





























Last Updated on Mai 19, 2022
Laut dem Bericht von O’Reilly über Der Stand der Datenqualität 2020 sehen sich 56 % der Unternehmen mit mindestens vier verschiedenen Arten von Datenqualitätsproblemen konfrontiert, 71 % sogar mit mindestens drei verschiedenen Arten. Es ist nicht verwunderlich, dass die Anzahl und Art der Datenqualitätsprobleme in den verschiedenen Organisationen unterschiedlich sind. Es ist jedoch überraschend, dass die meisten Unternehmen dazu neigen, allgemeine Lösungen für ihre Datenqualitätsprobleme zu übernehmen und zu implementieren, anstatt etwas zu entwickeln, das ihrem speziellen Fall gerecht wird.
Hier kommt ein durchgängiger Rahmen für die Datenqualität ins Spiel. In einem früheren Blog haben wir die wichtigsten Datenqualitätsprozesse besprochen, die man kennen sollte, bevor man ein Datenqualitäts-Framework entwickelt. In diesem Blog werden wir sehen, wie diese Prozesse genutzt werden können, um einen Plan zur kontinuierlichen Verbesserung der Datenqualität zu entwickeln.
Lassen Sie uns eintauchen.
Was ist ein Datenqualitätsrahmen?
Der Datenqualitätsrahmen (auch Datenqualitätslebenszyklus genannt) ist ein systematischer Prozess, der den aktuellen Stand der Datenqualität überwacht und sicherstellt, dass diese über den festgelegten Schwellenwerten bleibt. Sie ist in der Regel zyklisch angelegt, so dass die Ergebnisse kontinuierlich bewertet und Fehler rechtzeitig und systematisch korrigiert werden.
Beispiel für einen Datenqualitätsrahmen
Unternehmen, die ihre Datenqualitätsprobleme beheben wollen, wenden fast die gleichen Datenqualitätsprozesse an. Bei der Datenqualität unterscheiden sich ihre Pläne jedoch. So wird ein Datenqualitätsmanagementsystem mit Sicherheit einige grundlegende Datenstandardisierungstechniken verwenden, um eine einheitliche Sicht auf alle Datenwerte zu erhalten. Die genaue Art dieser Standardisierungstechniken hängt jedoch vom aktuellen Stand Ihrer Daten ab und davon, was Sie erreichen wollen.
