





























Last Updated on Januar 7, 2022
In diesem Blog:
- Datenqualität – Können Sie die vorhandenen Daten verwenden?
- Was sind die Dimensionen der Datenqualität?
- Wie viele Dimensionen der Datenqualität gibt es?
- Welche Datenqualitätsdimensionen sind zu verwenden?
- Automatisierung der Datenqualitätsmessung mit DataMatch Enterprise
„84 % der CEOs sind besorgt über die Qualität der Daten, auf die sie ihre Entscheidungen stützen“.
2016 Global CEO Outlook, Forbes Insight & KPMG
Nahezu alle Prozesse in der Welt unterliegen einer digitalen Transformation. Der Wert physischer Informationen nimmt ab, und digitale Informationen erhalten mehr Aufmerksamkeit und werden daher auch stärker genutzt. Die Digitalisierung von Prozessen führt zu einem starken Anstieg der Datenerzeugung und -erfassung. Forscher und IT-Spezialisten arbeiten an der Einführung neuer Datenspeichereinheiten – wie Zettabyte (10^21 Byte), Yottabyte (10^24 Byte), Brontobyte (10^27 Byte) und Geopbyte (10^30 Byte).
Datenqualität – Können Sie die vorhandenen Daten verwenden?
Komplex wird es, wenn es darum geht, die in unterschiedlichen Quellen gespeicherten Daten zu nutzen. Die größte Schwierigkeit bei der digitalen Transformation besteht darin, die Daten und ihre Attribute effizient und für den beabsichtigten Zweck zu nutzen.
Die Norm ISO/IEC 25012 definiert die Datenqualität als den Grad, in dem die Daten die Anforderungen ihres Verwendungszwecks erfüllen. Wenn die gespeicherten Daten nicht in der Lage sind, die Anforderungen der Organisation zu erfüllen, spricht man von schlechter Qualität; und die Kosten einer schlechten Datenqualität werden stark unterschätzt.
Was sind die Dimensionen der Datenqualität?
Diese von der ISO-Norm vorgeschlagene Definition impliziert, dass die Bedeutung der Datenqualität davon abhängt, wie Sie die Daten verwenden möchten. So ist beispielsweise in einigen Fällen die Genauigkeit der Daten wichtiger als ihre Vollständigkeit, während in anderen Fällen das Gegenteil der Fall sein kann.
Dieses Konzept führt die Idee der Datenqualitätsdimensionen ein – was einfach bedeutet, dass die Qualität der Daten auf unterschiedliche Weise gemessen werden kann. Datenqualitätsdimensionen stellen eine Liste von Metriken dar, mit deren Hilfe die Eignung von Daten für einen bestimmten Verwendungszweck beurteilt werden kann.
Wie viele Dimensionen der Datenqualität gibt es?
Einige betonen sechs Dimensionen der Datenqualität, während andere von acht oder sogar zehn Dimensionen der Datenqualität sprechen. Technisch gesehen fallen alle Datenqualitätsmetriken unter zwei große Kategorien: Die erste bezieht sich auf die intrinsischen Merkmale der Daten, die zweite auf ihre kontextuellen Merkmale.
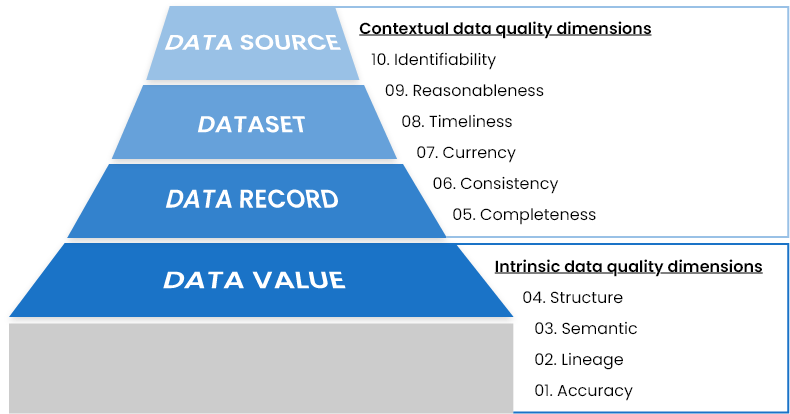
Dimensionen der Datenqualität entsprechend der Datenhierarchie
Die Datenhierarchie in jedem Unternehmen beginnt mit einem einzigen Datenwert. Datenwerte verschiedener Attribute werden für eine bestimmte Entität oder ein bestimmtes Vorkommen zu einem Datensatz zusammengefasst. Mehrere Datensätze (die mehrere Vorkommen desselben Typs repräsentieren) werden zu einem Datensatz gruppiert. Diese Datensätze können sich in jeder beliebigen Quelle oder Anwendung befinden, um die Anforderungen eines Unternehmens zu erfüllen.
