





























Last Updated on janvier 1, 2026
Les données erronées constituent sans doute le défi le plus important auquel sont confrontées les banques et les grandes entreprises financières.
Selon Ollie East, directeur de Baker Tilly, les entreprises américaines perdent environ 3 000 milliards de dollars chaque année en raison de la mauvaise qualité des données – et les banques ne font pas exception. Avec la croissance astronomique des données, les institutions financières sont exposées à des risques considérables, tels que ceux liés à la fraude financière ou au non-respect des normes de conformité. À l’origine de cette situation, il y a des données médiocres et sales qui se manifestent par des identités de clients contradictoires et un manque de normalisation des noms.
Pour traiter les données avec précision, relier les enregistrements et dédupliquer les entrées redondantes dans le secteur bancaire, la correspondance floue des noms est une approche populaire.
Dans ce billet, nous allons voir pourquoi la logique d’appariement floue est vitale pour le secteur bancaire.
Le paysage de l’industrie bancaire
Champ d’application des données
Au niveau macro, les banques doivent superviser des quantités considérables de données provenant de multiples canaux tels que les achats aux points de vente, les guichets automatiques, les paiements en ligne et les données relatives au profil des clients.
À cela s’ajoutent plusieurs couches et types de données financières que les banques doivent conserver, concernant les paiements, les revenus, le crédit, les prêts, la dépréciation, l’administration des comptes, les prêts anti-usure, etc. Toutes ces données sont généralement organisées en silos et sont orientées vers le produit (par opposition au client), ce qui signifie qu’il est complexe d’obtenir une vue précise de l’entité unique.
Réglementation bancaire
Outre la gestion de tonnes de données, les banques doivent se conformer à toute une série de règles de conformité imposées par le Federal Reserve Board et l’Office of the Comptroller of the Currency, ainsi que par d’autres autorités. Il s’agit notamment de :
- USA Patriot Act
- AML (Anti Money Laundering)
- KYC (Know Your Customer)
- Règlement CFT (Counter Financing of Terrorism)
- BSA (Bank Secrecy Act) & Currency and Foreign Transactions Reporting Act et plus encore.
Défis en matière de données
Au fil des ans, les banques ont investi massivement dans la transformation numérique, l’IA et le Big Data afin d’être mieux équipées pour traiter de grandes quantités de données. Cependant, malgré cela, il existe de nombreux défis tels que :
- Infrastructure informatique dépassée ou obsolète : Les données financières des banques reposent toujours sur des systèmes mainframe obsolètes, à tel point que plus de 90 % des 100 premières banques mondiales s’en servent encore. Cette situation est aggravée par le fait que les entreprises transfèrent leurs données entre les systèmes sur site et les applications en nuage, ce qui accroît la pression sur les initiatives de conversion des données.
- 80 % des données bancaires sont non structurées : Contrairement aux données structurées qui sont stockées dans un format relationnel plus facile à consulter et à travailler, les données non structurées – stockées sous forme de bases de données NoSQL, de documents Word, de PDF et d’e-mails – sont beaucoup plus difficiles à interpréter et à analyser. Il en résulte qu’un grand nombre de données restent inutilisées alors qu’elles pourraient être exploitées pour comprendre et anticiper l’évolution des préférences des clients en temps réel.
- Manque de technologies adaptées au nettoyage des Big Data : Les banques utilisent les technologies de la plateforme open-source Hadoop telles que HBase, HDFS, Spark et bien d’autres. Cependant, l’ingestion de données provenant de tous ces systèmes ainsi que de bases de données SQL reste un défi en raison de la présence d’ensembles de données disparates en silo et de la difficulté à dédupliquer et à résoudre les entités de milliards d’enregistrements.
Des données financières médiocres – un obstacle majeur pour les banques
L’adage « les données sont le nouveau pétrole » est vrai. Mais pour s’assurer que les données sont une ressource aussi précieuse que le pétrole, il faut investir le temps et les efforts nécessaires à la consolidation, au profilage, à l’analyse, à la déduplication et à la résolution d’entités des enregistrements pour obtenir une source unique de vérité.
Les banques sont tenues de conserver des informations à jour sur leurs clients pour diverses réglementations (en particulier KYC) et utilisations (notation de crédit FICO, prédiction de faillite financière) pendant des décennies, qui, si elles ne sont pas prises en charge, peuvent rapidement devenir corrompues ou obsolètes.
En outre, les données collectées auprès des banques sont très susceptibles de contenir des anomalies résultant d’erreurs de saisie manuelle, de doublons créés par le système, et bien plus encore. Dans ce contexte, il est essentiel que les professionnels de l’informatique mettent en place des stratégies pour détecter et corriger rapidement les erreurs avant qu’elles ne se transforment en scandales de blanchiment d’argent et en controverses sur la fraude par carte de crédit.
Correspondance de noms flous – Qu’est-ce que c’est ?
