




























Last Updated on mayo 19, 2022
Según el informe de O’Reilly El estado de la calidad de los datos en 2020 el 56% de las organizaciones se enfrenta a al menos cuatro tipos diferentes de problemas de calidad de datos, mientras que el 71% se enfrenta a al menos tres tipos diferentes. No es de extrañar que el número y el tipo de problemas de calidad de los datos varíen entre las distintas organizaciones. Pero es sorprendente que la mayoría de las empresas tiendan a adoptar y aplicar soluciones generalizadas para resolver sus problemas de calidad de datos, en lugar de diseñar algo que sirva para su caso único.
Aquí es donde entra en juego un marco de calidad de datos de principio a fin. En un blog anterior, hablamos de los principales procesos de calidad de datos que hay que conocer antes de diseñar un marco de calidad de datos. En este blog, veremos cómo se pueden utilizar estos procesos para diseñar un plan de mejora continua de la calidad de los datos.
Vamos a sumergirnos.
¿Qué es un marco de calidad de datos?
El marco de calidad de los datos (también conocido como ciclo de vida de la calidad de los datos) es un proceso sistemático que supervisa el estado actual de la calidad de los datos y garantiza que se mantenga por encima de los umbrales definidos. Suele diseñarse en un ciclo para que los resultados se evalúen continuamente y los errores se corrijan sistemáticamente a tiempo.
Ejemplo de marco de calidad de datos
Las empresas que quieren solucionar sus problemas de calidad de datos adoptan casi los mismos procesos de calidad de datos. Pero en el marco de la calidad de los datos es donde difieren sus planes. Por ejemplo, un sistema de gestión de la calidad de los datos utilizará sin duda algunas técnicas básicas de estandarización de datos para conseguir una visión coherente de todos los valores de los datos. Pero la naturaleza exacta de estas técnicas de normalización depende del estado actual de sus datos y de lo que desee conseguir.
Por eso, aquí veremos un marco de calidad de datos genérico pero completo, algo que cualquier organización puede adoptar para su caso de negocio único.
Un marco o ciclo de vida sencillo de la calidad de los datos consta de cuatro etapas:
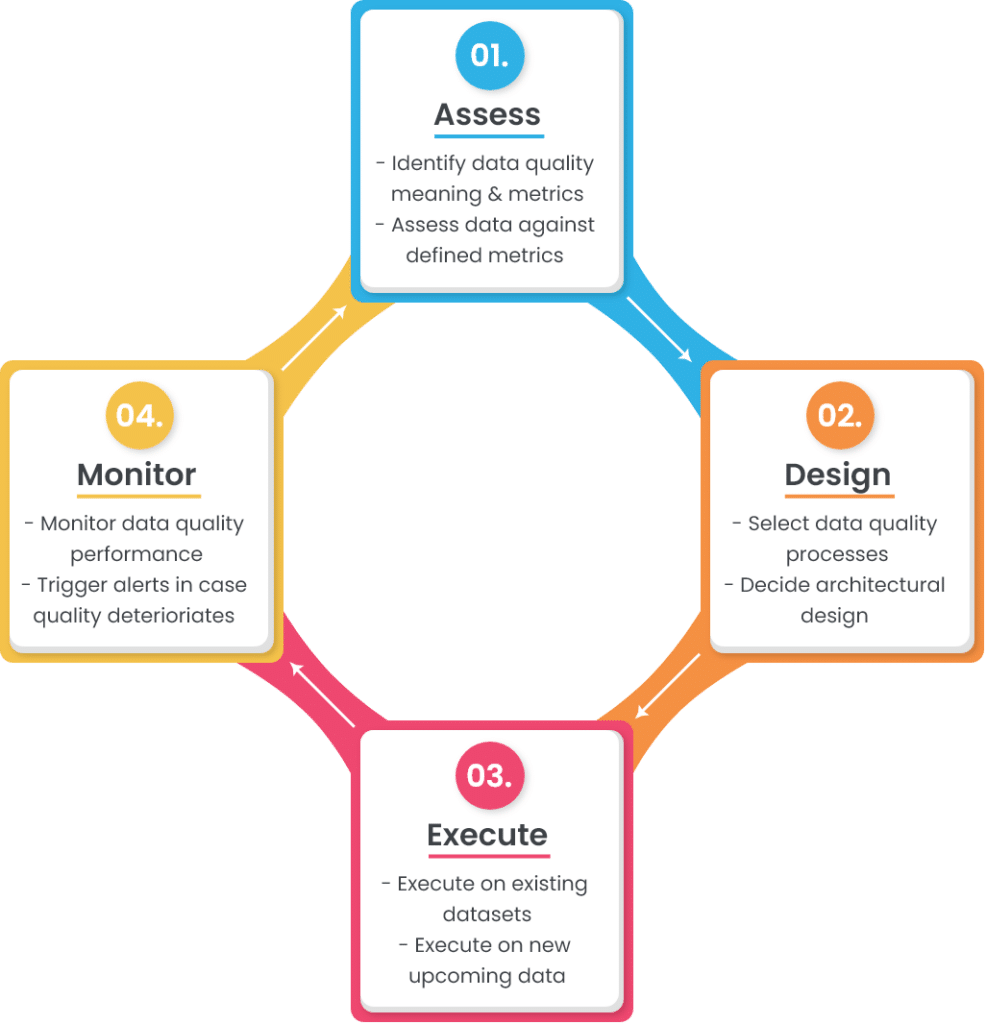
En las próximas secciones se analiza cada una de estas etapas con más detalle.
