































Last Updated on July 2, 2026
Entity resolution is the process of identifying, linking, and consolidating records that refer to the same real-world entity across disparate data sources, even when those records are inconsistent, incomplete, or formatted differently. It’s also one of the most underestimated dependencies in enterprise data work. Get ER wrong and every downstream process from MDM and customer analytics all the way to fraud detection inherits the problem.
This guide covers how entity resolution works in practice, where it consistently breaks down at scale, and what to look for when evaluating ER software for a large-scale data environment.
What is Entity Resolution?
Entity Resolution and Information Quality defines entity resolution (ER) as ‘determining when references to real-world entities are equivalent (refer to the same real world entity) or not equivalent (refer to different entities).’
In simple words, it is the process of identifying and linking multiple records that refer to the same entity when those records contain variations in names, addresses, or other attributes.
This process eliminates duplicate, inconsistent, or conflicting records while also distinguishing records that belong to different entities to ensure that organizations maintain a single, accurate view of their data.
For example, if an organization has customer records stored in different databases under slightly different names, such as Jon Snow in a CRM system and John Snowden in an e-commerce database, an entity resolution software analyzes various data attributes to determine whether they represent the same person or different individuals.
The entity resolution process involves looking at the similarity of multiple records by checking it against unique identifiers. These are data points that are least likely to change overtime, such as social security numbers, date of birth, or postal codes. Here’s how it’s done:
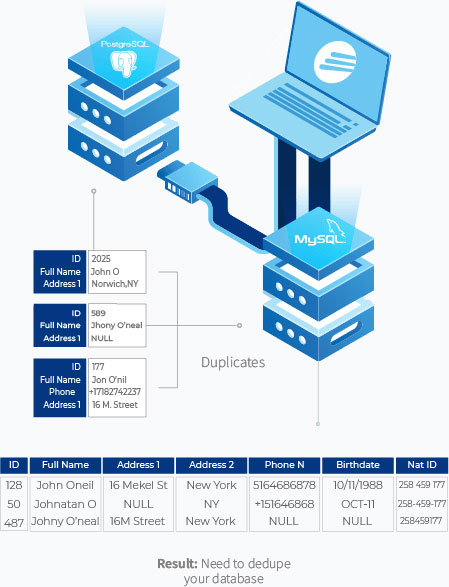
In the above example, John Oneil, Johnathan O, and Johny O’neal are all matched through a unique identifier which is the national ID number.
Deterministic vs. Probabilistic Matching
| Deterministic | Probabilistic | |
| Also called | Rules-based, exact matching | Fuzzy matching, ML-based |
| How it works | Matches on identical shared identifiers (SSN, email, national ID) | Scores similarity across multiple attributes using weighted algorithms |
| Best for | Clean, standardized data with reliable unique IDs | Messy, incomplete, or variant-heavy data |
| Risk | Misses matches when identifiers vary even slightly | Can produce false positives without proper threshold tuning |
| Enterprise reality | Rarely sufficient on its own | Most ER at scale relies on probabilistic or hybrid approaches |
ER involves linking and matching data across multiple records to find possible duplicates and removing the matched duplicates which is why it is often used interchangeably with the following terms:
- Record Linking – Connecting relevant records across different datasets.
- Fuzzy Matching – Identifying similarities between records even when they are not exact matches or when unique identifiers are not available.
- Merge/Purge – Combining and cleaning up duplicate records.
- Entity Clustering – Grouping related records together to unify fragmented data.
- Deduplication – Removing duplicate records from a dataset.
How Entity Resolution Works in Practice
Entity resolution follows a structured process to connect disparate data sources and unify, cleanse, and link records. Here’s a breakdown of the key steps:
1. Data Ingestion
Enterprises typically have data spread across databases, CRMs, flat files, PDFs, and cloud applications each of which have different schemas, encodings, and update cycles. Before any matching can happen, all of that needs to land in a common environment where record-level comparison is possible.
Consider a large mortgage servicer managing a central MySQL database alongside PDF-based claims forms and homeowner records in Excel. Schema inconsistencies between these sources such as different field names, date formats, identifier structures may mean that raw ingestion alone isn’t sufficient. In many projects, schema normalization happens in parallel with ingestion, and how well that’s handled directly affects what the matching layer can work with downstream.