La correspondance floue est un algorithme de correspondance probabiliste qui permet de faire correspondre deux ou plusieurs entrées sur la base de la probabilité de leur similarité. Elle diffère grandement de la correspondance déterministe dans laquelle les correspondances sont identifiées ou signalées sur la base d’une logique de « oui » ou de « non » en présence d’un identifiant unique tel que l’adresse, le SSN ou d’autres champs.
La correspondance floue de noms est la plus adaptée aux requêtes de noms pour identifier les correspondances avec une probabilité inférieure à 100 % lorsqu’aucun identifiant unique n’est présent. Il peut y avoir plusieurs variantes de noms de clients au sein des banques sous la forme de :
- Fautes d’orthographe
- Abréviations
- Format incohérent du prénom, du second prénom et du nom de famille
- Surnoms
- Majuscules et minuscules
- Acronymes
- Espaces de début et de fin de ligne, etc.
De ce fait, il peut y avoir plusieurs identités de client, chacune avec des variantes de nom différentes. Les banques peuvent collecter des données reflétant plusieurs parcours clients d’une même personne et finir par offrir une mauvaise expérience client, perdre plus de temps à identifier les comptes clients, perdre des revenus sous forme de nouvelles opportunités commerciales.
Pour plus d’informations, veuillez lire : Guide de l’appariement flou 101.
Correspondance floue de noms pour les cas d’utilisation bancaire
La correspondance floue a des applications considérables pour identifier les correspondances non exactes, supprimer les enregistrements en double dans les applications de données volumineuses et résoudre les problèmes d’entités contradictoires. Cela peut permettre aux institutions financières, petites et grandes, d’atteindre divers objectifs tels que :
- Prévention de la fraude : la correspondance floue peut aider à rapprocher plusieurs comptes clients et à identifier les personnes qui ont déposé à tort des demandes d’indemnisation afin de détecter les fraudes et d’éviter que la réputation de l’entreprise ne soit entachée par l’omission de signaler un comportement frauduleux.
- Credit scoring : les algorithmes flous peuvent également permettre de déterminer le score de crédit FICO de ses clients afin de peser les risques de prêter de l’argent à des clients clés ou d’identifier et de minimiser les pertes dues aux mauvaises créances.
- Approbation des prêts : lecouplage et la déduplication des enregistrements peuvent aider les banques à sélectionner les clients qui ont le droit de recevoir un prêt en créant des identifiants uniques pour les clients et en consolidant toutes les informations éparses sur les clients dans une vue unique.
La correspondance floue des noms est-elle suffisamment efficace ?
Étant donné la nature probabiliste de ses algorithmes de mise en correspondance, la mise en correspondance floue comporte un certain degré d’imprécision et d’incertitude. Selon la puissance de l’algorithme de mise en correspondance, la logique floue peut aboutir à des correspondances incorrectes (faux positifs) ou ne pas trouver de correspondances correctes (faux négatifs).
Une façon de les minimiser consiste à établir un profil complet de vos sources de données avant de procéder à tout type de rapprochement. À ce stade, le profilage des données peut révéler l’étendue des données erronées qui peuvent être nettoyées davantage pour obtenir un meilleur score de correspondance. Pour plus d’informations, veuillez lire : L’importance du profilage des données pour la gestion des données.
Comment DME utilise la correspondance floue de noms pour les cas d’utilisation bancaire
DataMatch Enterprise (DME) de Data Ladder est un outil de qualité des données qui utilise une solution de correspondance floue des noms de niveau entreprise pour aider les banques et les compagnies d’assurance à trouver des correspondances non exactes en temps réel et en mode batch.
Contrairement à d’autres outils de correspondance floue, DME est livré avec des bibliothèques de surnoms pré-construites pour aider à relier les enregistrements avec des approximations de noms proches pour une plus grande précision de correspondance et l’attribution de niveaux et de poids pour minimiser les faux positifs et les faux négatifs.
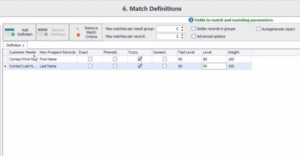
Comme indiqué ci-dessus, les niveaux de DME vous permettent de choisir entre une correspondance floue, phonétique, exacte et numérique et de modifier le niveau de seuil pour contrôler le degré de précision de la correspondance afin de minimiser les faux positifs et négatifs.
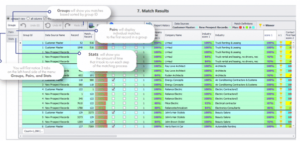
Une fois l’appariement effectué, tous les résultats sont mis en parallèle selon chaque groupe avec le score d’appariement pour aider à identifier les enregistrements en or.
Pour plus d’informations sur la correspondance de noms flous pour le secteur bancaire, consultez nos solutions pour la finance et l’assurance ou téléchargez l’essai pour commencer dès aujourd’hui.

Comment fonctionnent les meilleures solutions de correspondance floue de leur catégorie : Combinaison d’algorithmes établis et exclusifs
Commencez votre essai gratuit aujourd’hui



