




























Last Updated on enero 1, 2026
Datos estructurados sucios y desestructurados, más de una docena de variaciones de nombre y definiciones de campo incoherentes en fuentes dispares. Esta lata de gusanos es un riesgo ocupacional casi básico para cualquier analista de datos que trabaje en un proyecto con miles de registros. Y las implicaciones son cualquier cosa menos ordinarias:
- Las instituciones financieras mundiales fueron multadas con 5.600 millones de dólares en sanciones por incumplimiento de la normativa en 2020
- Un estudio de Black Book Market Research revela que un tercio de las reclamaciones de las organizaciones sanitarias se deniegan debido a una mala correspondencia de los pacientes.
- Losrepresentantes de ventas pierden el 25% de su tiempo debido a los malos datos de los prospectos.
Así que esta es la pregunta clave: ¿Existe una forma mejor de superar estos problemas?
A diferencia de las herramientas de resolución de entidades, que pueden realizar la ingesta de datos desde múltiples puntos y encontrar coincidencias no exactas a una velocidad inigualable, la resolución manual de datos de entidades mediante complejos algoritmos y técnicas resulta ser una tarea muy costosa (por no decir agotadora). Un estudio de Gartner ha revelado que la mala calidad de los datos cuesta a las empresas 15 millones de dólares al año, sobre todo a las que tienen operaciones que abarcan varios territorios y unidades de negocio.
Esta guía detallada le guiará a través de la resolución de entidades, cómo funciona, por qué la resolución manual de entidades es problemática para las empresas y por qué es óptimo optar por las herramientas de resolución de entidades.
¿Qué es la resolución de entidades?
El libro Entity Resolution and Information Quality describe la resolución de entidades (ER) como «la determinación de cuándo las referencias a entidades del mundo real son equivalentes (se refieren a la misma entidad) o no son equivalentes (se refieren a entidades diferentes)».
En otras palabras, es el proceso de identificar y vincular múltiples registros a la misma entidad cuando los registros se describen de forma diferente y viceversa.
Por ejemplo, plantea la siguiente pregunta: ¿las entradas de datos «Jon Snow» y «John Snowden» son la misma persona o son dos personas totalmente diferentes?
Esto también se aplica a las direcciones, los códigos postales y los números de la seguridad social, etc.
La ER se lleva a cabo mediante el examen de la similitud de varios registros, cotejándolos con identificadores únicos. Se trata de los registros que tienen menos probabilidades de cambiar con el tiempo (como los números de la seguridad social, la fecha de nacimiento, los códigos postales, etc.). Para averiguar si estos registros son iguales o no, hay que cotejarlos con un identificador único de la siguiente manera:
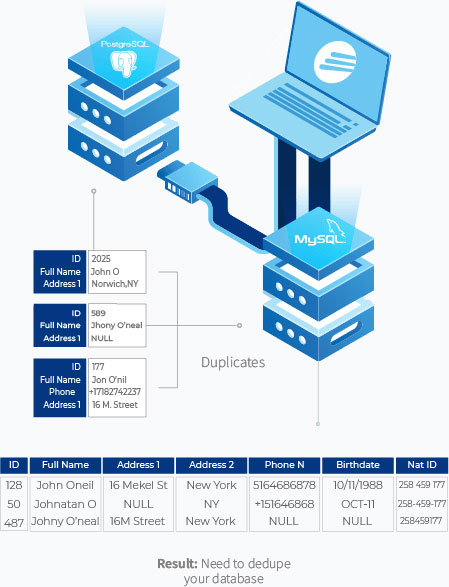
En el ejemplo anterior, John Oneil, Johnathan O y Johny O’neal coinciden a través de un identificador único que es el número de identificación nacional.
La ER suele consistir en vincular y cotejar los datos de varios registros para encontrar posibles duplicados y eliminar los duplicados cotejados, por lo que se utiliza indistintamente:
- Vinculación de registros
- Coincidencia difusa
- Fusión/purga
- Agrupación de entidades
- Deduplicación y más
Cómo funciona la resolución de entidades en la práctica
Hay varios pasos en una actividad de ER. Veamos esto con más detalle.