Die Dimensionen der Datenqualität verhalten sich auf jeder Ebene der Datenhierarchie anders und werden unterschiedlich gemessen. In der folgenden Abbildung sehen Sie, wie die Datenqualität auf den einzelnen Ebenen bewertet wird.
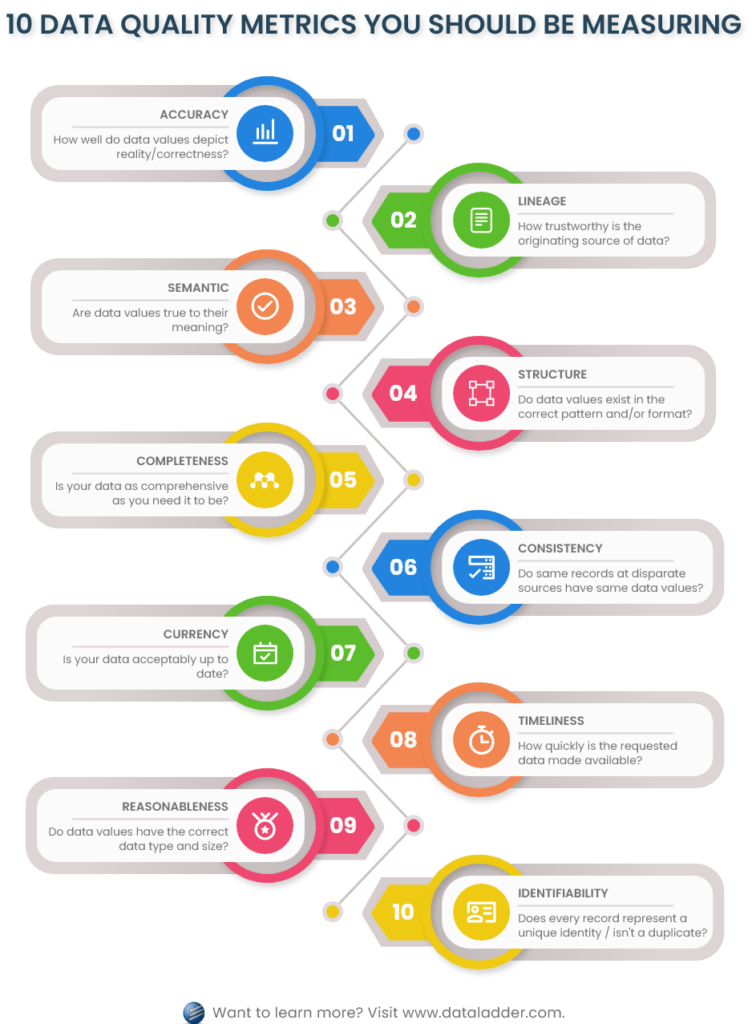
In diesem Artikel werden wir diese zehn Dimensionen der Datenqualität behandeln, die in zwei Kategorien unterteilt sind.
A. Intrinsische Dimensionen der Datenqualität
Diese Dimensionen beurteilen und bewerten direkt den Wert der Daten – auf granularer Ebene: Bedeutung, Verfügbarkeit, Bereich, Struktur, Format, Metadaten usw. Diese Dimensionen berücksichtigen nicht den Kontext, in dem der Wert gespeichert wurde, wie z. B. seine Beziehung zu anderen Attributen oder der Datensatz, in dem er sich befindet.
Die folgenden vier Dimensionen der Datenqualität fallen unter die Kategorie „intrinsisch“:
1. Genauigkeit
WIE GUT BILDEN DIE DATENWERTE DIE REALITÄT/KORREKTHEIT AB?