Aus diesem Grund werden wir hier ein allgemeines, aber dennoch umfassendes Datenqualitäts-Framework betrachten – etwas, das jedes Unternehmen für seinen speziellen Geschäftsfall übernehmen kann.
Ein einfacher Rahmen oder Lebenszyklus für die Datenqualität besteht aus vier Phasen:
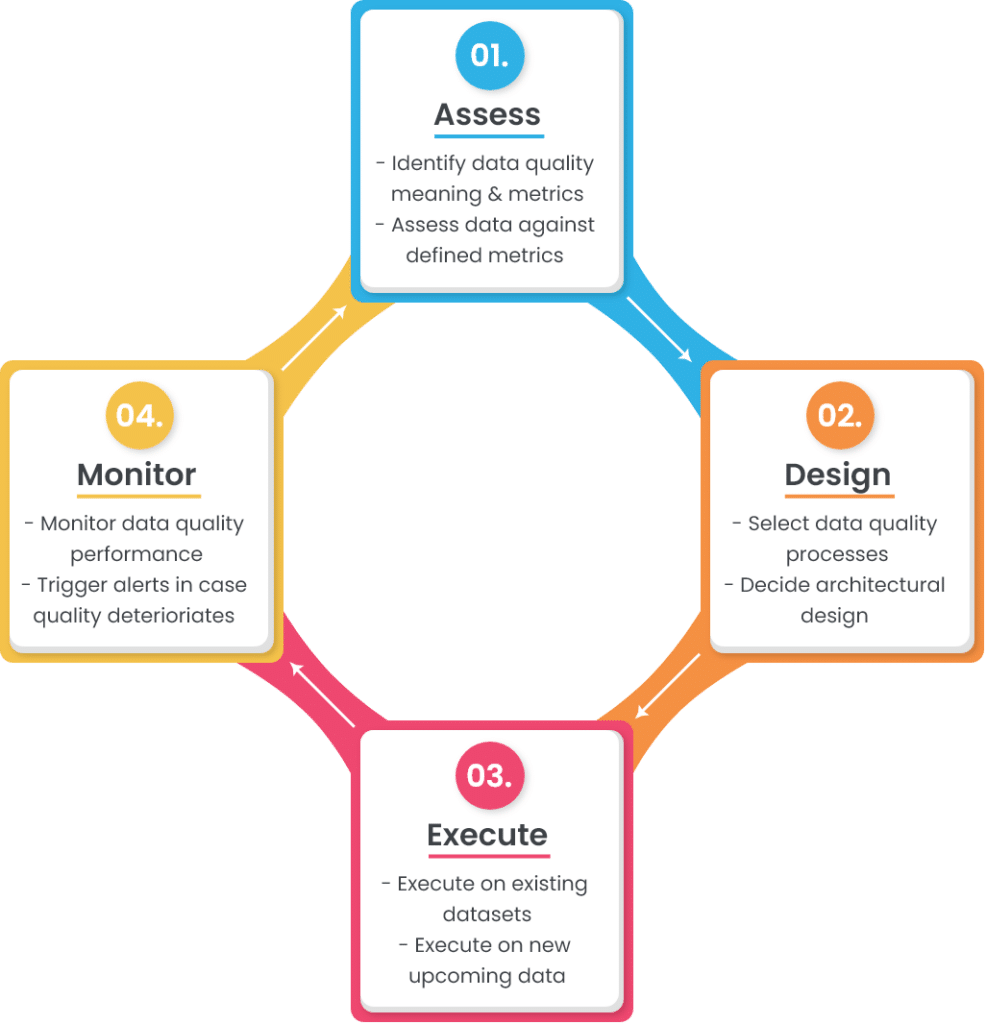
In den folgenden Abschnitten wird auf jede dieser Phasen näher eingegangen.
1. Bewerten Sie
Dies ist der erste Schritt des Rahmens, in dem Sie die beiden Hauptkomponenten bewerten müssen: die Bedeutung der Datenqualität für Ihr Unternehmen und die Bewertung der aktuellen Daten im Vergleich dazu.
a. die Bedeutung und die Messgrößen der Datenqualität zu ermitteln
Die Datenqualität ist definiert als der Grad, in dem die Daten den beabsichtigten Zweck erfüllen. Und um zu definieren, was Datenqualität für Ihr Unternehmen bedeutet, müssen Sie wissen, welche Rolle sie bei den verschiedenen Vorgängen spielt.
Nehmen wir als Beispiel einen Kundendatensatz. Ihre Kundendaten müssen ein akzeptables Qualitätsniveau aufweisen – unabhängig davon, ob sie für die Kontaktaufnahme mit Kunden oder für die Analyse von Geschäftsentscheidungen verwendet werden. Um die Bedeutung von qualitativ hochwertigen Kundendaten zu definieren, müssen Sie Folgendes tun:
- Identifizieren Sie die Quellen , aus denen Kundendaten stammen (Webformulare, Drittanbieter, Kunden usw.),
- Wählen Sie die erforderlichen Attribute aus, die die Kundeninformationen vervollständigen (Name, Telefonnummer, E-Mail-Adresse, geografische Adresse usw.),
- Definition von Metadaten zu ausgewählten Attributen (Datentyp, Größe, Format, Muster usw.)
- Erläutern Sie die Akzeptanzkriterien für die gespeicherten Daten (der Name des Kunden muss immer zu 100 % richtig sein, während die Produktpräferenzen bis zu 95 % richtig sein können).