1. Evaluar
Este es el primer paso del marco en el que hay que evaluar los dos componentes principales: el significado de la calidad de los datos para su empresa y la puntuación de los datos actuales con respecto a ella.
a. Identificar el significado y las métricas de la calidad de los datos
La calidad de los datos se define como el grado en que los datos cumplen con su objetivo. Y para definir lo que significa la calidad de los datos para su empresa, es necesario conocer el papel que desempeña en las diferentes operaciones.
Tomemos como ejemplo un conjunto de datos de clientes. Se requiere un nivel de calidad aceptable en sus conjuntos de datos de clientes, tanto si se utilizan para contactar con ellos como si se analizan para la toma de decisiones empresariales. Para definir el significado de los datos de los clientes de buena calidad, hay que hacer lo siguiente:
- Identifique las fuentes de las que proceden los datos de los clientes (formularios web, proveedores externos, clientes, etc.),
- Seleccione los atributos necesarios que completan la información del cliente (nombre, número de teléfono, dirección de correo electrónico, dirección geográfica, etc.),
- Definir los metadatos de los atributos seleccionados (tipo de datos, tamaño, formato, patrón, etc.)
- Explique los criterios de aceptabilidad de los datos almacenados (el nombre del cliente debe ser 100% exacto en todo momento, mientras que sus preferencias de producto pueden ser hasta 95% exactas).
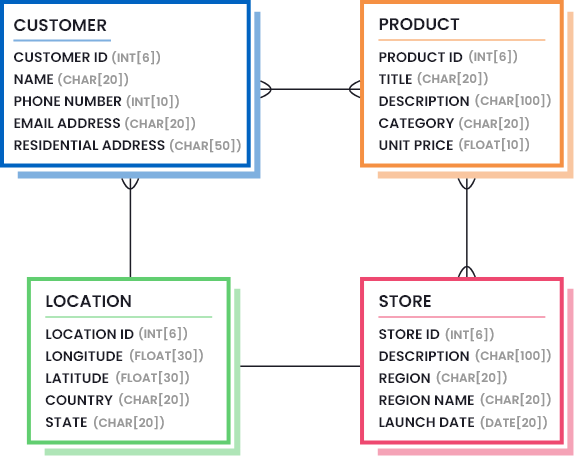
Esta información suele definirse dibujando modelos de datos que destacan las partes necesarias de los datos (la cantidad y calidad de los datos que se consideran suficientemente buenos). Considere la siguiente imagen para entender cómo puede ser un modelo de datos para una empresa minorista:
Además, hay que identificar las métricas de calidad de los datos y sus umbrales aceptables. A continuación se ofrece una lista de las métricas de calidad de datos más comunes, pero debe seleccionar las que sean útiles en su caso, y averiguar los valores de percentiles mínimos que representen una buena calidad de datos.
- Exactitud: ¿En qué medida los valores de los datos reflejan la realidad/corrección?
- Linaje: ¿Cómo de fiable es la fuente de origen de los valores de los datos?
- Semántica: ¿Los valores de los datos son fieles a su significado?
- Estructura: ¿Existen los valores de los datos en el patrón y/o formato correcto?
- Integridad: ¿Son sus datos tan completos como necesita?
- Consistencia: ¿Tienen los almacenes de datos dispares los mismos valores de datos para los mismos registros?
- Lamoneda: ¿Sus datos están aceptablemente actualizados?
- Puntualidad: ¿Con qué rapidez se facilitan los datos solicitados?
- Razonabilidad: ¿Los valores de los datos tienen el tipo y el tamaño correctos?
- Identificabilidad: ¿Cada registro representa una identidad única y no es un duplicado?
b. Evaluar los conjuntos de datos actuales con respecto a las métricas definidas
El primer paso de la evaluación le ayuda a definir los objetivos. El siguiente paso en la evaluación es medir el rendimiento de sus datos actuales en comparación con los objetivos establecidos. Este paso suele realizarse generando informes detallados de perfiles de datos. La elaboración de perfiles de datos es un proceso que analiza la estructura y el contenido de sus conjuntos de datos y descubre detalles ocultos.