DieGenauigkeit der Datenwerte wird gemessen, indem sie mit einer bekannten Quelle korrekter Informationen abgeglichen werden. Diese Messung kann komplex sein, wenn es mehrere Quellen gibt, die die richtigen Informationen enthalten. In solchen Fällen müssen Sie diejenige auswählen, die für Ihren Bereich am besten geeignet ist, und den Grad der Übereinstimmung jedes Datenwerts mit der Quelle berechnen.
Beispiel für genaue Datenwerte
Nehmen wir eine Mitarbeiterdatenbank, die als Attribut die Kontaktnummer der Mitarbeiter enthält. Eine genaue Telefonnummer ist diejenige, die korrekt ist und in der Realität existiert. Sie können alle Telefonnummern in Ihrer Mitarbeiterdatenbank überprüfen, indem Sie sie mit einer offiziellen Datenbank abgleichen, die eine Liste mit gültigen Telefonnummern enthält.
2. Abstammung
WIE VERTRAUENSWÜRDIG IST DIE HERKUNFTSQUELLE DER DATENWERTE?
Die Abstammung der Datenwerte wird überprüft oder getestet, indem die Ursprungsquelle und/oder alle Quellen, die die Informationen im Laufe der Zeit aktualisiert haben, validiert werden. Dies ist eine wichtige Maßnahme, da sie die Vertrauenswürdigkeit der erfassten Daten beweist und diese sich im Laufe der Zeit weiterentwickeln.
Beispiel für die Abstammung von Datenwerten
Im obigen Beispiel sind die Kontaktnummern der Mitarbeiter vertrauenswürdig, wenn sie aus einer gültigen Quelle stammen. Und die beste Quelle für diese Art von Informationen ist der Mitarbeiter selbst – entweder werden die Daten beim ersten Mal eingegeben oder im Laufe der Zeit aktualisiert. Wurden die Telefonnummern aus einem öffentlichen Telefonbuch entnommen, so ist diese Quelle auf jeden Fall fragwürdig und könnte möglicherweise Fehler enthalten.
3. Semantisch
ENTSPRECHEN DIE DATENWERTE IHRER BEDEUTUNG?
Um die Datenqualität zu gewährleisten, muss der Datenwert semantisch korrekt sein, d. h. er muss eine Bedeutung haben – insbesondere im Kontext der Organisation oder Abteilung, in der er verwendet wird. Informationen werden normalerweise zwischen verschiedenen Abteilungen und Prozessen in einem Unternehmen ausgetauscht. In solchen Fällen müssen sich die Beteiligten und die Nutzer der Daten auf die Bedeutung aller Attribute des Datensatzes einigen, damit sie semantisch überprüft werden können.
Beispiel für semantisch korrekte Datenwerte
Ihre Mitarbeiterdatenbank kann zwei Attribute haben, die die Kontaktnummern der Mitarbeiter speichern, nämlich Telefonnummer 1 und Telefonnummer 2. Eine vereinbarte Definition der beiden Attribute könnte lauten, dass Telefonnummer 1 die persönliche Handynummer des Mitarbeiters ist, während Telefonnummer 2 seine private Telefonnummer ist.
Es ist wichtig zu beachten, dass die Genauigkeitsmessung das Vorhandensein und die Echtheit beider Nummern bestätigt, während die semantische Messung sicherstellt, dass beide Nummern ihrer impliziten Definition entsprechen – d.h. die erste ist eine Handynummer, während die zweite eine Privatnummer ist.
4. Aufbau
SIND DIE DATENWERTE IM RICHTIGEN MUSTER UND/ODER FORMAT VORHANDEN?
Die Strukturanalyse bezieht sich auf die Überprüfung der Darstellung von Datenwerten, d.h. ob die Werte ein gültiges Muster und Format haben. Diese Überprüfungen werden besser bei der Dateneingabe und -erfassung vorgenommen und durchgesetzt, so dass alle eingehenden Daten zunächst validiert und bei Bedarf umgewandelt werden, bevor sie in der Anwendung gespeichert werden.