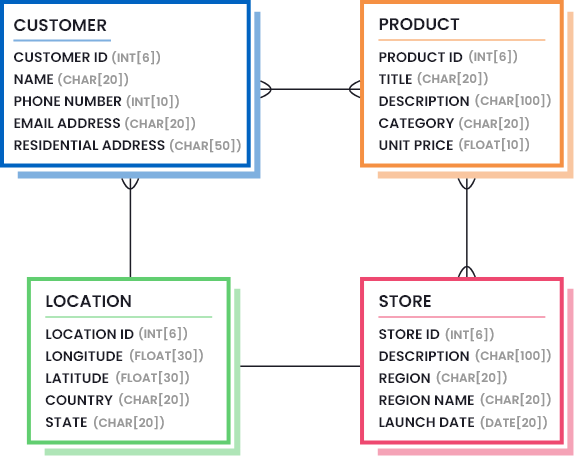
Diese Informationen werden in der Regel durch die Erstellung von Datenmodellen definiert, die die notwendigen Datenbestandteile (Menge und Qualität der Daten, die als ausreichend angesehen werden) hervorheben. Die folgende Abbildung zeigt, wie ein Datenmodell für ein Einzelhandelsunternehmen aussehen kann:
Außerdem müssen Sie die Datenqualitätsmetriken und ihre akzeptablen Schwellenwerte ermitteln. Nachfolgend finden Sie eine Liste der gebräuchlichsten Datenqualitätsmetriken, aber Sie müssen diejenigen auswählen, die in Ihrem Fall hilfreich sind, und die niedrigsten Perzentilwerte herausfinden, die eine gute Datenqualität darstellen.
- Genauigkeit: Wie gut bilden die Datenwerte die Realität/Korrektheit ab?
- Herkunft: Wie vertrauenswürdig ist die ursprüngliche Quelle der Datenwerte?
- Semantisch: Entsprechen die Datenwerte ihrer Bedeutung?
- Struktur: Sind die Datenwerte im richtigen Muster und/oder Format vorhanden?
- Vollständigkeit: Sind Ihre Daten so umfassend, wie Sie sie benötigen?
- Konsistenz: Haben die verschiedenen Datenspeicher die gleichen Datenwerte für die gleichen Datensätze?
- Währung: Sind Ihre Daten akzeptabel auf dem neuesten Stand?
- Rechtzeitigkeit: Wie schnell werden die angeforderten Daten zur Verfügung gestellt?
- Angemessenheit: Haben die Datenwerte den richtigen Datentyp und die richtige Größe?
- Identifizierbarkeit: Stellt jeder Datensatz eine eindeutige Identität dar und ist kein Duplikat?
b. Bewertung aktueller Datensätze anhand definierter Metriken
Der erste Schritt der Bewertung hilft Ihnen, die Ziele zu definieren. Der nächste Schritt bei der Bewertung besteht darin, zu messen, wie gut Ihre aktuellen Daten im Vergleich zu den festgelegten Zielen abschneiden. Dieser Schritt wird in der Regel durch die Erstellung detaillierter Datenprofilberichte durchgeführt. Data Profiling ist ein Prozess, der die Struktur und den Inhalt Ihrer Datensätze analysiert und versteckte Details aufdeckt.
Sobald die Datenprofilberichte erstellt sind, können Sie sie mit dem festgelegten Ziel vergleichen. Wenn der generierte Datenprofilbericht 85 % Vollständigkeit beim Kundennamen anzeigt, müssen Sie die restlichen 15 % der fehlenden Informationen abrufen.
