





























Last Updated on mai 19, 2022
D’après le rapport de O’Reilly sur L’état de la qualité des données en 2020 , 56 % des organisations sont confrontées à au moins quatre types différents de problèmes de qualité des données, tandis que 71 % en rencontrent au moins trois. Il n’est pas surprenant que le nombre et le type de problèmes de qualité des données rencontrés varient selon les organisations. Mais il est surprenant que la plupart des entreprises aient tendance à adopter et à mettre en œuvre des solutions générales pour résoudre leurs problèmes de qualité des données, au lieu de concevoir quelque chose qui réponde à leur cas particulier.
C’est là qu’intervient un cadre de qualité des données de bout en bout. Dans un blog précédent, nous avons abordé les principaux processus de qualité des données à connaître avant de concevoir un cadre de qualité des données. Dans ce blog, nous allons voir comment ces processus peuvent être utilisés pour concevoir un plan d’amélioration continue de la qualité des données.
Plongeons dans le vif du sujet.
Qu’est-ce qu’un cadre de qualité des données ?
Le cadre de qualité des données (également connu sous le nom de cycle de vie de la qualité des données) est un processus systématique qui surveille l’état actuel de la qualité des données et garantit son maintien au-dessus de seuils définis. Elle est généralement conçue selon un cycle, de sorte que les résultats sont évalués en permanence et que les erreurs sont systématiquement corrigées à temps.
Exemple de cadre de qualité des données
Les entreprises qui cherchent à résoudre leurs problèmes de qualité des données adoptent pratiquement les mêmes processus de qualité des données. Mais c’est au niveau du cadre de qualité des données que leurs plans diffèrent. Par exemple, un système de gestion de la qualité des données utilisera certainement certaines techniques de base de normalisation des données pour obtenir une vue cohérente de toutes les valeurs de données. Mais la nature exacte de ces techniques de normalisation dépend de l’état actuel de vos données et de ce que vous souhaitez obtenir.
C’est pourquoi nous allons examiner ici un cadre de qualité des données générique mais complet, que toute organisation peut adopter en fonction de ses besoins spécifiques.
Un cadre ou un cycle de vie simple de la qualité des données se compose de quatre étapes :