Ingestión
Se trata de poner todos los datos de múltiples fuentes bajo una vista centralizada. Una empresa suele tener datos dispersos en bases de datos dispares, CRM, Excel y PDF y formatos de datos que incluyen cadenas, fechas y ambos.
Por ejemplo, una gran empresa de servicios hipotecarios y financieros puede tener una base de datos central en MySQL, los datos de las hojas de reclamaciones en PDF y su lista de propietarios en Excel. La importación de datos de todas estas fuentes ayudará a preparar el terreno para vincular los registros y encontrar duplicados. Para más información, pulse aquí.
En otros casos, combinar diferentes fuentes en una sola puede significar también cambiar el esquema de las bases de datos en un esquema predefinido para su posterior procesamiento.
Perfilado
Una vez importadas las fuentes de datos, el siguiente paso es comprobar su estado para identificar cualquier tipo de anomalía estadística en forma de datos inexactos y faltantes, así como problemas de codificación (es decir, minúsculas y mayúsculas). Lo ideal es que un analista de datos intente encontrar las áreas potencialmente problemáticas que deben arreglarse antes de realizar cualquier tipo de limpieza y resolución de entidades.
Aquí un usuario puede querer comprobar si los campos se ajustan a RegEx – expresiones regulares que determinan los tipos de cadena para diferentes campos de datos. A partir de ahí, el usuario puede determinar cuántos registros están sucios o no se ajustan a una codificación determinada.
Hacerlo puede ayudar a revelar estadísticas de datos cruciales que incluyen, pero no se limitan a:
- Presencia de valores nulos, por ejemplo, falta de direcciones de correo electrónico en los formularios de captación de clientes potenciales
- Número de registros con espacios iniciales y finales, por ejemplo, David Matthews
- Problemas de puntuación, por ejemplo, hotmail,com en lugar de Hotmail.com
- Cuestiones de carcasa, por ejemplo, NUEVA YORK, DAVID mATTHEWS, MICROSOFT
- Presencia de letras en números y viceversa, por ejemplo, TEL-516 570-9251 para el número de contacto y NJ43 para el estado
Deduplicación y vinculación de registros
Mediante el cotejo, se unen varios registros potencialmente relacionados con la misma entidad para eliminar los duplicados, o se deduplican utilizando identificadores únicos. Las técnicas de concordancia pueden variar en función del tipo de campo, como el exacto, el difuso o el fonético.
En el caso de los nombres, por ejemplo, se suele utilizar la coincidencia exacta cuando los identificadores únicos, como el SSN o la dirección, son precisos en todo el conjunto de datos. Si los identificadores únicos son inexactos o inválidos, la concordancia difusa resulta ser una forma de concordancia mucho más fiable para emparejar fácilmente dos registros similares (por ejemplo, John Snow y Jon Snowden).
La deduplicación y la vinculación de registros, en la mayoría de los casos, se entienden como una misma cosa. Sin embargo, una diferencia clave es que la primera consiste en detectar los duplicados y consolidarlos dentro del mismo conjunto de datos (es decir, normalizar el esquema), mientras que la segunda consiste en cotejar los datos deduplicados en otros conjuntos o fuentes de datos.
Canonicalización
La canonización es otro paso clave en ER, donde las entidades que tienen múltiples representaciones se convierten en una forma estándar. Se trata de tomar la información más completa como registro final y dejar fuera los datos atípicos o ruidosos que puedan distorsionar los datos.
Bloqueo
Cuando se buscan coincidencias para una entidad en cientos y miles de registros, las combinaciones potenciales que podrían dar lugar a las coincidencias correctas pueden llegar a ser miles (si no millones). Para evitar este problema, se utiliza el bloqueo para limitar los posibles emparejamientos mediante reglas empresariales específicas.
