





























Last Updated on Januar 1, 2026
Schlechte Daten sind wohl die größte Herausforderung für Banken und große Finanzunternehmen.
Laut Ollie East, Direktor von Baker Tilly, gehen den US-Unternehmen aufgrund schlechter Datenqualität jährlich rund 3 Billionen Dollar verloren – und Banken sind da keine Ausnahme. Angesichts des astronomischen Datenwachstums sind die Finanzinstitute erheblichen Risiken ausgesetzt, z. B. in Bezug auf Finanzbetrug oder die Nichteinhaltung von Compliance-Standards. Die Ursache hierfür sind schlechte, unsaubere Daten, die sich in widersprüchlichen Kundenidentitäten und mangelnder Namensstandardisierung äußern.
Um Daten genau zu verarbeiten, Datensätze zu verknüpfen und redundante Einträge im Bankwesen zu entfernen, ist der unscharfe Namensabgleich ein beliebter Ansatz.
In diesem Beitrag wollen wir uns ansehen, warum Fuzzy-Matching-Logik für den Bankensektor so wichtig ist.
Die Landschaft des Bankensektors
Umfang der Daten
Auf der Makroebene müssen die Banken beträchtliche Datenmengen aus verschiedenen Kanälen wie Käufen an der Kasse, Geldautomaten, Online-Zahlungen und Kundenprofildaten überwachen.
Hinzu kommen mehrere Ebenen und Arten von Finanzdaten, die die Banken verwalten müssen: Zahlungen, Einkommen, Kredit, Kreditvergabe, Abschreibungen, Kontoverwaltung, Kreditvergabe gegen Wucher und vieles mehr. Alle diese Daten sind in der Regel in Silos angeordnet und produktorientiert (im Gegensatz zu kundenorientiert), was bedeutet, dass die Erlangung einer genauen, einheitlichen Sicht komplex ist.
Bankvorschriften
Banken müssen nicht nur Unmengen von Daten verwalten, sondern auch eine Reihe von Compliance-Vorschriften einhalten, die vom Federal Reserve Board, dem Office of the Comptroller of the Currency und anderen Behörden erlassen wurden. Dazu gehören:
- USA-Patriot-Gesetz
- AML (Anti-Geldwäsche)
- KYC (Know Your Customer)
- CFT-Verordnungen (Bekämpfung der Finanzierung des Terrorismus)
- BSA (Bank Secrecy Act) & Currency and Foreign Transactions Reporting Act und mehr
Daten-Herausforderungen
Im Laufe der Jahre haben Banken stark in die digitale Transformation, KI und Big Data investiert, um besser für den Umgang mit großen Datenmengen gerüstet zu sein. Dennoch gibt es zahlreiche Herausforderungen, wie z. B.:
- Veraltete oder überholte IT-Infrastruktur: Die Finanzdaten der Banken basieren immer noch auf veralteten Mainframe-Systemen, so dass mehr als 90 % der 100 größten Banken der Welt immer noch auf diese Systeme zurückgreifen. Dieses Problem wird noch dadurch verschärft, dass Unternehmen ihre Daten zwischen lokalen Systemen und Cloud-Anwendungen austauschen, da dies den Aufwand für Datenkonvertierungsinitiativen erhöht.
- 80 % der Bankdaten sind unstrukturiert: Im Gegensatz zu strukturierten Daten, die in einem relationalen Format gespeichert sind, das leichter zugänglich ist und mit dem man leichter arbeiten kann, sind unstrukturierte Daten – gespeichert als NoSQL-Datenbanken, Word-Dokumente, PDFs und E-Mails – viel schwieriger zu interpretieren und zu analysieren. Das Ergebnis ist, dass ein großer Teil der Daten ungenutzt bleibt, die sonst genutzt werden könnten, um die sich ändernden Kundenpräferenzen in Echtzeit zu verstehen und zu antizipieren.