Una vez generados los informes de los perfiles de datos, puede compararlos con el objetivo establecido. Por ejemplo, un objetivo establecido podría ser que los clientes deben tener un nombre y un apellido; si el informe de perfil de datos generado muestra un 85% de integridad en el nombre del cliente, hay que buscar el 15% restante de la información que falta.
2. Diseñar
El siguiente paso en el marco de la calidad de datos es diseñar las reglas de negocio que garantizarán la conformidad con el modelo de datos y los objetivos definidos en la fase de evaluación. La fase de diseño consta de dos componentes principales:
- Seleccionar los procesos de calidad de datos que necesita y ajustarlos según sus necesidades,
- Decidir dónde integrar las funciones de calidad de datos (diseño arquitectónico).
Veamos esto con más detalle.
a. Seleccionar procesos de calidad de datos
En función del estado de sus datos, debe seleccionar una lista de procesos de calidad de datos que le ayuden a alcanzar el estado de calidad deseado. Normalmente, se llevan a cabo una serie de procesos de calidad de datos para corregir errores o transformar los datos en la forma y estructura requeridas.
A continuación, hemos enumerado los procesos de calidad de datos más comunes utilizados por las organizaciones. El orden en que deben aplicarse en los datos próximos o existentes es su elección. Los ejemplos proporcionados para cada proceso le ayudarán a navegar si este proceso es útil para su caso o puede ser omitido.
i. Análisis y fusión de datos
El análisis sintáctico de datos consiste en analizar cadenas largas y dividir los subcomponentes en una o varias columnas. Esto se suele hacer para tener los elementos importantes en columnas separadas para que puedan ser:
- Validado con una biblioteca de valores precisos,
- Transformados en formatos aceptables, o
- Comparado con otros registros para encontrar posibles duplicados.
Del mismo modo, los subcomponentes se fusionan para obtener más significado de los campos individuales.
Ejemplo: Análisis de la columna Dirección en número de calle, nombre de la calle, ciudad, estado, código postal, país, etc.
ii. Limpieza y estandarización de datos
Lalimpieza y estandarización dedatos es el proceso de eliminar la información incorrecta e inválida presente en un conjunto de datos para conseguir una visión coherente y utilizable en todas las fuentes de datos.
Ejemplo:
- Eliminación de valores nulos, espacios iniciales y finales, caracteres especiales, etc,
- Sustituir las abreviaturas por formas completas, o las palabras repetitivas por palabras normalizadas,
- Transformación de los casos de las letras (de inferior a superior, de superior a inferior),
- Estandarizar los valores para que sigan el patrón y el formato correctos, etc.
iii. Comparación y deduplicación de datos
Elcotejo de datos (también conocido como vinculación de registros y resolución de entidades) es el proceso de comparar dos o más registros e identificar si pertenecen a la misma entidad. Si varios registros coinciden, se conserva el registro principal y se eliminan los duplicados para obtener el registro de oro.
Ejemplo: Si la información de los clientes de su empresa se captura y se mantiene en diferentes fuentes (CRM, software de contabilidad, herramienta de marketing por correo electrónico, rastreador de actividad del sitio web, etc.), pronto acabará teniendo múltiples registros del mismo cliente. En estos casos, tendrá que realizar un cotejo exacto o difuso para determinar los registros que pertenecen al mismo cliente y los que son posibles duplicados.
iv. Fusión de datos y supervivencia
Una vez que encuentre registros duplicados en su conjunto de datos, puede simplemente eliminar los duplicados o fusionarlos para conservar la máxima información y evitar la pérdida de datos. Lafusión y supervivencia de datos es un proceso de calidad de datos que le ayuda a crear reglas que fusionan los registros duplicados mediante la selección condicional y la sobrescritura.
Ejemplo: Es posible que quiera mantener el registro que tiene el nombre de cliente más largo y utilizarlo como registro maestro, mientras sobrescribe el código postal más largo del registro duplicado en el maestro. Una lista priorizada de estas reglas le ayudará a sacar el máximo provecho de su conjunto de datos.
v. Reglas de validación o dependencia personalizadas
Aparte de los procesos de calidad de datos estandarizados, puede tener reglas de validación personalizadas que son únicas para su operación de negocios.
Ejemplo: Si un cliente ha realizado una compra del producto A, sólo puede disponer de un descuento de hasta el 20%. (Es decir, si la compra es el producto A, eldescuentodebe ser <= 20%).
