenkettentypen für verschiedene Datenfelder bestimmen. Auf dieser Grundlage kann der Benutzer feststellen, wie viele Datensätze entweder unsauber sind oder nicht einer bestimmten Kodierung entsprechen.
Dies kann dazu beitragen, wichtige Datenstatistiken zu ermitteln, einschließlich, aber nicht beschränkt auf:
- Vorhandensein von Nullwerten, z. B. fehlende E-Mail-Adressen in Lead-Gen-Formularen
- Anzahl der Datensätze mit vorangestellten und nachgestellten Leerzeichen z. B. David Matthews
- Probleme mit der Zeichensetzung, z. B. hotmail,com statt Hotmail.com
- Gehäuseprobleme, z. B. NEW YORK, DAVID MATTHEWS, MICROSOFT
- Vorhandensein von Buchstaben in Zahlen und umgekehrt, z. B. TEL-516 570-9251 für die Kontaktnummer und NJ43 für den Staat
Deduplizierung und Datensatzverknüpfung
Durch den Abgleich werden mehrere Datensätze, die sich potenziell auf dieselbe Entität beziehen, zusammengeführt, um Duplikate zu entfernen, oder anhand eindeutiger Kennungen dedupliziert. Die Abgleichtechniken können je nach Art des Feldes variieren, z. B. exakt, unscharf oder phonetisch.
Bei Namen zum Beispiel wird häufig eine exakte Übereinstimmung verwendet, wenn eindeutige Identifikatoren wie die Sozialversicherungsnummer oder die Adresse im gesamten Datensatz korrekt sind. Wenn die eindeutigen Bezeichner ungenau oder ungültig sind, erweist sich der unscharfe Abgleich als eine viel zuverlässigere Form des Abgleichs, um zwei ähnliche Datensätze (z. B. John Snow und Jon Snowden) problemlos miteinander zu verbinden.
Deduplizierung und Datensatzverknüpfung werden in den meisten Fällen als ein und dieselbe Sache verstanden. Ein wesentlicher Unterschied besteht jedoch darin, dass es bei ersterem darum geht, Duplikate zu erkennen und innerhalb desselben Datensatzes zu konsolidieren (d. h. das Schema zu normalisieren), während es bei letzterem darum geht, die deduplizierten Daten mit anderen Datensätzen oder Datenquellen abzugleichen.
Kanonisierung
Die Kanonisierung ist ein weiterer wichtiger Schritt in ER, bei dem Entitäten, die mehrere Darstellungen haben, in eine Standardform umgewandelt werden. Dabei werden die vollständigsten Informationen als endgültiger Datensatz verwendet und Ausreißer oder verrauschte Daten, die die Daten verzerren könnten, ausgelassen.
Blockieren
Bei der Suche nach Übereinstimmungen für eine Entität in Hunderten und Tausenden von Datensätzen können die potenziellen Kombinationen, die zu den richtigen Übereinstimmungen führen könnten, in die Tausende (wenn nicht Millionen) gehen. Um dieses Problem zu vermeiden, wird das Blockieren verwendet, um die möglichen Paarungen durch spezifische Geschäftsregeln einzuschränken.
Herausforderungen bei der Auflösung von Entitäten
Trotz der vielen Ansätze und Techniken, die für die Notaufnahme zur Verfügung stehen, ist sie in vielerlei Hinsicht unzureichend. Dazu gehören:
1. ER funktioniert nur gut, wenn die Daten reichhaltig und konsistent sind
Das vielleicht größte Problem von ER ist, dass die Genauigkeit der Übereinstimmungen von der Reichhaltigkeit und Konsistenz der Daten in den verschiedenen Datensätzen abhängt.
Der deterministische Abgleich ist zum Beispiel recht einfach. Angenommen, Sie haben „Mike Rogers“ in Datenbank 1 und „Mike Rogers“ in Datenbank 2. Durch einfache Datensatzverknüpfung (oder exakte Übereinstimmung) können wir leicht feststellen, dass ein Datensatz ein Duplikat eines anderen ist.
Ein probabilistischer Abgleich, bei dem ähnliche Datensätze in Form von Schreibfehlern, Abkürzungen oder Spitznamen existieren (z. B. „Mike Rogers“ in Datenbank 1 und „Michael Rogers“ in Datenbank 2), sieht jedoch anders aus. Ein eindeutiger Identifikator (z. B. Adresse, Sozialversicherungsnummer oder Geburtsdatum) ist möglicherweise nicht in allen Datenbanken konsistent, und jede Art von exaktem oder deterministischem Abgleich wird nahezu unmöglich, insbesondere wenn es sich um große Datenmengen handelt.