Desafíos de la resolución de entidades
A pesar de los numerosos enfoques y técnicas disponibles para la ER, ésta se queda corta en varios frentes. Entre ellas se encuentran:
1. La ER sólo funciona bien si los datos son ricos y coherentes
Quizás el mayor problema de la ER es que la precisión de las coincidencias depende de la riqueza de los datos y de la coherencia entre los conjuntos de datos.
Por ejemplo, el emparejamiento determinista es bastante sencillo. Digamos que tiene «Mike Rogers» en la base de datos 1 y «Mike Rogers» en la base de datos 2. Mediante una simple vinculación de registros (o coincidencia exacta), podemos identificar fácilmente que uno es un duplicado de otro.
Sin embargo, el cotejo probabilístico, cuando existen registros de datos similares en forma de errores ortográficos, abreviaturas o apodos (por ejemplo, «Mike Rogers» en la base de datos 1 y «Michael Rogers» en la base de datos 2), es otra historia. Un identificador único (como la dirección, el SSN o la fecha de nacimiento) puede no ser consistente en todas las bases de datos y cualquier tipo de coincidencia exacta o determinista será casi imposible, especialmente cuando se trata de datos en grandes volúmenes.
2. Los algoritmos de ER no se adaptan bien
Los proyectos empresariales de Big Data que manejan terabytes de datos en el sector financiero, gubernamental o sanitario tienen demasiada información para que la ER tradicional, la vinculación de registros y la deduplicación funcionen correctamente. Las reglas de negocio necesarias para que los algoritmos funcionen tendrían que tener en cuenta datos mucho más amplios para funcionar de forma coherente.
Por ejemplo, la técnica de bloqueo -utilizada para limitar los pares no coincidentes al encontrar duplicados- depende de la calidad de los campos del registro. Si tiene campos que contienen errores, valores que faltan y variaciones, puede acabar insertando datos en los bloques equivocados y enfrentarse a un mayor número de falsos negativos.
3. Las urgencias manuales son complejas
No es infrecuente que las empresas o instituciones que manejan grandes volúmenes de datos opten por proyectos de ER internos. La razón es que pueden hacer uso de recursos técnicos (ingenieros de software, consultores, administradores de bases de datos) sin tener que comprar ninguna de las herramientas de resolución de entidades disponibles en el mercado.
Hay algunos problemas con esto. En primer lugar, la resolución de entidades no es un subconjunto del desarrollo de software. Claro, hay algoritmos y técnicas de bloqueo disponibles públicamente que podrían ser útiles. Pero en el gran esquema de las cosas, las habilidades requeridas son muy diferentes. El usuario deberá:
- Combinar fuentes de datos dispares, estructuradas y no estructuradas
- Conozca los diferentes tipos de codificación, los apodos y las variaciones para la precisión de las coincidencias
- Saber cómo resolver los registros de entidades para diferentes casos de uso
- Garantizar la complementariedad de las diferentes técnicas de emparejamiento para lograr la coherencia
Puede ser improbable que el usuario adecuado cumpla todas estas condiciones, e incluso si es posible, existe el riesgo de que abandone la empresa, lo que puede poner en peligro todo el proyecto.
4 razones por las que las herramientas de resolución de entidades son mejores
Las herramientas de resolución de entidades pueden ofrecer muchas ventajas que las ER tradicionales no pueden ofrecer. Entre ellas se encuentran:
1. Mayor precisión de los partidos
Las herramientas dedicadas a la resolución de entidades que cuentan con sofisticados algoritmos de correspondencia difusa y capacidades de resolución de entidades pueden ofrecer resultados de vinculación y deduplicación de registros mucho mejores que los algoritmos comunes de ER.
Cuando se trata de conjuntos de datos heterogéneos, encontrar la similitud de dos registros puede ser excepcionalmente difícil debido a los diferentes tipos de entidades, codificación, cuestiones de formato e idiomas. Los cambios de esquema también pueden suponer un problema. Las organizaciones sanitarias, por ejemplo, utilizan bases de datos tanto SQL como NoSQL, y convertir todos los datos en un esquema predefinido mediante el cotejo de esquemas y el intercambio de datos puede ser arriesgado, ya que se puede perder mucha información valiosa en el proceso.