2. Entwurf
Der nächste Schritt des Datenqualitätsrahmens besteht darin, die Geschäftsregeln zu entwerfen, die die Konformität mit dem Datenmodell und den in der Bewertungsphase definierten Zielen sicherstellen sollen. Die Entwurfsphase besteht aus zwei Hauptkomponenten:
- Auswahl der benötigten Datenqualitätsprozesse und deren Feinabstimmung auf Ihre Bedürfnisse,
- Entscheidung darüber, wo Datenqualitätsfunktionen eingebettet werden sollen (Architekturentwurf).
Schauen wir uns diese im Detail an.
a. Datenqualitätsprozesse auswählen
Je nach dem Zustand Ihrer Daten müssen Sie eine Liste von Datenqualitätsprozessen auswählen, die Ihnen helfen, den gewünschten Qualitätszustand zu erreichen. Normalerweise wird eine Reihe von Datenqualitätsprozessen durchgeführt, um Fehler zu beheben oder Daten in die gewünschte Form und Struktur zu bringen.
Im Folgenden sind die gängigsten Datenqualitätsprozesse aufgeführt, die von Unternehmen verwendet werden. Die Reihenfolge, in der sie bei anstehenden oder bereits vorhandenen Daten implementiert werden sollen, bleibt Ihnen überlassen. Anhand der Beispiele, die für jedes Verfahren angeführt sind, können Sie feststellen, ob dieses Verfahren für Ihren Fall nützlich ist oder ob es übersprungen werden kann.
i. Parsing und Zusammenführung von Daten
Beim Parsen von Daten werden lange Zeichenketten analysiert und die Teilkomponenten in eine oder mehrere Spalten aufgeteilt. Dies geschieht in der Regel, um wichtige Elemente in separaten Spalten unterzubringen, so dass sie sich leichter finden lassen:
- Validiert anhand einer Bibliothek mit genauen Werten,
- in akzeptable Formate umgewandelt, oder
- Abgleich mit anderen Datensätzen, um mögliche Duplikate zu finden.
In ähnlicher Weise werden Teilkomponenten zusammengeführt, um die Bedeutung der einzelnen Felder zu erhöhen.
Beispiel: Zerlegung der Adressspalte in Straßennummer, Straßenname, Stadt, Bundesland, Postleitzahl, Land usw.
ii. Datenbereinigung und -standardisierung
Datenbereinigung und -standardisierung ist der Prozess der Beseitigung falscher und ungültiger Informationen in einem Datensatz, um eine konsistente und nutzbare Ansicht über alle Datenquellen hinweg zu erhalten.
Beispiel:
- Entfernen von Nullwerten, führenden/nachlaufenden Leerzeichen, Sonderzeichen usw.,
- Ersetzen von Abkürzungen durch Vollformen oder von sich wiederholenden Wörtern durch standardisierte Wörter,
- Umwandlung von Großbuchstaben (Kleinbuchstaben in Großbuchstaben, Großbuchstaben in Kleinbuchstaben),
- Standardisierung von Werten, damit sie dem richtigen Muster und Format folgen usw.
iii. Datenabgleich und Deduplizierung
Datenabgleich (auch bekannt als Datensatzverknüpfung und Entitätsauflösung) ist der Prozess des Vergleichs von zwei oder mehr Datensätzen und der Feststellung, ob sie zur selben Entität gehören. Wenn mehrere Datensätze übereinstimmen, wird der Hauptdatensatz beibehalten und die Duplikate werden entfernt, um den goldenen Datensatz zu erhalten.
Beispiel: Wenn Kundeninformationen in Ihrem Unternehmen in verschiedenen Quellen erfasst und gepflegt werden (CRM, Buchhaltungssoftware, E-Mail-Marketing-Tool, Website-Aktivitäts-Tracker usw.), werden Sie bald mehrere Datensätze desselben Kunden haben. In solchen Fällen müssen Sie einen exakten oder unscharfen Abgleich durchführen, um festzustellen, welche Datensätze zu demselben Kunden gehören und welche möglicherweise Duplikate sind.
iv. Datenzusammenführung und Überlebensfähigkeit
Wenn Sie doppelte Datensätze in Ihrem Datensatz gefunden haben, können Sie die Duplikate einfach löschen oder zusammenführen, um ein Maximum an Informationen zu erhalten und Datenverluste zu vermeiden. Datenzusammenführung und Überlebensfähigkeit ist ein Datenqualitätsprozess, der Ihnen hilft, Regeln zu erstellen, die doppelte Datensätze durch bedingte Auswahl und Überschreiben zusammenführen.