2. Data Profiling
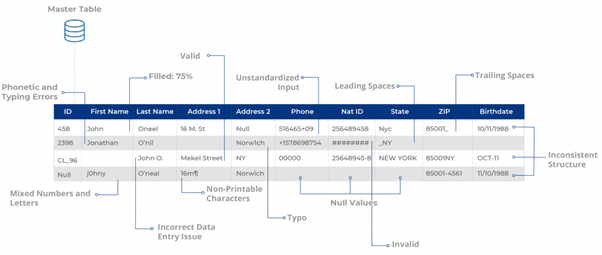
Profiling typically surfaces: null or missing values in critical fields (email, date of birth, national ID); leading and trailing whitespace that defeats exact-match logic; punctuation errors in domains and addresses; casing inconsistencies across free-text fields; and mixed data types where numbers contain embedded non-numeric characters. Each of these categories has a different downstream impact. For example, a missing SSN forces the matching layer into probabilistic mode, while casing inconsistencies can be resolved through standardization before any matching runs.
Common data issues that profiling can help reveal include (but not limited to):
- Nulls values – e.g., missing email addresses in lead generation forms
- Leading/trailing spaces – e.g., “ David Matthews ” instead of “David Matthews”
- Punctuation errors – e.g., “hotmail,com” instead of “hotmail.com”
- Casing inconsistencies – e.g., “New york,” “dAVID mAATHEWS,” “MICROSOFT”
- Mixed data types (presence of letters in numbers and vice versa) – e.g., “TEL- 516 570-9251” (for contact number) or “NJ43” (for state)
3. Deduplication and Record Linking
Through matching, multiple records that are potentially related to the same entity are joined to remove duplicates, or deduplicated using unique identifiers. The matching techniques can vary depending on the type of field and data quality such as exact matching, fuzzy matching, or phonetic matching.
For instance:
- For variations in names, exact matching is often used where unique identifiers such as SSN or address are accurate in the entire dataset.
- If the unique identifiers are inaccurate or invalid, fuzzy matching proves to be a much more reliable form of data matching to pair two similar records (e.g., John Snow and Jon Snowden).
Deduplication and record linking, in most cases, are understood to be one and the same thing. However, a key difference is that the former is about detecting duplicates and consolidating information within the same dataset (i.e. normalizing the schema) while the latter is about matching and merging the deduplicated data across multiple datasets or data sources.
4. Canonicalization
Canonicalization is another key step in entity resolution for enterprise data projects. It involves converting multiple data representations into a standard form. This is done by:
- Selecting the most complete and accurate version of an entity’s record
- Leaving out outliers or noise (inconsistent or redundant variations) that could distort the data
- Creating a golden record that represents the entity with high confidence
For example, if multiple entries for “Microsoft Corporation” exist as “Microsoft, Inc.”, “MS Corp.”, and “Microsoft Corp.”, canonicalization would combine them into a single, standardized, accurate, representation.
5. Blocking
Matching entities across large datasets – as required in enterprise data projects – can involve billions of comparisons. Blocking optimizes this process by grouping records into smaller subsets based on specific business rules (e.g., ZIP code or last name). This significantly reduces the number of comparisons while maintaining data accuracy.
Challenges of Entity Resolution
Despite the many approaches and techniques available for entity resolution, it falls short on several fronts. These include:
1. ER Works Well Only If the Data Is Rich and Consistent
Match accuracy in any ER system is only as good as the data it operates on — and most enterprise datasets are neither rich nor consistent.
For example:
If you have ‘Mike Rogers’ in two databases, an exact match or simple record linking can easily identify that one of them is a duplicate record. This is called deterministic matching and it is quite straightforward.
However, when you’re dealing with similar records with inconsistencies, such as misspellings, abbreviations, or nicknames (e.g., ‘Mike Rogers in one database and ‘Michael Rogers’ in another), it becomes difficult to match them. This phenomenon is called probabilistic matching and it becomes even more challenging when unique identifiers (such as address, SSN, or birth date) are missing or inconsistent across datasets, making it nearly impossible to perform any kind of deterministic matching, especially when handling large volumes of data.
2. ER Algorithms Don’t Scale Well
Traditional entity resolution techniques often fail when applied to big data environments like financial, government, and healthcare industries, where records span terabytes of data.
The business rules required to make the algorithms work would have to account for far larger data to work consistently. For example, the blocking technique – used to limit mismatched pairs when finding duplicates – is dependent on the quality of the record fields. If you have fields containing errors, missing values, or variations, you can end up inserting data into the wrong blocks and face higher false negatives.
