





























Last Updated on janvier 1, 2026
Des données structurées sales et non structurées, une douzaine de variantes de noms et des définitions de champs incohérentes dans des sources disparates. Cette boîte de Pandore est un risque professionnel presque incontournable pour tout analyste de données travaillant sur un projet impliquant des milliers d’enregistrements. Et les implications sont tout sauf ordinaires :
- Les institutions financières mondiales se sont vu infliger des amendes de 5,6 milliards de dollars en raison du non-respect des règles de conformité en 2020.
- Selon une étude de Black Book Market Research, une mauvaise correspondance entre les patients et les organismes de soins de santé a entraîné le refus d’un tiers des demandes de remboursement.
- Lesreprésentants commerciaux perdent 25 % de leur temps à cause de mauvaises données sur les prospects.
Donc, voici la question clé : Existe-t-il un meilleur moyen de surmonter ces problèmes ?
Contrairement aux outils de résolution d’entités qui peuvent effectuer une ingestion de données à partir de plusieurs points et trouver des correspondances non exactes à des vitesses inégalées, la résolution manuelle d’entités à l’aide d’algorithmes et de techniques complexes s’avère être une entreprise très coûteuse (sans parler de l’épuisement). Selon une étude de Gartner , la mauvaise qualité des données coûte 15 millions de dollars par an aux entreprises, en particulier à celles dont les activités s’étendent sur plusieurs territoires et unités commerciales.
Ce guide détaillé vous expliquera comment fonctionne la résolution des entités, pourquoi la résolution manuelle des entités est problématique pour les entreprises et pourquoi il est optimal d’opter pour des outils de résolution des entités.
Qu’est-ce que la résolution d’entités ?
L’ouvrage Entity Resolution and Information Quality décrit la résolution d’entité (ER) comme « la détermination de l’équivalence (référence à la même entité) ou de la non-équivalence (référence à des entités différentes) de références à des entités du monde réel ».
En d’autres termes, il s’agit du processus d’identification et de liaison de plusieurs enregistrements à la même entité lorsque les enregistrements sont décrits différemment et vice versa.
Par exemple, il pose la question suivante : les entrées de données « Jon Snow » et « John Snowden » sont-elles la même personne ou sont-elles deux personnes totalement différentes ?
Cela vaut également pour les adresses, les codes postaux et zip, les numéros de sécurité sociale, etc.
L’ER s’effectue en examinant la similitude de plusieurs enregistrements en les comparant à des identifiants uniques. Il s’agit des enregistrements les moins susceptibles de changer au fil du temps (tels que les numéros de sécurité sociale, les dates de naissance, les codes postaux, etc.) Pour savoir si ces enregistrements sont identiques ou non, il faut les comparer à un identifiant unique de la manière suivante :
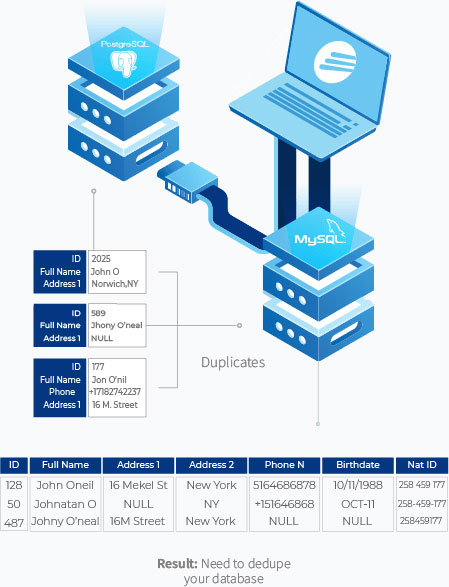
Dans l’exemple ci-dessus, John Oneil, Johnathan O et Johny O’neal sont tous appariés grâce à un identifiant unique qui est le numéro d’identification national.
L’ER consiste généralement à relier et à faire correspondre des données entre plusieurs enregistrements afin de trouver d’éventuels doublons et de supprimer les doublons correspondants, ce qui explique pourquoi il est utilisé de manière interchangeable :
- Liaison des enregistrements
- Correspondance floue
- Fusion/épuration
- Regroupement d’entités
- Déduplication et plus
Comment la résolution des entités fonctionne en pratique
Une activité de RE se déroule en plusieurs étapes. Examinons-les plus en détail.