Beispiel für strukturell korrekte Datenwerte
Im obigen Beispiel der Mitarbeiterdatenbank müssen alle Werte in der Spalte „Telefonnummer 1“ korrekt strukturiert und formatiert sein. Ein Beispiel für eine schlecht strukturierte Rufnummer ist: 134556-7(9080. Es ist jedoch möglich, dass die Zahl selbst (ohne den zusätzlichen Bindestrich und die Klammern) korrekt und semantisch richtig ist. Aber das richtige Format und Muster der Nummer sollte sein:
+1-345-567-9080.
B. Dimensionen der kontextuellen Datenqualität
Diese Dimensionen beurteilen und bewerten Daten in ihrem gesamten Kontext – z. B. alle Datenwerte eines Attributs zusammen oder in Datensätzen gruppierte Datenwerte und so weiter. Diese Dimensionen konzentrieren sich auf die Beziehungen zwischen verschiedenen Datenkomponenten und deren Übereinstimmung mit den Erwartungen an die Datenqualität.
Die folgenden sechs Datenqualitätsdimensionen fallen unter die kontextbezogene Kategorie:
5. Vollständigkeit
SIND IHRE DATEN SO UMFASSEND, WIE SIE SIE BENÖTIGEN?
Die Vollständigkeit gibt an, inwieweit die benötigten Datenwerte ausgefüllt sind und nicht leer gelassen wurden. Diese kann vertikal (Attributebene) oder horizontal (Datensatzebene) berechnet werden. In der Regel werden Felder als obligatorisch/erforderlich gekennzeichnet, um die Vollständigkeit eines Datensatzes zu gewährleisten. Bei der Berechnung der Vollständigkeit müssen die drei verschiedenen Arten berücksichtigt werden, um die Genauigkeit der Ergebnisse zu gewährleisten:
- Erforderliches Feld , das nicht leer gelassen werden kann, z. B. die nationale ID eines Mitarbeiters.
- Optionales Feld, das nicht unbedingt ausgefüllt werden muss, z. B. das Feld Hobbys für einen Mitarbeiter.
- Unzutreffendes Feld, das im Kontext des Datensatzes irrelevant ist und leer gelassen werden sollte, z. B. Name des Ehepartners bei einer nicht verheirateten Person.
Beispiel für vollständige Daten
Ein Beispiel für vertikale Vollständigkeit ist die Berechnung des Prozentsatzes der Arbeitnehmer, für die die Telefonnummer 1 angegeben ist. Ein Beispiel für horizontale Vollständigkeit ist die Berechnung des prozentualen Anteils der vollständigen Informationen zu einem bestimmten Mitarbeiter; so können die Daten eines Mitarbeiters zu 80 % vollständig sein, während seine Kontaktnummer und seine Wohnanschrift fehlen.
6. Konsistenz
HABEN UNTERSCHIEDLICHE DATENSPEICHER DIESELBEN DATENWERTE FÜR DIESELBEN DATENSÄTZE?
Bei der Konsistenzprüfung wird geprüft, ob die für denselben Datensatz in verschiedenen Quellen gespeicherten Datenwerte widerspruchsfrei und exakt gleich sind – sowohl in Bezug auf die Bedeutung als auch auf die Struktur und das Format.
Konsistente Daten helfen bei der Erstellung einheitlicher und genauer Berichte über alle Funktionen und Abläufe in Ihrem Unternehmen. Konsistenz bezieht sich nicht nur auf die Bedeutung der Datenwerte, sondern auch auf ihre Darstellung; wenn beispielsweise Werte nicht anwendbar oder nicht verfügbar sind, müssen einheitliche Begriffe verwendet werden, um die Nichtverfügbarkeit von Daten in allen Quellen darzustellen.
Beispiele für konsistente Daten
Mitarbeiterinformationen werden in der Regel in Anwendungen für die Personalverwaltung gespeichert, aber die Datenbank muss auch für andere Abteilungen wie die Lohnbuchhaltung oder die Finanzabteilung freigegeben oder repliziert werden. Um die Konsistenz zu gewährleisten, müssen alle datenbankübergreifend gespeicherten Attribute die gleichen Werte haben. Andernfalls können Unterschiede bei der Bankkontonummer oder anderen wichtigen Feldern zu einem großen Problem werden.
7. Währung
SIND IHRE DATEN AKZEPTABEL AUF DEM NEUESTEN STAND?