Estas reglas de dependencia específicas de la empresa deben ser validadas para garantizar la alta calidad de los datos.
b. Decidir el diseño arquitectónico
Ahora que hemos echado un vistazo a algunos procesos comunes de calidad de datos utilizados en un marco de calidad de datos, es el momento de considerar un aspecto más importante: ¿cómo se integran estas operaciones de calidad de datos en su ciclo de vida?
Hay múltiples maneras de que esto sea posible, entre ellas:
1. Implementar funciones de calidad de datos en la entrada: esto puede implicar poner controles de validación en los formularios web o en las interfaces de aplicación utilizadas para almacenar datos.
2. Introducir un middleware que valide y transforme los datos entrantes antes de almacenarlos en la fuente de destino.

3. Poner comprobaciones de validación en la base de datos, para que se produzcan errores al almacenar los datos en el almacén de datos.
Aunque la primera forma parece la mejor, tiene sus propias limitaciones. Dado que una organización media utiliza más de 40 aplicaciones, es difícil sincronizar cada fuente de entrada para producir la salida requerida.
Para saber más, consulte: ¿Cómo se empaquetan las funciones de calidad de datos en las herramientas de software?
3. Ejecutar
En la tercera etapa del ciclo es donde se produce la ejecución. Has preparado el escenario en los dos pasos anteriores, ahora es el momento de ver el rendimiento real del sistema.
Es importante tener en cuenta que puede ser necesario ejecutar los procesos configurados en los datos existentes primero y asegurar su alta calidad. En la siguiente fase, puede desencadenar la ejecución de nuevos flujos de datos.
4. Monitorizar
Esta es la última etapa del marco en la que se supervisan los resultados. Puede utilizar las mismas técnicas de perfilado de datos que se utilizaron durante la fase de evaluación para generar informes de rendimiento detallados. El objetivo es ver hasta qué punto los datos se ajustan a los objetivos fijados, por ejemplo:
- Los datos entrantes se analizan y combinan según sea necesario,
- Los atributos requeridos no son nulos,
- Las palabras abreviadas se transforman según sea necesario,
- Los datos se estandarizan según el formato y el patrón establecidos,
- Los posibles duplicados se fusionan o deduplican,
- Los posibles duplicados no se crean como nuevos registros,
- No se violan las reglas de negocio personalizadas, etc.
Además, también puede establecer algunos umbrales para la medición de la calidad de los datos, y activar alertas en caso de que la calidad de los datos se deteriore incluso un poco por debajo de estos niveles.
Y aquí vamos de nuevo…
Un ciclo o marco de calidad de datos es un proceso iterativo. Una vez que haya llegado a la fase de control, pueden surgir algunos errores de calidad de los datos. Esto demuestra que el marco definido todavía tiene algunas lagunas que provocan errores. Por ello, hay que volver a activar la fase de evaluación, lo que desencadena las fases de diseño y ejecución. De este modo, su marco de calidad de datos se actualiza y perfecciona constantemente para satisfacer sus necesidades de calidad de datos.
¿Cuándo se itera el ciclo?
Hay dos maneras de activar la fase de evaluación:
1. Enfoque proactivo
En este enfoque, se puede seleccionar una fecha y hora regulares en las que se analizan los informes de rendimiento generados y, en caso de que se encuentre algún error dentro de ese plazo, se vuelve a activar la etapa de evaluación. Este enfoque le ayuda a vigilar los posibles errores que puedan surgir.
2. Enfoque reactivo
Como su nombre indica, la etapa de evaluación se activa cuando se encuentra un error en la calidad de los datos. Aunque ambos enfoques tienen sus propias ventajas, lo mejor es aplicar ambos a su marco de calidad de datos para que el estado de la calidad de los datos se supervise constantemente de forma proactiva, así como para ocuparse de él en el momento en que se produzca cualquier error.
Conclusión:
La calidad de los datos no es un destino único. Es algo que hay que evaluar y mejorar constantemente. Por esta razón, es muy crucial diseñar marcos integrales que gestionen continuamente la calidad de múltiples conjuntos de datos. Utilizar herramientas de calidad de datos independientes puede ser muy productivo para este caso, dado que tienen la capacidad de:
- Integrar en medio de sus fuentes de entrada y salida,
- Realizar análisis detallados para generar informes de perfiles de datos,
- Soporta varios procesos de calidad de datos que pueden ser ajustados y personalizados según sea necesario,
- Ofrecer servicios de procesamiento por lotes o en tiempo real, etc.
DataMatch Enterprise es una de estas soluciones -disponible como aplicación independiente y como API integrable- que permite la gestión de la calidad de los datos de principio a fin, incluida la elaboración de perfiles de datos, la limpieza, la comparación, la deduplicación y la purga de fusiones.
Puede descargar la prueba gratuita hoy mismo o programar una sesión personalizada con nuestros expertos para entender cómo podemos ayudarle a diseñar un marco de calidad de datos para su empresa.