2. ER-Algorithmen sind nicht gut skalierbar
Big-Data-Unternehmensprojekte, die sich mit Terabytes von Daten in der Finanz-, Regierungs- oder Gesundheitsbranche befassen, haben zu viele Informationen, als dass herkömmliche ER, Datensatzverknüpfung und Deduplizierung richtig funktionieren könnten. Die Geschäftsregeln, die für das Funktionieren der Algorithmen erforderlich sind, müssten viel größere Daten berücksichtigen, um konsistent zu funktionieren.
So hängt zum Beispiel die Blockierungstechnik, die bei der Suche nach Duplikaten zur Begrenzung nicht übereinstimmender Paare eingesetzt wird, von der Qualität der Datensatzfelder ab. Wenn Sie Felder mit Fehlern, fehlenden Werten und Variationen haben, können Sie Daten in die falschen Blöcke einfügen und mit einer höheren Anzahl von falsch-negativen Ergebnissen rechnen.
3. Manuelles ER ist kompliziert
Es ist nicht ungewöhnlich, dass sich Unternehmen oder Institutionen, die mit großen Datenmengen zu tun haben, für interne ER-Projekte entscheiden. Der Grund dafür ist, dass sie auf technische Ressourcen (Software-Ingenieure, Berater, Datenbankadministratoren) zurückgreifen können, ohne eines der auf dem Markt erhältlichen Entity Resolution Tools kaufen zu müssen.
Dies birgt einige Probleme in sich. Erstens ist die Entitätsauflösung keine Teilmenge der Softwareentwicklung. Sicher, es gibt öffentlich verfügbare Algorithmen und Blockierungstechniken, die nützlich sein könnten. Aber im Großen und Ganzen sind die erforderlichen Fähigkeiten sehr unterschiedlich. Das muss der Benutzer tun:
- Kombinieren unterschiedlicher unstrukturierter und strukturierter Datenquellen
- Achten Sie auf verschiedene Arten von Kodierungen, Spitznamen und Variationen, um die Genauigkeit zu erhöhen.
- Wissen, wie man Datensätze für verschiedene Verwendungszwecke auflöst
- Sicherstellen, dass verschiedene Abgleichtechniken einander ergänzen, um Konsistenz zu gewährleisten
Es kann unwahrscheinlich sein, dass der richtige Benutzer alle diese Kriterien erfüllt, und selbst wenn dies möglich ist, besteht das Risiko, dass er das Unternehmen verlässt, was das gesamte Projekt auf Eis legen kann.
4 Gründe, warum Entity Resolution Tools besser sind
Entitätsauflösungstools können viele Vorteile bieten, die herkömmliche ER nicht bieten können. Dazu gehören:
1. Höhere Treffergenauigkeit
Spezielle Tools zur Entitätsauflösung, die über hochentwickelte Fuzzy-Matching-Algorithmen und Entitätsauflösungsfunktionen verfügen, können weitaus bessere Ergebnisse bei der Verknüpfung und Deduplizierung von Datensätzen erzielen als herkömmliche ER-Algorithmen.
Bei heterogenen Datenbeständen kann die Feststellung der Ähnlichkeit zweier Datensätze aufgrund der unterschiedlichen Arten von Entitäten, Kodierungen, Formatierungen und Sprachen außerordentlich schwierig sein. Auch Schemaänderungen können ein Problem darstellen. Organisationen des Gesundheitswesens verwenden beispielsweise sowohl SQL- als auch NoSQL-basierte Datenbanken, und die Konvertierung aller Daten in ein vordefiniertes Schema durch Schema-Matching und Datenaustausch kann riskant sein, da dabei viele wertvolle Informationen verloren gehen können.
Darüber hinaus muss ein Datenanalytiker unter Umständen mehrere String-Metriken verwenden, um Fuzzy Matching effektiv durchzuführen, z. B. Levenshtein-Distanz, Jaro-Winkler-Distanz, Damerau-Levenshtein-Distanz und andere. Es kann problematisch sein, all diese Faktoren manuell einzubeziehen, um die Treffergenauigkeit zu verbessern.