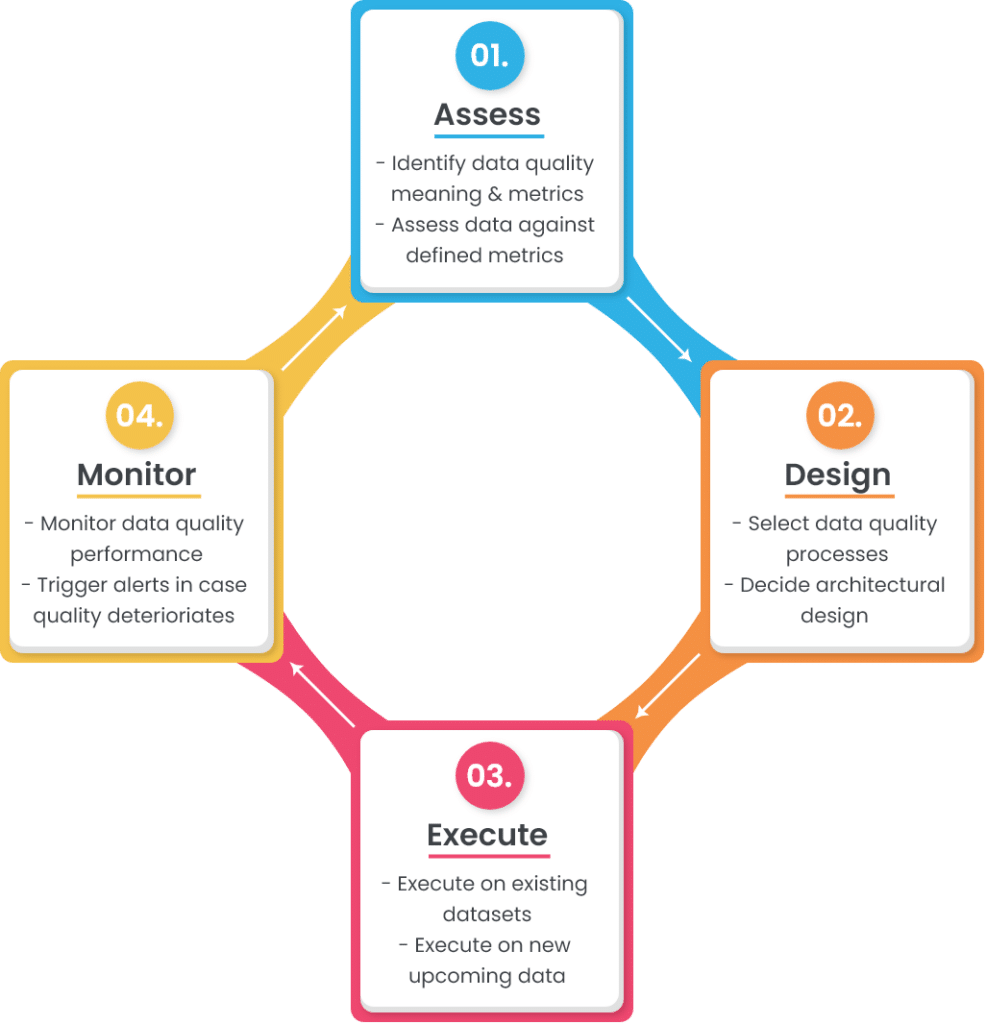
Les sections suivantes abordent chacune de ces étapes de manière plus détaillée.
1. Évaluez
Il s’agit de la première étape du cadre dans lequel vous devez évaluer les deux principaux éléments : la signification de la qualité des données pour votre entreprise et la manière dont les données actuelles s’y comparent.
a. Identifier la signification et les paramètres de la qualité des données
La qualité des données est définie comme le degré auquel les données remplissent l’objectif prévu. Et pour définir ce que signifie la qualité des données pour votre entreprise, vous devez connaître le rôle qu’elle joue dans différentes opérations.
Prenons l’exemple d’un ensemble de données sur les clients. Un niveau de qualité acceptable est requis pour vos ensembles de données clients – qu’ils soient utilisés pour contacter les clients ou analysés pour la prise de décisions commerciales. Pour définir la signification des données clients de bonne qualité, vous devez procéder comme suit :
- Identifiez les sources d’où proviennent les données clients (formulaires web, fournisseurs tiers, clients, etc.),
- Sélectionnez les attributs nécessaires qui complètent les informations sur le client (nom, numéro de téléphone, adresse électronique, adresse géographique, etc,)
- Définir les métadonnées des attributs sélectionnés (type de données, taille, format, motif, etc.)
- Expliquez les critères d’acceptabilité des données stockées (le nom du client doit être exact à 100% à tout moment, tandis que ses préférences en matière de produits peuvent être exactes à 95%).
Ces informations sont généralement définies en dessinant des modèles de données qui mettent en évidence les parties nécessaires des données (la quantité et la qualité des données qui sont considérées comme suffisantes). Considérez l’image suivante pour comprendre à quoi peut ressembler un modèle de données pour une entreprise de vente au détail :
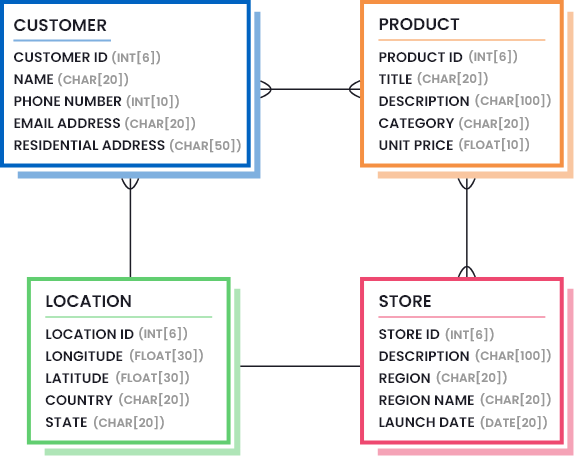
En outre, vous devez identifier les paramètres de qualité des données et leurs seuils acceptables. Une liste des mesures de qualité des données les plus courantes est donnée ci-dessous, mais vous devez sélectionner celles qui sont utiles dans votre cas, et déterminer les valeurs de percentile les plus faibles qui représentent une bonne qualité de données.