Beispiel: Sie möchten vielleicht den Datensatz mit dem längsten Kundennamen behalten und als Stammsatz verwenden, während Sie die längste Postleitzahl aus dem doppelten Datensatz in den Stammsatz überschreiben. Eine nach Prioritäten geordnete Liste solcher Regeln wird Ihnen helfen, das Beste aus Ihrem Datensatz herauszuholen.
v. Benutzerdefinierte Validierungs- oder Abhängigkeitsregeln
Abgesehen von den standardisierten Datenqualitätsprozessen haben Sie möglicherweise benutzerdefinierte Validierungsregeln, die für Ihren Geschäftsbetrieb einzigartig sind.
Beispiel: Wenn ein Kunde ein Produkt A gekauft hat, kann er nur einen Rabatt von bis zu 20 % in Anspruch nehmen. (Das bedeutet: Wenn Kauf = Produkt A, dann sollte derRabatt <= 20% sein).
Solche geschäftsspezifischen Abhängigkeitsregeln müssen validiert werden, um eine hohe Datenqualität zu gewährleisten.
b. Entscheiden Sie über die architektonische Gestaltung
Nachdem wir nun einen Blick auf einige gängige Datenqualitätsprozesse geworfen haben, die in einem Datenqualitätsrahmenwerk verwendet werden, ist es an der Zeit, einen weiteren wichtigen Aspekt zu betrachten: Wie sind diese Datenqualitätsvorgänge in Ihren Datenlebenszyklus eingebettet?
Es gibt mehrere Möglichkeiten, dies zu erreichen, unter anderem:
1. Implementierung von Datenqualitätsfunktionen bei der Eingabe – dies kann die Einrichtung von Validierungsprüfungen in Webformularen oder Anwendungsschnittstellen zur Speicherung von Daten beinhalten.
2. Einführung von Middleware , die eingehende Daten validiert und umwandelt, bevor sie in der Zielquelle gespeichert werden.

3. Durchführung von Validierungsprüfungen in der Datenbank, so dass bei der Speicherung von Daten im Datenspeicher Fehler ausgelöst werden.
Obwohl der erste Weg der beste zu sein scheint, hat er seine Grenzen. Da ein durchschnittliches Unternehmen mehr als 40 Anwendungen einsetzt, ist es schwierig, jede einzelne Eingabequelle so zu synchronisieren, dass sie den gewünschten Output liefert.
Weitere Informationen finden Sie unter: Wie werden Datenqualitätsfunktionen in Software-Tools verpackt?
3. Führen Sie aus.
Die dritte Phase des Zyklus ist die Phase der Ausführung. In den beiden vorangegangenen Schritten haben Sie die Bühne vorbereitet, nun ist es an der Zeit zu sehen, wie gut das System tatsächlich funktioniert.
Es ist wichtig zu beachten, dass Sie die konfigurierten Prozesse möglicherweise zunächst an den vorhandenen Daten ausführen und deren hohe Qualität sicherstellen müssen. In der nächsten Phase können Sie die Ausführung für neue Datenströme auslösen.