- Mangel an geeigneten Technologien für die Bereinigung von Big Data: Banken nutzen die Open-Source-Plattform Hadoop, wie HBase, HDFS, Spark und viele andere. Die Aufnahme von Daten aus all diesen Systemen zusammen mit denen aus SQL-basierten Datenbanken ist jedoch nach wie vor eine Herausforderung, da es sich um disparate Datensilos handelt und die Deduplizierung und Entitätsauflösung von Milliarden von Datensätzen schwierig ist.
Schlechte Finanzdaten – ein großes Hindernis für Banken
Das Sprichwort „Daten sind das neue Öl“ ist wahr. Um jedoch sicherzustellen, dass Daten genauso wertvoll sind wie Öl, muss man die nötige Zeit und Mühe in die Konsolidierung, Profilierung, Analyse, Deduplizierung und Entitätsauflösung von Datensätzen investieren, um eine einzige Quelle der Wahrheit zu schaffen.
Banken müssen für eine Vielzahl von Vorschriften (insbesondere KYC) und Verwendungszwecken (FICO-Kreditwürdigkeitsprüfung, Vorhersage von Finanzausfällen) über Jahrzehnte hinweg aktuelle Kundeninformationen vorhalten, die, wenn sie nicht gepflegt werden, schnell korrupt oder veraltet werden können.
Außerdem ist es sehr wahrscheinlich, dass die von den Banken erhobenen Daten Anomalien enthalten, die auf manuelle Eingabefehler, vom System erzeugte Duplikate und vieles mehr zurückzuführen sind. Vor diesem Hintergrund ist es für Datenexperten von entscheidender Bedeutung, über Strategien zu verfügen, um Fehler rechtzeitig zu finden und zu beheben, bevor sie sich zu großen Geldwäscheskandalen und Kontroversen um Kreditkartenbetrug auswachsen.
Fuzzy Name Matching – Was ist das?
Fuzzy-Matching ist ein probabilistischer Matching-Algorithmus, der den Abgleich von zwei oder mehr Einträgen auf der Grundlage der Wahrscheinlichkeit ihrer Ähnlichkeit ermöglicht. Es unterscheidet sich deutlich vom deterministischen Abgleich, bei dem Übereinstimmungen auf der Grundlage einer „Ja“- oder „Nein“-Logik bei Vorhandensein einer eindeutigen Kennung wie Adresse, Sozialversicherungsnummer oder anderen Feldern identifiziert oder gekennzeichnet werden.
Der unscharfe Namensabgleich eignet sich am besten für Namensabfragen, um Übereinstimmungen mit einer Wahrscheinlichkeit von weniger als 100 % zu ermitteln, wenn kein eindeutiger Bezeichner vorhanden ist. Bei Banken kann es mehrere Varianten von Kundennamen in Form von:
- Rechtschreibfehler
- Abkürzungen
- Inkonsistentes Format für Vor-, Mittel- und Nachnamen
- Spitznamen
- Groß- und Kleinbuchstaben
- Akronyme
- Führende und abschließende Leerzeichen und mehr
Aus diesem Grund kann es mehrere Kundenidentitäten mit unterschiedlichen Namensvarianten geben. Die Banken können Daten sammeln, die mehrere Customer Journeys ein und desselben Kunden widerspiegeln, und am Ende ein schlechtes Kundenerlebnis bieten, mehr Zeit für die Identifizierung von Kundenkonten verschwenden und Einnahmen in Form von neuen Geschäftsmöglichkeiten verlieren.
Für weitere Informationen, lesen Sie bitte: Fuzzy Matching 101 Leitfaden.
Unscharfer Namensabgleich für Anwendungsfälle im Bankwesen
Der unscharfe Abgleich hat beträchtliche Anwendungsmöglichkeiten für die Identifizierung nicht exakter Übereinstimmungen, die Entfernung doppelter Datensätze in Big-Data-Anwendungen und die Lösung von Konflikten zwischen Entitäten. Auf diese Weise können kleine und große Finanzinstitute verschiedene Ziele erreichen, wie z. B.:
- Betrugsprävention: Der Fuzzy-Abgleich kann dazu beitragen, mehrere Kundenkonten abzugleichen und diejenigen zu identifizieren, die zu Unrecht Versicherungsansprüche angemeldet haben, um Betrug aufzudecken und den Verlust der Unternehmensreputation zu verhindern, wenn betrügerisches Verhalten nicht gemeldet wird.