3. Manual Entity Resolution is Complex and Resource-Intensive
It is not uncommon for organizations dealing with large volumes of data to opt for handling entity resolution projects in-house. The rationale behind this decision is that they can make use of their existing technical resources (software engineers, consultants, database administrators) without having to purchase any of the entity resolution tools available in the market.
However, there are a few problems with this approach.
Firstly, entity resolution isn’t a subset of software development. Sure, there are publicly available algorithms and blocking techniques that might be useful. But in the grand scheme of things, the skills it requires are vastly different, as the user will have to:
- Combine disparate unstructured and structured data sources.
- Know about encoding variations, nicknames, and linguistic differences very well for accurate matching.
- Adapt ER rules for different business use cases (e.g., customer data deduplication vs. fraud detection).
- Ensure that different matching techniques complement each other for consistency and reliable results.
It’s quite unlikely for a person to tick all these boxes, and even if it is possible, you have the risk of them leaving the firm. If the person leading or managing an ER project leaves the company, it can bring the entire initiative to a halt.
4 Reasons Why Entity Resolution Tools Are Better
Entity resolution tools offer significant advantages over traditional manual or rule-based ER methods. These include:
1. Higher Match Accuracy
Dedicated entity resolution tools that have sophisticated fuzzy matching algorithms and entity resolving capabilities in place can give far better record linking and deduplication results than common ER algorithms.
Matching records across heterogeneous datasets (e.g., SQL and NoSQL databases, spreadsheets, PDFs) can be exceptionally difficult due to different types of entities, encoding, formatting, languages, and schemas. Converting all this different type of data into a pre-defined schema through schema-matching and data exchange is a risky process and can result in the loss of valuable information.
Moreover, accurate fuzzy matching may require data analysts to use multiple string-metrics, such as Levenshtein Distance, Jaro-Winkler, and Damerau-Levenshtein. Implementing these manually is resource-intensive.
Entity resolutions tools incorporate a wide range of matching algorithms. They can seamlessly link records and significantly improve match accuracy and consistency across datasets.
2. Reduced Time-To-First Result
In most cases, time is critical for ER projects, especially in the case of master data management (MDM) initiatives that require a single source of truth. However, manual entity resolution projects can take months. Considering that the information relating to an entity can quickly change within weeks, the slow pace of manual ER can pose serious data quality risks and lead to missed opportunities and poor decision-making.
Let’s say a B2B sales and marketing firm wants to run campaigns on its top-tier accounts, Ideally, it should confirm that its targeted prospects haven’t switched jobs, changed titles, or retired before wasting any marketing spend. A manual ER process taking 6+ months risk many records becoming outdated, obsolete, or inaccurate. Most entity resolution tools can reduce this time by 50%, while some even bring the time-to-first result down to mere 15 minutes.
3. Better Scalability
Entity resolution tools are designed to process large-scale datasets without compromising performance. They are far more adept at ingesting data from multiple sources and run record linkage, deduplication and cleansing tasks at much larger scales.
For example, a government institution performing ER to identify (and prevent) fraudulent tax filings would find manual ER approaches and algorithms severely restricting and overwhelming. The sheer volume of the data in government databases (they have millions, if not trillions, of records) and the complexity of blocking techniques would make the efforts futile.
Automated entity resolution tools, however, can streamline the process. They can not only import data from various sources, but also ensure the efficiency of the process remains intact across large data volumes.
4. Cost-Savings
Entity resolution tools, particularly for enterprise level applications, require a sizable investment. For this reason alone, many data professionals tasked with ER may be reluctant to get them. They may feel that manual ER is more cost-effective and a better way to showcase their expertise (and improve their chances of promotion). However, the costs of project delays, poor matching accuracy, and labor resources often end up exceeding the investment in an automated ER tool.
ER tools allow data professionals to focus on high-value tasks, rather than spending months on manual matching. By reducing data errors, enhancing operational efficiency, and improving decision-making, automated ER solutions provide better financial outcomes in the long run.