Además, un analista de datos puede tener que utilizar varias métricas de cadenas para realizar una correspondencia difusa de forma eficaz, como la distancia Levenshtein, la distancia Jaro-Winkler, la distancia Damerau-Levenshtein y otras. Incorporar todo esto manualmente para mejorar la precisión de los partidos puede ser problemático.
Por otro lado, las herramientas de resolución de entidades pueden vincular sin problemas los registros empleando una amplia gama de métricas de cadena y otros algoritmos para ofrecer resultados de coincidencia más elevados.
2. Menor tiempo hasta el primer resultado
En la mayoría de los casos, el tiempo es crítico para los proyectos de ER, especialmente en el caso de las iniciativas de gestión de datos maestros (MDM) que requieren una única fuente de verdad. La información relativa a una entidad puede cambiar rápidamente en semanas o meses, lo que puede plantear graves riesgos para la calidad de los datos.
Supongamos que una organización de ventas y marketing B2B quiere realizar campañas en sus cuentas de primer nivel. Lo ideal es que se asegure de que sus clientes potenciales no han cambiado de trabajo, cambiado de cargo o se han jubilado antes de gastar en marketing. En estos casos, es fundamental hacer las urgencias dentro de un plazo.
La ER, si se hace manualmente, puede tardar hasta más de 6 meses, tiempo en el que muchos registros de las bases de datos pueden quedar obsoletos e inexactos. Sin embargo, las herramientas de resolución de entidades pueden tardar la mitad de tiempo y las más avanzadas pueden dar un resultado en 15 minutos.
3. Mejor escalabilidad
Las herramientas de resolución de entidades son mucho más hábiles a la hora de ingerir datos desde múltiples puntos y ejecutar tareas de vinculación, deduplicación y limpieza de registros a una escala mucho mayor. Las bases de datos gubernamentales, como las que contienen datos de recaudación de impuestos y censos, almacenan millones (si no billones) de registros. Una institución gubernamental que decida hacer ER para la prevención del fraude, por ejemplo, se vería limitada en el uso de enfoques manuales de ER y algoritmos. Un usuario se vería inundado por los datos con los que hay que trabajar y cualquier regla de negocio para las técnicas de bloqueo -para minimizar el número de comparaciones similares- sería inútil.
Sin embargo, las herramientas de resolución de entidades no sólo pueden importar datos de diversas fuentes, sino que también garantizan que su eficacia en materia de ER se mantenga intacta en grandes volúmenes de datos.
4. Ahorro de costes
Las herramientas de resolución de entidades, sobre todo para las aplicaciones de nivel empresarial, pueden suponer una inversión considerable. Los profesionales de los datos encargados de las urgencias pueden ser reacios a considerar la opción sólo por esta razón. Pueden razonar que hacerlo manualmente sería mucho más rentable y mejoraría sus posibilidades de promoción.
Aunque esto puede parecer razonable a primera vista, los costes de los retrasos en el proyecto, la escasa precisión de la concordancia y los recursos de mano de obra pueden acabar siendo mayores que los de una herramienta de ER.
Cómo elegir el software de resolución de entidades adecuado
La elección del software de resolución de entidades adecuado es igualmente importante. Muchas herramientas de resolución de entidades difieren en sus características, alcance y valor.
Importar fuentes de datos distintas
Las empresas pueden tener datos almacenados en una gran variedad de formatos y fuentes, como Excel, archivos delimitados, aplicaciones web, bases de datos y CRM. Un software de resolución de entidades debe ser capaz de importar datos de fuentes dispares para el caso de uso específico.
El módulo de importación de DataMatch Enterprise le permite obtener datos en varios formatos, como se muestra arriba.
Perfiles y limpieza de datos a escala
El software de resolución de entidades adecuado también debe ser capaz de perfilar y limpiar los datos antes de cualquier esfuerzo de deduplicación y vinculación de registros. DataMatch Enterprise, mediante patrones preconfigurados basados en expresiones Regex, puede determinar los registros válidos e inválidos, los nulos, los distintos, los espacios iniciales y finales, etc.