- Exactitude: Dans quelle mesure les valeurs des données représentent-elles la réalité/la justesse ?
- Lignage: Dans quelle mesure la source d’origine des valeurs des données est-elle digne de confiance ?
- Sémantique: Les valeurs des données sont-elles fidèles à leur signification ?
- Structure: Les valeurs des données existent-elles dans le bon modèle et/ou format ?
- Exhaustivité: Vos données sont-elles aussi complètes que vous le souhaitez ?
- Cohérence: Les magasins de données disparates ont-ils les mêmes valeurs de données pour les mêmes enregistrements ?
- La monnaie: Vos données sont-elles raisonnablement à jour ?
- Rapidité: Dans quel délai les données demandées sont-elles mises à disposition ?
- Caractère raisonnable: Les valeurs des données ont-elles le bon type et la bonne taille ?
- Identifiabilité: Chaque enregistrement représente-t-il une identité unique et n’est pas un doublon ?
b. Évaluer les ensembles de données actuels par rapport à des paramètres définis
La première étape de l’évaluation vous aide à définir les objectifs. L’étape suivante de l’évaluation consiste à mesurer la performance de vos données actuelles par rapport aux objectifs fixés. Cette étape est généralement réalisée en générant des rapports détaillés sur le profil des données. Le profilage des données est un processus qui permet d’analyser la structure et le contenu de vos ensembles de données et de découvrir des détails cachés.
Une fois les rapports sur le profil des données générés, vous pouvez maintenant les comparer à l’objectif fixé. Par exemple, un objectif fixé pourrait être que les clients doivent avoir un prénom et un nom de famille ; si le rapport de profil de données généré montre une complétude de 85% sur le nom du client, vous devez aller chercher les 15% restants des informations manquantes.
2. Conception
L’étape suivante du cadre de qualité des données consiste à concevoir les règles métier qui garantiront la conformité avec le modèle de données et les objectifs définis lors de l’étape d’évaluation. La phase de conception comprend deux éléments principaux :
- Sélectionner les processus de qualité des données dont vous avez besoin et les affiner en fonction de vos besoins,
- Décider où intégrer les fonctions de qualité des données (conception architecturale).
Examinons-les plus en détail.
a. Sélectionner les processus de qualité des données
En fonction de l’état de vos données, vous devez sélectionner une liste de processus de qualité des données qui vous aideront à atteindre l’état de qualité souhaité. Habituellement, un certain nombre de processus de qualité des données sont exécutés pour corriger les erreurs ou transformer les données dans la forme et la structure requises.
Nous avons répertorié ci-dessous les processus de qualité des données les plus courants utilisés par les organisations. L’ordre dans lequel ils doivent être mis en œuvre sur les données à venir ou existantes est votre choix. Les exemples fournis pour chaque processus vous aideront à déterminer si ce processus est utile pour votre cas ou s’il peut être ignoré.
i. Analyse et fusion des données
L’analyse syntaxique des données consiste à analyser de longues chaînes de caractères et à diviser les sous-composants en une ou plusieurs colonnes. Ceci est généralement fait pour obtenir des éléments importants dans des colonnes séparées afin qu’ils puissent être.. :
- Validé par rapport à une bibliothèque de valeurs précises,
- transformés dans des formats acceptables, ou
- Mise en correspondance avec d’autres dossiers pour trouver d’éventuels doublons.
De même, les sous-composants sont fusionnés afin d’obtenir plus de sens à partir des champs individuels.