Ingestion
Il s’agit de regrouper toutes les données provenant de plusieurs sources sous une seule vue centralisée. Les données d’une entreprise sont souvent éparpillées dans des bases de données, des systèmes de gestion de la relation client, des fichiers Excel et PDF disparates et dans des formats de données tels que des chaînes de caractères, des dates ou les deux.
Par exemple, une grande entreprise de services financiers et de prêts hypothécaires peut avoir une base de données centrale en MySQL, les données des formulaires de réclamation en PDF et sa liste de propriétaires en Excel. L’importation des données de toutes ces sources permettra de préparer le terrain pour relier les enregistrements et trouver les doublons. Pour plus d’informations, cliquez ici.
Dans d’autres cas, la combinaison de différentes sources en une seule peut également signifier la modification du schéma des bases de données en un schéma prédéfini pour un traitement ultérieur.
Profilage
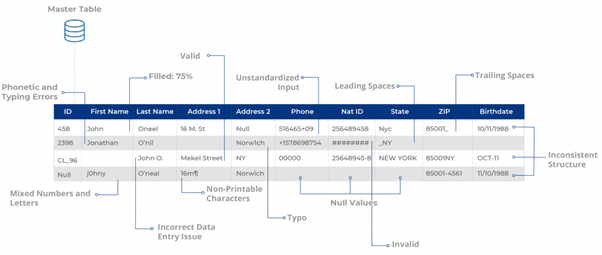
Une fois les sources de données importées, l’étape suivante consiste à vérifier leur santé afin d’identifier tout type d’anomalie statistique sous la forme de données manquantes et inexactes et de problèmes d’encodage (c’est-à-dire minuscules et majuscules). Idéalement, un analyste de données essaiera de trouver les zones de problèmes potentiels qui doivent être corrigées avant de procéder à tout type de nettoyage et de résolution d’entités.
Ici, un utilisateur peut vouloir vérifier si les champs sont conformes aux RegEx – des expressions régulières qui déterminent les types de chaînes de caractères pour différents champs de données. Sur cette base, l’utilisateur peut déterminer combien d’enregistrements sont soit impurs, soit non conformes à un encodage donné.
Cela peut aider à révéler des statistiques cruciales, y compris mais sans s’y limiter :
- Présence de valeurs nulles, par exemple des adresses électroniques manquantes dans les formulaires de génération de prospects.
- Nombre d’enregistrements avec des espaces avant et après, par exemple David Matthews.
- Problèmes de ponctuation, par exemple hotmail,com au lieu de Hotmail.com
- Questions relatives à l’habillage, par exemple : NEW YORK , dAVID MATTHEWS, MICROSOFT
- Présence de lettres dans les chiffres et vice versa, par exemple TEL-516 570-9251 pour le numéro de contact et NJ43 pour l’État.
Déduplication et liaison d’enregistrements
Grâce à la mise en correspondance, plusieurs enregistrements qui sont potentiellement liés à la même entité sont réunis pour supprimer les doublons, ou dédupliqués à l’aide d’identifiants uniques. Les techniques de mise en correspondance peuvent varier en fonction du type de champ, par exemple exact, flou ou phonétique.
Pour les noms, par exemple, la correspondance exacte est souvent utilisée lorsque des identifiants uniques tels que le SSN ou l’adresse sont exacts dans l’ensemble de la base de données. Si les identifiants uniques sont inexacts ou invalides, la correspondance floue s’avère être une forme de correspondance beaucoup plus fiable pour apparier facilement deux enregistrements similaires (par exemple, John Snow et Jon Snowden).
Dans la plupart des cas, la déduplication et la liaison d’enregistrements sont considérées comme une seule et même chose. Toutefois, une différence essentielle réside dans le fait que la première consiste à détecter les doublons et à les consolider au sein du même ensemble de données (c’est-à-dire à normaliser le schéma), tandis que la seconde consiste à faire correspondre les données dédupliquées à d’autres ensembles de données ou sources de données.
Canonisation
La canonisation est une autre étape clé de la RE où les entités qui ont plusieurs représentations sont converties en une forme standard. Il s’agit de prendre les informations les plus complètes comme enregistrement final et de laisser de côté les données aberrantes ou bruyantes qui pourraient fausser les données.