Die Aktualität bezieht sich darauf, inwieweit die Datenattribute im Zusammenhang mit ihrer Verwendung das richtige Alter haben. Diese Maßnahme trägt dazu bei, die Informationen auf dem neuesten Stand und in Übereinstimmung mit der aktuellen Welt zu halten, so dass Ihre Momentaufnahmen von Daten nicht Wochen oder Monate alt sind, was dazu führt, dass Sie kritische Entscheidungen auf der Grundlage veralteter Informationen präsentieren und treffen müssen.
Um die Aktualität Ihres Datensatzes zu gewährleisten, können Sie Erinnerungen zur Datenaktualisierung einrichten oder Altersgrenzen für ein Attribut festlegen, um sicherzustellen, dass alle Werte in einer bestimmten Zeit überprüft und aktualisiert werden.
Beispiel für aktuelle Daten
Die Kontaktinformationen Ihres Mitarbeiters sollten rechtzeitig überprüft werden, um festzustellen, ob sich in letzter Zeit etwas geändert hat und im System aktualisiert werden muss.
8. Rechtzeitigkeit
WIE SCHNELL WERDEN DIE ANGEFORDERTEN DATEN ZUR VERFÜGUNG GESTELLT?
Die Aktualität misst die Zeit, die benötigt wird, um auf die angeforderten Informationen zuzugreifen. Wenn die Bearbeitung Ihrer Datenabfragen zu lange dauert, kann es sein, dass Ihre Daten nicht gut organisiert, verknüpft, strukturiert oder formatiert sind.
Die Aktualität misst auch, wie schnell die neuen Informationen in allen Quellen zur Verfügung stehen. Wenn Ihr Unternehmen komplexe und zeitaufwändige Prozesse zur Speicherung eingehender Daten einsetzt, kann es passieren, dass Benutzer an einigen Stellen alte Informationen abfragen und verwenden.
Beispiel für Rechtzeitigkeit
Um die Aktualität zu gewährleisten, können Sie die Antwortzeit Ihrer Mitarbeiterdatenbank überprüfen. Darüber hinaus können Sie auch testen, wie lange es dauert, bis die in der HR-Anwendung aktualisierten Informationen in der Gehaltsabrechnungsanwendung repliziert werden usw.
9. Angemessenheit
HABEN DIE DATENWERTE DEN RICHTIGEN DATENTYP UND DIE RICHTIGE GRÖSSE?
Die Angemessenheit misst den Grad, in dem Datenwerte einen angemessenen oder verständlichen Datentyp und eine angemessene Größe haben. So ist es beispielsweise üblich, Zahlen in einem alphanumerischen Zeichenfolgenfeld zu speichern, aber die Vernunft sorgt dafür, dass ein Attribut, das nur Zahlen speichert, vom Typ Zahl sein sollte.
Darüber hinaus erzwingt die Vernünftigkeit auch die Begrenzung von Höchst- und Mindestzeichen für Attribute, so dass keine ungewöhnlich langen Zeichenfolgen in der Datenbank vorkommen. Die Plausibilitätsmaßnahme reduziert den Raum für Fehler, indem sie Beschränkungen für den Datentyp und die Größe eines Attributs erzwingt.
Beispiel für Angemessenheit
Das Feld Telefonnummer 1 sollte – wenn es ohne Bindestriche und Sonderzeichen gespeichert wird – auf numerisch eingestellt sein und eine maximale Zeichenbegrenzung haben, damit nicht versehentlich zusätzliche alphanumerische Zeichen hinzugefügt werden.
10. Identifizierbarkeit
STELLT JEDER DATENSATZ EINE EINDEUTIGE IDENTITÄT DAR UND IST KEIN DUPLIKAT?
Die Identifizierbarkeit berechnet den Grad, in dem Datensätze eindeutig identifizierbar sind und keine Duplikate voneinander sind.
Um die Identifizierbarkeit zu gewährleisten, wird für jeden Datensatz ein eindeutig identifizierendes Attribut in der Datenbank gespeichert. In einigen Fällen, wie z. B. bei Organisationen des Gesundheitswesens, werden jedoch persönlich identifizierbare Informationen (PII) entfernt, um die Vertraulichkeit der Patienten zu wahren. An dieser Stelle müssen Sie möglicherweise Fuzzy-Matching-Techniken anwenden, um Datensätze zu vergleichen, abzugleichen und zusammenzuführen.