Entity-Resolution-Tools hingegen können Datensätze nahtlos miteinander verknüpfen, indem sie eine breite Palette von String-Metriken und anderen Algorithmen einsetzen, um bessere Übereinstimmungsergebnisse zu erzielen.
2. Geringere Zeit-bis-zum-Ersten-Ergebnis
In den meisten Fällen ist der Zeitfaktor bei ER-Projekten entscheidend, insbesondere bei Stammdatenmanagement-Initiativen (MDM), die eine einzige Quelle der Wahrheit erfordern. Die Informationen über ein Unternehmen können sich innerhalb von Wochen oder Monaten schnell ändern, was ernsthafte Risiken für die Datenqualität mit sich bringen kann.
Nehmen wir an, eine B2B-Vertriebs- und Marketingorganisation möchte Kampagnen für ihre Top-Kunden durchführen. Idealerweise möchte sie sicherstellen, dass die anvisierten Kunden nicht den Arbeitsplatz gewechselt, ihren Titel gewechselt oder sich zur Ruhe gesetzt haben, bevor sie ihre Marketingausgaben verschwendet. In solchen Fällen ist es von entscheidender Bedeutung, ER innerhalb einer bestimmten Frist zu erledigen.
ER kann, wenn es manuell durchgeführt wird, mehr als 6 Monate dauern, und in dieser Zeit können viele Datensätze in den Datenbanken veraltet und ungenau sein. Tools zur Entitätsauflösung können jedoch die Hälfte der Zeit in Anspruch nehmen, und fortschrittlichere Tools können die Zeit bis zum ersten Ergebnis auf 15 Minuten verkürzen.
3. Bessere Skalierbarkeit
Tools zur Entitätsauflösung sind weitaus geschickter bei der Aufnahme von Daten aus mehreren Punkten und führen Datensatzverknüpfung, Deduplizierung und Bereinigungsaufgaben in einem viel größeren Umfang durch. In staatlichen Datenbanken wie denen für Steuererhebungen und Volkszählungen werden Millionen (wenn nicht Billionen) von Datensätzen gespeichert. Eine staatliche Einrichtung, die sich für ER zur Betrugsprävention entscheidet, wäre beispielsweise auf die Verwendung manueller ER-Ansätze und Algorithmen beschränkt. Ein Benutzer würde mit den Daten, die bearbeitet werden müssen, überschwemmt werden, und alle Geschäftsregeln für Blockierungstechniken – zur Minimierung der Anzahl ähnlicher Vergleiche – wären nutzlos.
Tools zur Entitätsauflösung können jedoch nicht nur Daten aus verschiedenen Quellen importieren, sondern auch sicherstellen, dass die ER-Effizienz über große Datenmengen hinweg intakt bleibt.
4. Kostenersparnis
Tools zur Entitätsauflösung, insbesondere für Anwendungen auf Unternehmensebene, können eine beträchtliche Investition darstellen. Datenexperten, die mit ER betraut sind, könnten allein aus diesem Grund zögern, eine Entscheidung zu treffen. Sie könnten argumentieren, dass eine manuelle Bearbeitung viel kostengünstiger wäre und ihre Chancen auf eine Beförderung verbessern würde.
Auch wenn dies auf den ersten Blick vernünftig klingt, können die Kosten für Projektverzögerungen, schlechte Abgleichgenauigkeit und Arbeitsressourcen am Ende höher sein als die eines ER-Tools.
Wie man die richtige Software zur Auflösung von Entitäten auswählt
Ebenso wichtig ist die Wahl der richtigen Software zur Auflösung von Entitäten. Viele Tools zur Entitätsauflösung unterscheiden sich in ihren Funktionen, ihrem Umfang und ihrem Wert.
Unterschiedliche Datenquellen importieren
Unternehmen können Daten in einer Vielzahl von Formaten und Quellen speichern, z. B. in Excel, in Dateien mit Trennzeichen, in Webanwendungen, Datenbanken und CRM-Systemen. Eine Software zur Entitätsauflösung muss in der Lage sein, Daten aus unterschiedlichen Quellen für den jeweiligen Anwendungsfall zu importieren.
Das Importmodul von DataMatch Enterprise ermöglicht es Ihnen, Daten in verschiedenen Formaten zu importieren, wie oben gezeigt.