Blocage de
Lorsqu’il s’agit de trouver des correspondances pour une entité parmi des centaines et des milliers d’enregistrements, les combinaisons potentielles qui pourraient donner les bonnes correspondances peuvent se chiffrer en milliers (voire en millions). Pour éviter ce problème, le blocage est utilisé pour limiter les appariements potentiels à l’aide de règles de gestion spécifiques.
Les défis de la résolution des entités
Malgré les nombreuses approches et techniques disponibles pour l’ER, celle-ci présente des lacunes sur plusieurs fronts. Il s’agit notamment de :
1. La RE ne fonctionne bien que si les données sont riches et cohérentes
Le plus gros problème de la RE est peut-être que l’exactitude des correspondances dépend de la richesse des données et de leur cohérence entre les ensembles de données.
Par exemple, la correspondance déterministe est assez simple. Disons que vous avez « Mike Rogers » dans la base de données 1 et « Mike Rogers » dans la base de données 2. Grâce à une simple liaison d’enregistrements (ou correspondance exacte), nous pouvons facilement identifier qu’un enregistrement est le double d’un autre.
Cependant, la correspondance probabiliste, où des enregistrements de données similaires existent sous la forme de fautes d’orthographe, d’abréviations ou de surnoms (par exemple, « Mike Rogers » dans la base de données 1 et « Michael Rogers » dans la base de données 2), est une autre histoire. Un identifiant unique (tel que l’adresse, le numéro de sécurité sociale ou la date de naissance) peut ne pas être cohérent dans toutes les bases de données et toute forme de correspondance exacte ou déterministe deviendra presque impossible, en particulier lorsqu’il s’agit de données volumineuses.
2. Les algorithmes d’urgence ne sont pas évolutifs
Les projets d’entreprise Big Data qui traitent des téraoctets de données dans les secteurs de la finance, de l’administration ou des soins de santé contiennent trop d’informations pour que les ER, les liens entre les enregistrements et la déduplication traditionnels puissent fonctionner correctement. Les règles de gestion requises pour faire fonctionner les algorithmes devraient prendre en compte des données bien plus importantes pour fonctionner de manière cohérente.
Par exemple, la technique de blocage – utilisée pour limiter les paires mal assorties lors de la recherche de doublons – dépend de la qualité des champs de l’enregistrement. Si vous avez des champs contenant des erreurs, des valeurs manquantes et des variations, vous pouvez finir par insérer des données dans les mauvais blocs et être confronté à un nombre plus élevé de faux négatifs.
3. Le RE manuel est complexe
Il n’est pas rare que des entreprises ou des institutions traitant de grands volumes de données optent pour des projets de RE en interne. La raison en est qu’ils peuvent utiliser des ressources techniques (ingénieurs logiciels, consultants, administrateurs de bases de données) sans avoir à acheter l’un des outils de résolution d’entités disponibles sur le marché.
Il y a quelques problèmes avec cela. Tout d’abord, la résolution d’entités n’est pas un sous-ensemble du développement de logiciels. Bien sûr, il existe des algorithmes et des techniques de blocage accessibles au public qui pourraient être utiles. Mais dans l’ensemble, les compétences requises sont très différentes. L’utilisateur devra :
- Combiner des sources de données disparates, structurées et non structurées.
- Soyez conscient des différents types d’encodage, des surnoms, des variations pour la précision de la correspondance.
- Savoir comment résoudre les enregistrements par entité pour différents cas d’utilisation
- Veiller à ce que les différentes techniques d’appariement se complètent pour assurer la cohérence
Cocher toutes ces cases pour le bon utilisateur peut être improbable, et même si c’est possible, vous avez le risque qu’il quitte l’entreprise, ce qui peut mettre tout le projet en suspens.
4 raisons pour lesquelles les outils de résolution d’entités sont meilleurs
Les outils de résolution d’entités peuvent offrir de nombreux avantages que les ER traditionnels ne peuvent pas offrir. Il s’agit notamment de :
1. Plus grande précision de l’appariement
Les outils de résolution d’entités dédiés, dotés d’algorithmes de correspondance floue sophistiqués et de capacités de résolution d’entités, peuvent donner de bien meilleurs résultats de liaison et de dédoublonnage d’enregistrements que les algorithmes ER courants.