Exemple : Analyse de la colonne d’adresse en numéro de rue, nom de rue, ville, État, code postal, pays, etc.
ii. Nettoyage et normalisation des données
Lenettoyage et la normalisation desdonnées sont le processus d’élimination des informations incorrectes et invalides présentes dans un ensemble de données afin d’obtenir une vue cohérente et utilisable de toutes les sources de données.
Exemple:
- Suppression des valeurs nulles, des espaces avant/arrière, des caractères spéciaux, etc,
- Remplacer les abréviations par des formes complètes, ou les mots répétitifs par des mots standardisés,
- Transformation de la casse des lettres (de bas en haut, de haut en bas),
- Normalisation des valeurs afin qu’elles suivent le bon modèle et le bon format, etc.
iii. Correspondance et déduplication des données
Lerapprochement des données (également connu sous le nom de couplage d’enregistrements et de résolution d’entités) est le processus consistant à comparer deux ou plusieurs enregistrements et à déterminer s’ils appartiennent à la même entité. Si plusieurs enregistrements correspondent, l’enregistrement principal est conservé et les doublons sont supprimés pour obtenir l’enregistrement d’or.
Exemple : Si les informations relatives aux clients de votre entreprise sont saisies et conservées à partir de différentes sources (CRM, logiciel de comptabilité, outil de marketing par courriel, outil de suivi de l’activité du site Web, etc.), vous vous retrouverez rapidement avec plusieurs enregistrements du même client. Dans ce cas, vous devrez effectuer une correspondance exacte ou floue pour déterminer les enregistrements appartenant au même client, et ceux qui sont des doublons possibles.
iv. Fusion des données et survie
Lorsque vous trouvez des enregistrements en double dans votre ensemble de données, vous pouvez simplement supprimer les doublons ou les fusionner pour conserver un maximum d’informations et éviter toute perte de données. Lafusion et la survie des données est un processus de qualité des données qui vous aide à élaborer des règles permettant de fusionner les enregistrements en double par le biais d’une sélection conditionnelle et d’un écrasement.
Exemple : Vous pouvez conserver l’enregistrement qui contient le nom de client le plus long et l’utiliser comme enregistrement principal, tout en écrasant le code postal le plus long de l’enregistrement en double sur l’enregistrement principal. Une liste hiérarchisée de ces règles vous aidera à tirer le meilleur parti de votre ensemble de données.
v. Règles de validation ou de dépendance personnalisées
Outre les processus normalisés de qualité des données, vous pouvez avoir des règles de validation personnalisées qui sont propres à vos activités commerciales.
Exemple : Si un client a acheté le produit A, il ne peut bénéficier que d’une remise de 20% maximum. (Signification : Si l’achat = le produit A, alors laremisedevrait être <= 20%).
Ces règles de dépendance spécifiques à l’entreprise doivent être validées pour garantir une qualité élevée des données.
b. Décider de la conception architecturale
Maintenant que nous avons examiné certains processus de qualité des données courants utilisés dans un cadre de qualité des données, il est temps de considérer un aspect plus important : comment ces opérations de qualité des données sont-elles intégrées dans votre cycle de vie des données ?
Il y a plusieurs façons de le faire, notamment :
1. Mettre en œuvre des fonctions de qualité des données à l’entrée – il peut s’agir de mettre en place des contrôles de validation sur les formulaires Web ou les interfaces d’application utilisés pour stocker les données.
2. Introduire un intergiciel qui valide et transforme les données entrantes avant de les stocker dans la source de destination.

3. Mettre en place des contrôles de validation sur la base de données, de sorte que les erreurs soient soulevées lors du stockage des données dans le magasin de données.
Bien que la première méthode semble la meilleure, elle a ses propres limites. Comme une organisation moyenne utilise plus de 40 applications, il est difficile de synchroniser chaque source d’entrée pour produire la sortie requise.
Pour en savoir plus, consultez le site : Comment les fonctionnalités de qualité des données sont-elles intégrées dans les outils logiciels ?