Profilierung und Bereinigung von Daten im großen Maßstab
Die richtige Software zur Entitätsauflösung muss auch in der Lage sein, ein Profil zu erstellen und die Daten zu bereinigen, bevor die Deduplizierung und Datensatzverknüpfung durchgeführt wird. DataMatch Enterprise kann mithilfe von vorgefertigten Mustern, die auf Regex-Ausdrücken basieren, gültige und ungültige Datensätze, ungültige, eindeutige, führende und nachfolgende Leerzeichen und vieles mehr bestimmen.
Sobald ein Profil erstellt ist, können die Daten mit verschiedenen Funktionen bereinigt werden, wie z. B:
- Felder zusammenführen
- Zu entfernende Zeichen
- Zu ersetzende Zeichen
- Zu entfernende Nummern und mehr

Robuste Matching-Fähigkeiten
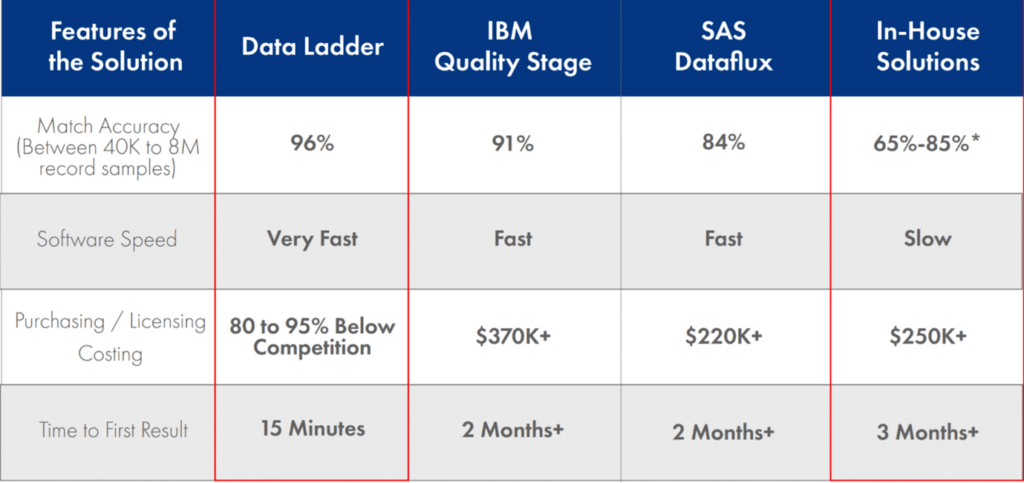
Es gibt viele Tools zur Entitätsauflösung, die behaupten, eine hohe Trefferquote zu erzielen. Die Abgleichsgenauigkeit hängt jedoch davon ab, wie ausgeklügelt die Algorithmen sind, die zum Abgleich von Datensätzen innerhalb und zwischen mehreren Datensätzen verwendet werden. DataMatch Enterprise verwendet eine Reihe von Abgleichstypen (Exact, Fuzzy, Phonetic, string-metrics), um den Abstand zwischen den Entitäten zu ermitteln, und nutzt domänenspezifische Bibliotheken (Spitznamen, Adressen, Telefonnummern), um eine höhere Trefferquote als in der Industrie zu erzielen.
Eine unabhängige Studie der Curtin University ergab, dass die Abgleichsgenauigkeit von DataMatch die anderer Anbieter wie IBMs Quality Stage und SAS Dataflux übertraf.
Ende Anmerkung
So wichtig ER für Unternehmen auch ist, die manuelle Durchführung von Deduplizierung, Datensatzverknüpfung und anderen ER-Aufgaben stößt an ernste Grenzen, wenn es darum geht, Daten über Millionen und Billionen von Datensätzen abzugleichen. Mit einer Software zur Entitätsauflösung wie DataMatch Enterprise sind Unternehmen in einer weitaus besseren Position, um ihre Geschäftsziele unter den Gesichtspunkten der Skalierbarkeit, der Kosten und der Ergebnisse zu erreichen.
Für weitere Informationen zu DataMatch Enterprise klicken Sie auf die Seite Entity Resolution oder kontaktieren Sie uns, um mit unserem Vertriebsteam in Kontakt zu treten.

Wie die besten Fuzzy-Matching-Lösungen funktionieren: Kombination von bewährten und eigenen Algorithmen
Starten Sie noch heute Ihren kostenlosen Test
Oops! Wir konnten dein Formular nicht lokalisieren.