Beispiel für Identifizierbarkeit
Ein Beispiel für die Identifizierbarkeit ist die Vorgabe, dass jeder neue Datensatz in der Mitarbeiterdatenbank eine eindeutige Mitarbeiter-ID-Nummer enthalten muss, über die er identifiziert werden kann.
Welche Datenqualitätsdimensionen sind zu verwenden?
Wir haben die zehn am häufigsten verwendeten Datenqualitätsmetriken untersucht. Da jedes Unternehmen seine eigenen Anforderungen und KPIs hat, müssen Sie möglicherweise andere Metriken verwenden oder eigene erstellen. Die Auswahl der Datenqualitätsdimensionen hängt von mehreren Faktoren ab, z. B. von der Branche, in der Ihr Unternehmen tätig ist, von der Art Ihrer Daten und von der Rolle, die sie für den Erfolg Ihrer Ziele spielen.
Da jede Branche ihre eigenen Datenregeln, Berichterstattungsmechanismen und Messkriterien hat, werden unterschiedliche Datenqualitätsmetriken verwendet, um den jeweiligen Anforderungen gerecht zu werden, z. B. Behörden, Finanz- und Versicherungsabteilungen, Gesundheitseinrichtungen, Vertrieb und Marketing, Einzelhandel oder Bildungssysteme usw.
Automatisierung der Datenqualitätsmessung mit DataMatch Enterprise
Wenn man bedenkt, wie komplex die Messung der Datenqualität werden kann, ist dies ein Prozess, von dem man normalerweise erwartet, dass er von technisch versierten oder datenkundigen Fachleuten durchgeführt wird. Die Nichtverfügbarkeit fortgeschrittener Profiling-Funktionen in einem Self-Service-Datenqualitäts-Tool ist eine häufige Herausforderung.
Ein Self-Service-Tool für die Datenqualität, das eine schnelle 360°-Sicht auf die Daten ermöglicht und grundlegende Anomalien wie leere Werte, Felddatentypen, wiederkehrende Muster und andere deskriptive Statistiken erkennt, ist eine Grundvoraussetzung für jede datengesteuerte Initiative. DataMatch Enterprise von Data Ladder ist eine vollwertige Datenqualitätslösung, die nicht nur eine Bewertung der Datenqualität bietet, sondern auch detaillierte Datenbereinigung, -abgleich und -zusammenführung durchführt.
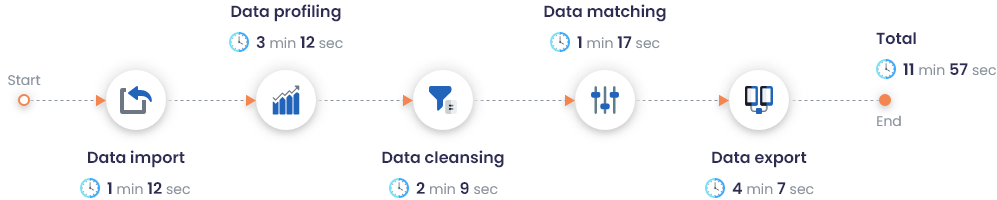
DME-Leistung bei einem Datensatz von 2 Mio. Datensätzen
Mit DataMatch Enterprise können Sie schnelle Genauigkeits-, Vollständigkeits- und Validierungsprüfungen durchführen. Anstatt Diskrepanzen in Ihrem Datensatz manuell zu identifizieren und zu markieren, kann Ihr Team mit DME im Alleingang einen Bericht erstellen, der verschiedene Datenqualitätsmetriken in nur wenigen Sekunden kennzeichnet und nummeriert – selbst bei einer Stichprobengröße von 2 Millionen Datensätzen.