3. Exécuter
La troisième étape du cycle est celle de l’exécution. Vous avez préparé la scène dans les deux étapes précédentes, il est maintenant temps de voir comment le système fonctionne réellement.
Il est important de noter que vous devrez peut-être d’abord exécuter les processus configurés sur les données existantes et garantir leur qualité. Dans la phase suivante, vous pouvez déclencher l’exécution sur les nouveaux flux de données à venir.
4. Surveiller
Il s’agit de la dernière étape du cadre où les résultats sont contrôlés. Vous pouvez utiliser les mêmes techniques de profilage des données que celles utilisées lors de l’étape d’évaluation pour générer des rapports de performance détaillés. L’objectif est de voir dans quelle mesure les données sont conformes aux objectifs fixés, par exemple :
- Les données entrantes sont analysées et fusionnées si nécessaire,
- Les attributs requis ne sont pas nuls,
- Les mots abrégés sont transformés selon les besoins,
- Les données sont normalisées selon le format et le modèle définis,
- Les éventuels doublons sont fusionnés ou dédupliqués,
- Les éventuels doublons ne sont pas créés en tant que nouveaux enregistrements,
- Les règles commerciales personnalisées ne sont pas violées, etc.
En outre, vous pouvez également définir des seuils pour la mesure de la qualité des données et déclencher des alertes si la qualité des données se détériore, même un peu en dessous de ces niveaux.
Et c’est reparti…
Un cycle ou un cadre de qualité des données est un processus itératif. Une fois que vous avez atteint le stade du contrôle, quelques erreurs de qualité des données peuvent survenir. Cela montre que le cadre défini présente encore certaines lacunes qui ont entraîné des erreurs. Pour cette raison, la phase d’évaluation doit être déclenchée à nouveau, ce qui déclenche ensuite les phases de conception et d’exécution. De cette façon, votre cadre de qualité des données est constamment mis à jour et perfectionné pour répondre à vos besoins en matière de qualité des données.
Quand le cycle est-il itéré ?
Il y a deux façons de déclencher l’étape d’évaluation :
1. Approche proactive
Dans cette approche, vous pouvez sélectionner une date et une heure régulières auxquelles les rapports de performance générés sont analysés. Si des erreurs sont rencontrées dans ce laps de temps, l’étape d’évaluation est à nouveau déclenchée. Cette approche vous permet de garder un œil sur les éventuelles erreurs qui peuvent survenir.
2. Approche réactive
Comme son nom l’indique, l’étape d’évaluation est déclenchée lorsqu’une erreur de qualité des données est rencontrée. Bien que les deux approches aient leurs propres avantages, il est préférable d’appliquer les deux à votre cadre de qualité des données afin que l’état de la qualité des données soit constamment surveillé de manière proactive et que les erreurs soient corrigées au moment où elles se produisent.
Conclusion
La qualité des données n’est pas une destination unique. C’est quelque chose qui doit être constamment évalué et amélioré. C’est pourquoi il est très important de concevoir des cadres complets qui gèrent en permanence la qualité de plusieurs ensembles de données. L’utilisation d’outils autonomes de qualité des données peut être très productive dans ce cas – étant donné qu’ils ont la capacité de :
- S’intégrer au milieu de vos sources d’entrée et de sortie,
- Effectuer une analyse détaillée pour générer des rapports sur le profil des données,
- Prendre en charge divers processus de qualité des données qui peuvent être affinés et personnalisés selon les besoins,
- Offrir des services de traitement par lots ou en temps réel, etc.
DataMatch Enterprise est l’une de ces solutions – disponible sous forme d’application autonome ou d’API intégrable – qui permet une gestion de la qualité des données de bout en bout, y compris le profilage, le nettoyage, la mise en correspondance, la déduplication et la purge par fusion des données.
Vous pouvez télécharger l’essai gratuit dès aujourd’hui ou programmer une session personnalisée avec nos experts pour comprendre comment nous pouvons vous aider à concevoir un cadre de qualité des données pour votre entreprise.