- Kreditwürdigkeitsprüfung: Fuzzy-Algorithmen können es auch ermöglichen, die FICO-Kreditwürdigkeit seiner Kunden zu bestimmen, um die Risiken der Kreditvergabe an wichtige Kunden abzuwägen oder um Verluste durch uneinbringliche Forderungen zu ermitteln und zu minimieren.
- Kreditgenehmigung: Datensatzverknüpfung und Deduplizierung können Banken dabei helfen, die Kunden auszuwählen, die rechtmäßig einen Kredit erhalten, indem sie eindeutige IDs von Kunden erstellen und alle verstreuten Kundeninformationen in einer einzigen Ansicht konsolidieren.
Ist Fuzzy Name Matching effektiv genug?
Aufgrund des probabilistischen Charakters der Abgleichsalgorithmen ist der Fuzzy-Abgleich mit einer gewissen Ungenauigkeit und Unsicherheit behaftet. Je nach Stärke des Abgleichsalgorithmus kann die Fuzzy-Logik zu falschen Übereinstimmungen führen (falsch positiv) oder richtige Übereinstimmungen übersehen (falsch negativ).
Eine Möglichkeit, diese zu minimieren, besteht darin, ein umfassendes Datenprofil Ihrer Datenquellen zu erstellen, bevor Sie einen Abgleich vornehmen. In diesem Stadium kann die Profilerstellung der Daten das Ausmaß der fehlerhaften Daten aufzeigen, die weiter bereinigt werden können, um eine höhere Trefferquote zu erzielen. Für weitere Informationen, lesen Sie bitte: Die Bedeutung der Datenprofilierung für das Datenmanagement.
Wie DME Fuzzy Name Matching für Banking Anwendungsfälle
DataMatch Enterprise (DME) von Data Ladder ist ein Datenqualitäts-Tool, das eine unternehmenstaugliche Lösung für den unscharfen Namensabgleich nutzt, um Banken und Versicherungen bei der Suche nach nicht exakten Übereinstimmungen sowohl in Echtzeit als auch im Batch-Modus zu unterstützen.
Im Gegensatz zu anderen Fuzzy-Matching-Tools verfügt DME über vorgefertigte Spitznamenbibliotheken, die helfen, Datensätze mit ähnlichen Namen zu verknüpfen, um eine höhere Treffergenauigkeit zu erzielen, sowie Ebenen und Gewichtungen zuzuweisen, um falsch-positive und falsch-negative Ergebnisse zu minimieren.
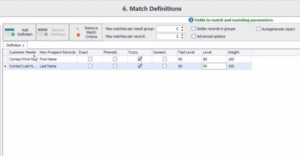
Wie oben gezeigt, können Sie bei DME zwischen unscharfem, phonetischem, exaktem und numerischem Abgleich wählen und den Schwellenwert ändern, um festzulegen, wie streng die Abgleichgenauigkeit sein soll, um falsch-positive und -negative Ergebnisse zu minimieren.
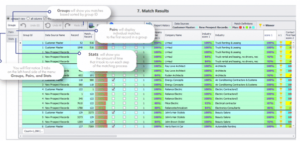
Sobald der Abgleich abgeschlossen ist, werden alle Ergebnisse entsprechend der jeweiligen Gruppe zusammen mit der Abgleichsbewertung gepaart, um die Identifizierung goldener Datensätze zu erleichtern.
Weitere Informationen zum Fuzzy-Namensabgleich für das Bankwesen finden Sie in unseren Lösungen für das Finanz- und Versicherungswesen oder laden Sie die Testversion herunter, um noch heute damit zu beginnen.

Wie die besten Fuzzy-Matching-Lösungen funktionieren: Kombination von bewährten und eigenen Algorithmen
Starten Sie noch heute Ihren kostenlosen Test