Entity Resolution Use Cases by Industry
| Industry | Common ER Use Case | Key Challenge | Outcome |
| Healthcare | Patient record deduplication | Nicknames, DOB variants, multiple EHR systems | Accurate patient history; reduced misdiagnosis risk |
| Banking & Finance | Customer 360 / KYC | Name variations, address changes, multiple account IDs | Single customer view; fraud detection; compliance |
| Insurance | Policy and claims deduplication | Inconsistent policyholder data across legacy systems | Reduced duplicate payouts; faster claims processing |
| Government | Citizen record linkage across agencies | Siloed databases with no shared identifiers | Fraud prevention; unified citizen services |
| Retail / E-commerce | Product catalog deduplication / SKU matching | Supplier naming inconsistencies, UOM differences | Cleaner inventory; accurate pricing and sourcing |
| Marketing Ops | CRM deduplication / lead matching | Fragmented contact data from multiple campaign tools | Reduced wasted outreach; higher conversion rates |
How to Choose the Right Entity Resolution Software
Many ER tools differ in features, scope and value. Selecting the right entity resolution software for your needs is critical to ensuring accurate record matching, deduplication, and data unification. Here are some key factors to consider when choosing an entity resolution tool for enterprise data project:
1. Support for Disparate Data Sources
Enterprise data is often stored in different formats and scattered across multiple platforms like Excel, databases, CRMs, web applications, and delimited text files. The right entity resolution software should seamlessly import data from all relevant sources for the specific use-case.
DataMatch Enterprise’s Import module allows you to source data in various formats as shown above, which ensures its compatibility with diverse enterprise environments.
2. Scalable Data Profiling and Cleansing
The right entity resolution software must also profile and clean the data before any deduplication and record linkage efforts. DataMatch Enterprise (DME), using pre-built patterns based on Regex expressions, can determine valid and invalid records, null values, distinct entries, leading and trailing spaces, duplicates, formatting issues, and other inconsistencies.
Once a profile is generated, the software should then provide data cleansing opportunities using various functionalities such as:
- Merging Fields – Consolidating multiple fields into one
- Removing Unwanted Characters – Cleaning up punctuation or extra spaces
- Replacing Characters – Standardizing inconsistencies in input data
- Removing Numbers – Stripping out non-essential numeric values
DataMatch Enterprise simplifies this process by using pre-built patterns based on Regex expressions to detect and cleanse invalid records at scale.

3. Advanced Matching Algorithms for Higher Accuracy
Many entity resolution tools claim to provide a high match score, but their effectiveness depends on how sophisticated the algorithms used to match records within and across multiple datasets are.
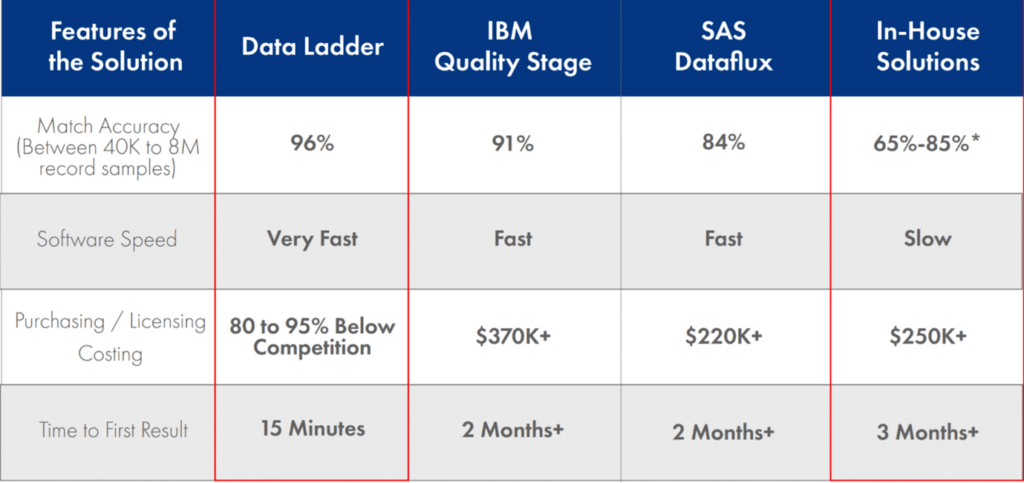
DataMatch Enterprise employs a range of advanced matching techniques (Exact, Fuzzy, Phonetic), and string-metrics algorithms to establish distance across entities and makes use of domain-specific libraries (nicknames, addresses, phone numbers) to provide a match accuracy rate that outperforms industry competitors.
An independent study done by Curtin University found that DME’s match accuracy surpassed those of other vendors, including IBM’s Quality Stage and SAS Dataflux.