Lorsqu’on traite des ensembles de données hétérogènes, il peut s’avérer exceptionnellement difficile de trouver la similarité de deux enregistrements en raison des différents types d’entités, de l’encodage, des problèmes de formatage et des langues. Les changements de schéma peuvent également poser un problème. Les organismes de santé, par exemple, utilisent des bases de données SQL et NoSQL. Convertir toutes les données dans un schéma prédéfini par le biais de la correspondance des schémas et de l’échange de données peut être risqué, car de nombreuses informations précieuses peuvent être perdues au cours du processus.
En outre, un analyste de données peut être amené à utiliser plusieurs mesures de chaînes de caractères pour effectuer une correspondance floue efficace, telles que la distance de Levenshtein, la distance de Jaro-Winkler, la distance de Damerau-Levenshtein, etc. L’incorporation manuelle de tous ces éléments pour améliorer la précision de la correspondance peut être problématique.
Les outils de résolution d’entités, en revanche, peuvent relier les enregistrements de manière transparente en utilisant un large éventail de paramètres de chaîne et d’autres algorithmes pour obtenir des résultats de correspondance plus élevés.
2. Réduction du délai d’obtention du premier résultat
Dans la plupart des cas, le temps est un facteur critique pour les projets ER, notamment dans le cas des initiatives de gestion des données de référence (MDM) qui nécessitent une source unique de vérité. Les informations relatives à une entité peuvent rapidement changer en l’espace de quelques semaines ou de quelques mois, ce qui peut poser de sérieux risques pour la qualité des données.
Supposons qu’une organisation de vente et de marketing B2B souhaite lancer des campagnes sur ses comptes de premier plan. Idéalement, elle voudra s’assurer que ses prospects ciblés n’ont pas changé d’emploi, de titre ou pris leur retraite avant de gaspiller ses dépenses de marketing. Dans de tels cas, il est essentiel d’effectuer l’ER dans les délais impartis.
L’ER, si elle est effectuée manuellement, peut prendre jusqu’à 6 mois et plus, période pendant laquelle de nombreux enregistrements dans les bases de données peuvent devenir obsolètes et inexacts. Les outils de résolution d’entités, en revanche, peuvent prendre deux fois moins de temps et les outils plus avancés peuvent donner un délai de premier résultat de 15 minutes.
3. Une meilleure évolutivité
Les outils de résolution d’entités sont beaucoup plus aptes à ingérer des données provenant de plusieurs points et à exécuter des tâches de couplage, de déduplication et de nettoyage d’ enregistrements à une échelle beaucoup plus grande. Les bases de données gouvernementales, telles que celles contenant les données de collecte des impôts et de recensement, stockent des millions (voire des trillions) d’enregistrements. Une institution gouvernementale décidant de faire de la RE pour la prévention de la fraude, par exemple, serait limitée dans l’utilisation d’approches de RE manuelles et d’algorithmes. L’utilisateur serait submergé par les données qu’il doit traiter, et toute règle commerciale relative aux techniques de blocage – pour minimiser le nombre de comparaisons similaires – serait futile.
Les outils de résolution d’entités, toutefois, peuvent non seulement importer des données provenant de diverses sources, mais aussi veiller à ce que leur efficacité en matière de RE reste intacte sur de grands volumes de données.
4. Économies de coûts
Les outils de résolution d’entités, en particulier pour les applications au niveau de l’entreprise, peuvent représenter un investissement non négligeable. Les professionnels des données chargés de l’ER peuvent être réticents à l’idée d’opter pour cette seule raison. Ils peuvent se dire que le faire manuellement serait bien plus rentable et améliorerait leurs chances de promotion.
Bien que cela puisse sembler raisonnable à première vue, les coûts liés aux retards du projet, à la faible précision de la correspondance et aux ressources en main-d’œuvre peuvent finir par devenir plus élevés que ceux d’un outil de RE.
Comment choisir le bon logiciel de résolution d’entités
Le choix du bon logiciel de résolution d’entités est tout aussi important. De nombreux outils de résolution d’entités diffèrent par leurs caractéristiques, leur portée et leur valeur.
Importer des sources de données distinctes
Les entreprises peuvent avoir des données stockées dans une grande variété de formats et de sources tels qu’Excel, des fichiers délimités, des applications web, des bases de données et des CRM. Un logiciel de résolution d’entités doit être capable d’importer des données de sources disparates pour le cas d’utilisation spécifique.