4. Überwachen Sie
Dies ist die letzte Phase des Rahmens, in der die Ergebnisse überwacht werden. Sie können dieselben Techniken zur Erstellung von Datenprofilen verwenden, die auch in der Bewertungsphase verwendet wurden, um detaillierte Leistungsberichte zu erstellen. Ziel ist es, festzustellen, inwieweit die Daten beispielsweise mit den festgelegten Zielen übereinstimmen:
- Eingehende Daten werden nach Bedarf geparst und zusammengeführt,
- Die erforderlichen Attribute sind nicht null,
- Gekürzte Wörter werden nach Bedarf umgewandelt,
- Die Daten werden nach dem vorgegebenen Format und Muster standardisiert,
- Mögliche Duplikate werden zusammengeführt oder dedupliziert,
- Mögliche Duplikate werden nicht als neue Datensätze angelegt,
- Die benutzerdefinierten Geschäftsregeln werden nicht verletzt, usw.
Darüber hinaus können Sie auch Schwellenwerte für die Messung der Datenqualität festlegen und Warnmeldungen auslösen, wenn die Datenqualität auch nur ein wenig unter diesen Werten liegt.
Und da sind wir wieder…
Ein Datenqualitätszyklus oder -rahmen ist ein iterativer Prozess. Sobald Sie die Überwachungsphase erreicht haben, können einige Datenqualitätsfehler auftreten. Dies zeigt, dass der festgelegte Rahmen noch einige Lücken aufweist, die zu Fehlern führen. Aus diesem Grund muss die Bewertungsphase erneut eingeleitet werden, was wiederum die Entwurfs- und Ausführungsphase auslöst. Auf diese Weise wird Ihr Datenqualitätsrahmen ständig verbessert und perfektioniert, um Ihre Anforderungen an die Datenqualität zu erfüllen.
Wann wird der Zyklus iteriert?
Es gibt zwei Möglichkeiten, die Bewertungsphase auszulösen:
1. Proaktiver Ansatz
Bei diesem Ansatz können Sie ein regelmäßiges Datum und eine Uhrzeit auswählen, zu der die erstellten Leistungsberichte analysiert werden. Sollten innerhalb dieses Zeitrahmens Fehler auftreten, wird die Bewertungsphase erneut ausgelöst. Diese Vorgehensweise hilft Ihnen, mögliche Fehler im Auge zu behalten, die auftreten können.
2. Reaktiver Ansatz
Wie der Name schon sagt, wird die Bewertungsphase ausgelöst, wenn ein Datenqualitätsfehler auftritt. Obwohl beide Ansätze ihre eigenen Vorteile haben, ist es am besten, beide in Ihrem Datenqualitätsrahmen anzuwenden, damit der Zustand der Datenqualität ständig proaktiv überwacht und bei Auftreten von Fehlern behoben wird.
Schlussfolgerung
Datenqualität ist keine Einbahnstraße. Es ist etwas, das ständig bewertet und verbessert werden muss. Aus diesem Grund ist es von entscheidender Bedeutung, umfassende Rahmenwerke zu entwickeln, die die Qualität mehrerer Datensätze kontinuierlich verwalten. Die Verwendung von eigenständigen Datenqualitäts-Tools kann in diesem Fall sehr produktiv sein, da sie die Fähigkeit haben,:
- Integrieren Sie in der Mitte Ihrer Eingangs- und Ausgangsquellen,
- Durchführung detaillierter Analysen zur Erstellung von Datenprofilberichten,
- Unterstützung verschiedener Datenqualitätsprozesse, die je nach Bedarf abgestimmt und angepasst werden können,
- Bieten Sie Stapelverarbeitungs- oder Echtzeitverarbeitungsdienste an, usw.
DataMatch Enterprise ist eine solche Lösung, die sowohl als eigenständige Anwendung als auch als integrierbare API verfügbar ist und ein durchgängiges Datenqualitätsmanagement ermöglicht, einschließlich Datenprofilierung, -bereinigung, -abgleich, -deduplizierung und -bereinigung.
Sie können die kostenlose Testversion noch heute herunterladen oder eine persönliche Sitzung mit unseren Experten vereinbaren, um zu erfahren, wie wir Sie bei der Entwicklung eines Datenqualitätsrahmens für Ihr Unternehmen unterstützen können.