Die Leistung von DataMatch Enterprise bei einem Datensatz mit 2 Millionen Datensätzen wurde wie folgt aufgezeichnet:
Detaillierte Erstellung und Filterung von Datenqualitätsprofilen
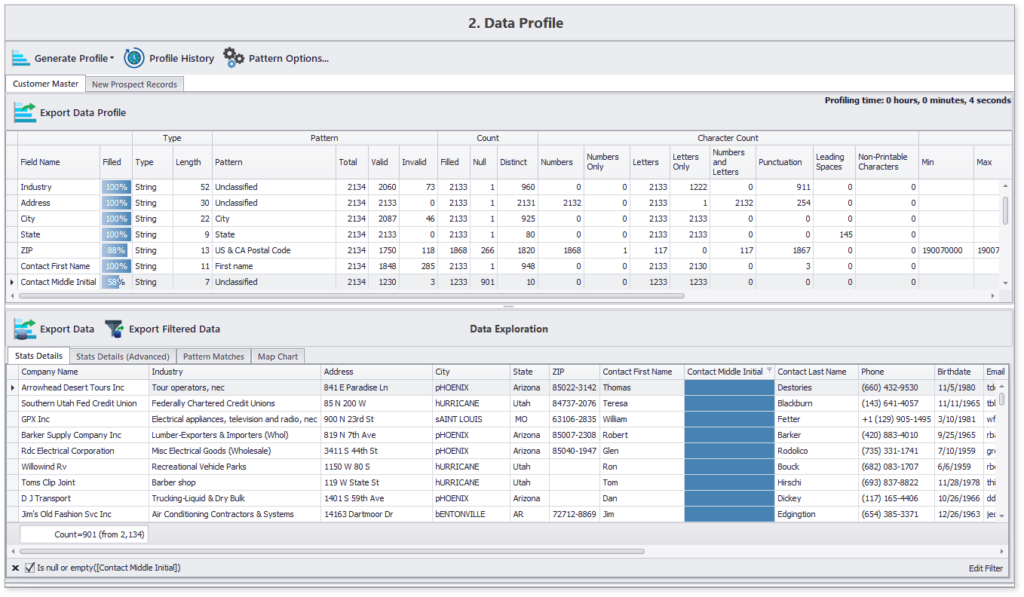
Hier ist ein Beispielprofil, das mit DME in weniger als 10 Sekunden für etwa 2000 Datensätze erstellt wurde:
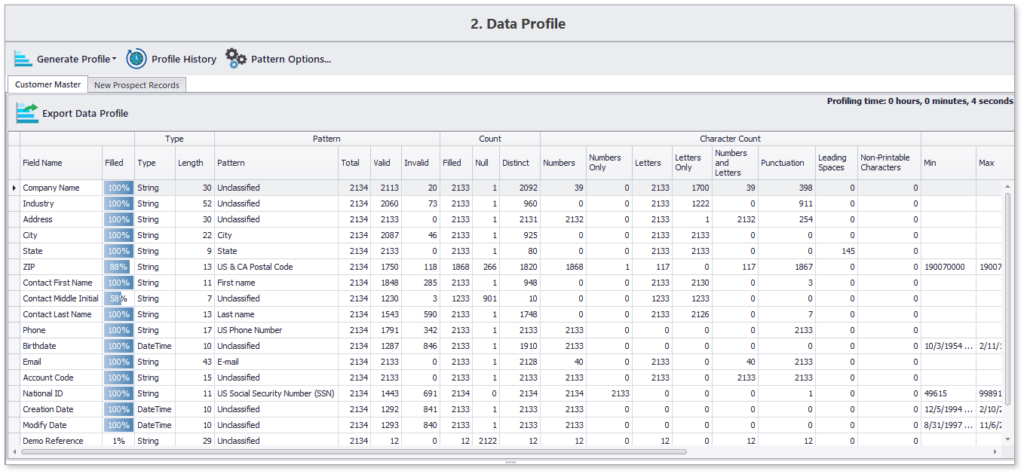
Dieses prägnante Datenprofil hebt den Inhalt und die Strukturdetails aller ausgewählten Datenattribute hervor. Darüber hinaus können Sie auch zu Besonderheiten navigieren, z. B. zur Liste der 12 % Datensätze, in denen der zweite Vorname des Kontakts fehlt.
Wenn Sie mehr darüber erfahren möchten, wie unsere Lösung zur Lösung Ihrer Datenqualitätsprobleme beitragen kann, melden Sie sich noch heute für eine kostenlose Testversion an oder vereinbaren Sie eine Demo mit einem unserer Experten.