Le module d’importation de DataMatch Enterprise vous permet d’obtenir des données dans différents formats, comme indiqué ci-dessus.
Profilage et nettoyage des données à grande échelle
Le bon logiciel de résolution d’entités doit également être capable de profiler et de nettoyer les données avant tout effort de déduplication et de couplage d’enregistrements. DataMatch Enterprise, en utilisant des modèles prédéfinis basés sur des expressions Regex, peut déterminer les enregistrements valides et invalides, les enregistrements nuls, distincts, les espaces avant et après, etc.
Une fois le profil généré, les données peuvent ensuite être nettoyées à l’aide de diverses fonctionnalités telles que :
- Fusionner les champs
- Caractères à supprimer
- Caractères à remplacer
- Numéros à supprimer et plus encore

Capacités d’appariement robustes
Il existe de nombreux outils de résolution d’entités qui prétendent fournir un score de correspondance élevé. Cependant, la précision de la mise en correspondance est liée au degré de sophistication des algorithmes utilisés pour mettre en correspondance les enregistrements dans et entre plusieurs ensembles de données. DataMatch Enterprise utilise une gamme de types de correspondance (exacte, floue, phonétique, métrique des chaînes de caractères) pour établir la distance entre les entités et utilise des bibliothèques spécifiques au domaine (surnoms, adresses, numéros de téléphone) pour établir un score de correspondance supérieur à celui du secteur.
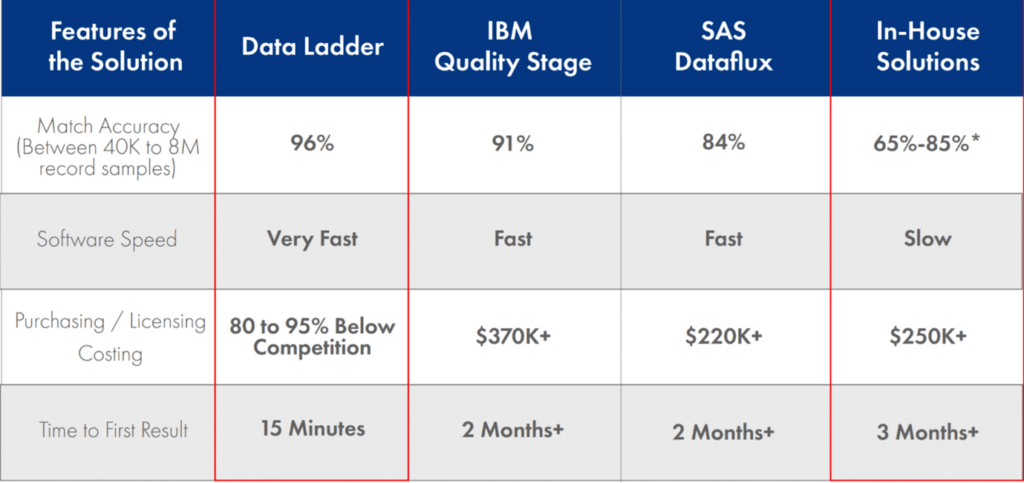
Une étude indépendante réalisée par l’université Curtin a révélé que la précision de la correspondance de DataMatch dépassait celle d’autres fournisseurs, notamment Quality Stage d’IBM et Dataflux de SAS.
Note de fin
Bien qu’il soit crucial pour les entreprises de procéder à l’ER, l’exécution manuelle de la déduplication, du couplage d’enregistrements et d’autres tâches d’ER présente de sérieuses limites lorsqu’il s’agit de faire correspondre des données sur des millions et des trillions d’enregistrements. En utilisant un logiciel de résolution d’entités comme DataMatch Enterprise, les entreprises sont en bien meilleure position pour atteindre leurs objectifs commerciaux du point de vue de l’évolutivité, des coûts et des résultats.
Pour plus d’informations sur DataMatch Enterprise, cliquez sur la page de la solution Résolution d’entités ou contactez-nous pour entrer en contact avec notre équipe commerciale.

Comment fonctionnent les meilleures solutions de correspondance floue de leur catégorie : Combinaison d’algorithmes établis et exclusifs
Commencez votre essai gratuit aujourd’hui