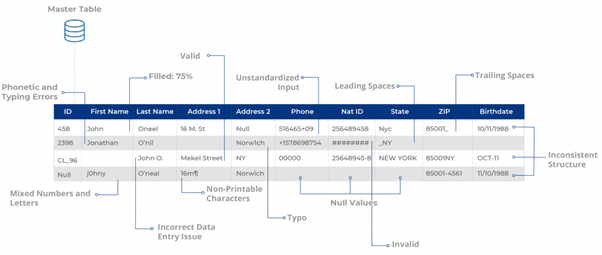
Una vez generado el perfil, los datos pueden ser limpiados utilizando varias funcionalidades como:
- Fusión de campos
- Personajes a eliminar
- Caracteres a sustituir
- Números para eliminar y más

Capacidades sólidas de emparejamiento
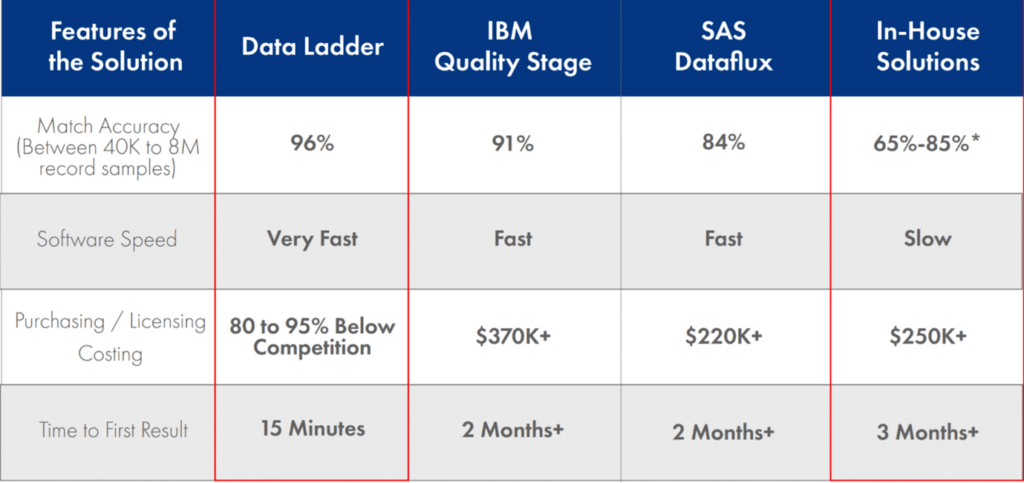
Hay muchas herramientas de resolución de entidades que dicen proporcionar una alta puntuación de coincidencia. Sin embargo, la precisión de las comparaciones está vinculada a la sofisticación de los algoritmos utilizados para cotejar los registros dentro y a través de múltiples conjuntos de datos. DataMatch Enterprise emplea una serie de tipos de coincidencias (exactas, difusas, fonéticas, métricas de cadena) para establecer la distancia entre entidades y hace uso de bibliotecas específicas de dominio (apodos, direcciones, números de teléfono) para establecer una puntuación de coincidencia superior a la del sector.
Un estudio independiente realizado por la Universidad de Curtin descubrió que la precisión de las coincidencias de DataMatch superaba a la de otros proveedores, como Quality Stage de IBM y SAS Dataflux.
Nota final
Por muy crucial que sea para las empresas hacer ER, llevar a cabo manualmente la deduplicación, la vinculación de registros y otras tareas de ER tiene serios límites cuando se trata de cotejar datos en millones y billones de registros. Utilizando un software de resolución de entidades como DataMatch Enterprise, las empresas están en una posición mucho mejor para alcanzar sus objetivos empresariales desde el punto de vista de la escalabilidad, el coste y los resultados.
Para obtener más información sobre DataMatch Enterprise, haga clic en la página de la solución Entity Resolution o póngase en contacto con nuestro equipo de ventas.

Cómo funcionan las mejores soluciones de concordancia difusa de su clase: Combinando algoritmos establecidos y propios
Inicie su prueba gratuita hoy mismo