Scale, Save, and Succeed with Entity Resolution Software
As crucial it is for enterprises to do ER, manually carrying out deduplication, record linkage and other entity resolution tasks have serious limits when handling large datasets. Manual entity resolution approaches simply cannot scale to handle millions – or trillions – of records effectively. Without the right tools, businesses face inaccurate matches, inefficiencies, and higher costs.
By using an advanced entity resolution software like DataMatch Enterprise, enterprises can streamline data unification, improve match accuracy, and scale effortlessly – all while reducing operational costs and enhancing decision-making.
Visit our Entity Resolution solution page or contact our sales team to see how DataMatch Enterprise (DME) can improve your data strategy.
Frequently Asked Questions (FAQs)
1. How can I assess the quality of my data before starting an entity resolution project?
Before initiating an entity resolution project, it’s crucial to understand the current state of your data. DataMatch Enterprise offers comprehensive data profiling tools that analyze your datasets for anomalies, missing values, and inconsistencies. This assessment helps in identifying potential issues that could affect matching accuracy and allows you to address them proactively.
2. How do I measure the success of an entity resolution project?
Success in entity resolution isn’t just about matching records – it’s about improving data usability. Key success metrics include match accuracy rates, reduction in duplicate records, improved data consistency, and the impact on downstream processes (e.g., better customer analytics or compliance reporting). DataMatch Enterprise provides match confidence scores and detailed reports to help you evaluate success.
3. What are the common mistakes enterprises make in entity resolution projects?
Some of the biggest mistakes include:
- Skipping data standardization before matching (leading to false positives or missed matches).
- Relying solely on exact matching, which often fails when names, addresses, or identifiers have variations.
- Ignoring the need for a feedback loop, where business users review and refine matching rules.
DataMatch Enterprise helps prevent these issues by offering data cleansing, fuzzy matching, and rule-tuning capabilities.
4. How much manual effort is required for an automated entity resolution process?
Even with advanced automation, some level of human review is necessary—especially for high-stakes decisions like merging customer or compliance records. The goal with entity resolution tools is to minimize manual work by:
- Using confidence scores to prioritize review-worthy matches.
- Allowing business users to fine-tune matching rules over time.
- Implementing workflow automation to integrate manual review seamlessly into your data pipeline.
DataMatch Enterprise automates most of entity resolution tasks while keeping humans in the loop for complex cases.
5. Can I integrate entity resolution results into my existing analytics and BI tools?
Yes! A common challenge in entity resolution is ensuring that resolved entities are usable across your tech stack. DataMatch Enterprise allows you to:
- Export clean, de-duplicated data in formats compatible with BI tools like Tableau and Power BI.
- Sync resolved entities back into CRM, ERP, and master data management (MDM) platforms.
- Schedule automated exports or use API integrations to keep data continuously updated.
6. What is the difference between entity resolution and deduplication?
Deduplication finds and removes duplicate records within a single dataset. Entity resolution works across datasets — it links records from different sources that refer to the same real-world entity, even when those records have no shared identifier and contain variations in names, addresses, or other attributes. In practice, deduplication is one step within a broader entity resolution process, not a synonym for it.
7. What is a golden record in entity resolution?
A golden record is the single, authoritative version of an entity’s data after all duplicate and variant records have been matched, merged, and canonicalized. It represents the most complete and accurate view of that entity across all source systems. Golden records are the primary output of entity resolution in master data management (MDM), CRM hygiene, and regulatory compliance workflows.
8. When does entity resolution require human review?
Fully automated entity resolution handles the clear matches and clear non-matches with confidence. Human review becomes necessary for records that fall in a middle confidence band — close enough to flag as potential matches but not close enough to merge automatically. In high-stakes contexts (patient records, financial compliance, fraud investigation), organizations often set tighter thresholds and route more edge cases to human reviewers, even at the cost of throughput. The goal of ER tooling is to minimize that review queue while keeping false positives out of the resolved output.
9. How does DataMatch Enterprise handle data privacy and security during the entity resolution process?
Data privacy and security are critical in any data processing activity. DataMatch Enterprise adheres to industry-standard security protocols to ensure that your data is protected throughout the process. It offers features like data encryption to safeguard sensitive information, which also helps your organization comply with data protection regulations.

How best in class fuzzy matching solutions work: Combining established and proprietary algorithms
Download

