




























Last Updated on enero 1, 2026
Los datos erróneos son sin duda el reto más importante al que se enfrentan los bancos y las grandes empresas financieras.
Según el director de Baker Tilly, Ollie East, las empresas estadounidenses pierden alrededor de 3 billones de dólares cada vez debido a la mala calidad de los datos, y los bancos no son una excepción. A medida que los datos crecen de forma astronómica, las instituciones financieras se exponen a riesgos considerables, como los relacionados con el fraude financiero o el incumplimiento de las normas de conformidad. La raíz de todo esto son los datos pobres y sucios que se manifiestan en las identidades conflictivas de los clientes y la falta de estandarización de los nombres.
Para procesar los datos con precisión, vincular los registros y desduplicar las entradas redundantes en la banca, la concordancia difusa de nombres es un enfoque popular.
En este post, vamos a ver por qué la lógica de concordancia difusa es vital para el sector bancario.
El panorama del sector bancario
Alcance de los datos
A nivel macro, los bancos deben supervisar cantidades considerablemente grandes de datos procedentes de múltiples canales, como las compras en los puntos de venta, los cajeros automáticos, los pagos en línea y los datos del perfil de los clientes.
Además, hay varios niveles y tipos de datos financieros que los bancos deben mantener en relación con los pagos, los ingresos, el crédito, los préstamos, la depreciación, la administración de cuentas, los préstamos contra la usura, etc. Todos estos datos suelen estar organizados en silos y están orientados a los productos (en lugar de a los clientes), lo que significa que obtener una visión precisa y de entidad única es complejo.
Normativa bancaria
Además de gestionar toneladas de datos, los bancos tienen que cumplir una serie de normas de cumplimiento impuestas por la Junta de la Reserva Federal y la Oficina del Interventor de la Moneda y otras autoridades. Entre ellas se encuentran:
- Ley Patriótica de EE.UU.
- AML (Anti Blanqueo de Capitales)
- KYC (Conozca a su cliente)
- Normativa de lucha contra la financiación del terrorismo (CFT)
- BSA (Ley de Secreto Bancario) y Ley de Información sobre Divisas y Transacciones Extranjeras, entre otras.
Desafíos de los datos
A lo largo de los años, los bancos han invertido mucho en transformación digital, IA y Big Data para estar mejor equipados para manejar grandes cantidades de datos. Sin embargo, a pesar de ello, existen numerosos retos como:
- Infraestructura informática anticuada u obsoleta: Los datos financieros de los bancos siguen basándose en sistemas mainframe heredados y obsoletos, hasta el punto de que más del 90% de los 100 principales bancos del mundo siguen confiando en ellos. Esta situación se ve agravada por el hecho de que las empresas cambien los datos entre los sistemas locales y las aplicaciones en la nube, ya que supone una mayor carga para las iniciativas de conversión de datos.
- El 80% de los datos bancarios no están estructurados: A diferencia de los datos estructurados que se almacenan en un formato relacional al que es más fácil acceder y trabajar, los datos no estructurados -almacenados como bases de datos NoSQL, documentos de Word, PDF y correos electrónicos- son mucho más difíciles de interpretar y analizar. Como resultado, una gran cantidad de datos permanece inactiva que, de otro modo, podría aprovecharse para comprender y anticipar los cambios en las preferencias de los clientes en tiempo real.
- Falta de tecnologías adecuadas para la limpieza de Big Data: Los bancos utilizan tecnologías de plataformas de código abierto Hadoop como HBase, HDFS, Spark y muchas más. Sin embargo, la ingesta de datos de todos estos sistemas junto con los de las bases de datos basadas en SQL sigue siendo un reto debido a la presencia de conjuntos de datos dispares y a la dificultad de deduplicar y resolver las entidades de miles de millones de registros.
Datos financieros deficientes: un gran obstáculo para los bancos
El adagio «los datos son el nuevo petróleo» es cierto. Pero asegurarse de que los datos son un recurso tan valioso como el petróleo requiere invertir el tiempo y el esfuerzo necesarios para consolidar, perfilar, analizar, deduplicar y resolver los registros de entidades para obtener una única fuente de verdad.
Los bancos están obligados a mantener actualizada la información de los clientes para una serie de normativas (sobre todo la de CSC) y casos de uso (puntuación de crédito FICO, predicción de quiebras financieras) durante décadas que, si no se cuidan, pueden corromperse u obsoletos rápidamente.
Además, es muy probable que los datos recogidos de los bancos contengan anomalías derivadas de errores de introducción manual, de la creación de duplicados por parte del sistema, etc. Teniendo esto en cuenta, es vital que los profesionales de los datos dispongan de estrategias para encontrar y corregir a tiempo los errores antes de que se conviertan en grandes escándalos de blanqueo de dinero y controversias de fraude con tarjetas de crédito.
Coincidencia de nombres difusa – ¿Qué es?
El emparejamiento difuso es un algoritmo de emparejamiento probabilístico que permite emparejar dos o más entradas en función de la probabilidad de que sean similares. Difiere en gran medida de la concordancia determinista, en la que las coincidencias se identifican o marcan basándose en una lógica de «sí» o «no» en presencia de un identificador único como la dirección, el SSN u otros campos.
La concordancia difusa de nombres es la más adecuada para que las consultas de nombres identifiquen coincidencias con una probabilidad inferior al 100% cuando no hay un identificador único. Puede haber múltiples variantes de nombres de clientes dentro de los bancos en forma de:
- Errores ortográficos
- Abreviaturas
- Formato incoherente del nombre, el segundo nombre y los apellidos
- Apodos
- Mayúsculas y minúsculas
- Acrónimos
- Espacios iniciales y finales y más
Debido a esto, puede haber múltiples identidades de clientes, cada una con diferentes variantes de nombre. Los bancos pueden recopilar datos que reflejen múltiples recorridos de los clientes de un mismo individuo y acabar ofreciendo una mala experiencia al cliente, perdiendo más tiempo en la identificación de las cuentas de los clientes y perdiendo ingresos en forma de nuevas oportunidades de negocio.
Para más información, lea: Guía Fuzzy Matching 101.
Comparación de nombres difusa para casos de uso bancario
La concordancia difusa tiene aplicaciones considerables para identificar coincidencias no exactas, eliminar registros duplicados en aplicaciones de big data y resolver retos de entidades conflictivas. Esto puede permitir a las pequeñas y grandes instituciones financieras cumplir varios objetivos previstos, como:
- Prevención del fraude: el cotejo difuso puede ayudar a conciliar las cuentas de varios clientes e identificar a aquellos que han presentado reclamaciones de seguros de forma errónea para detectar el fraude y evitar la pérdida de la reputación de la empresa al no denunciar comportamientos fraudulentos.
- Puntuación de crédito: los algoritmos difusos también pueden permitir determinar la puntuación FICO de crédito de sus clientes para sopesar los riesgos de prestar dinero a clientes clave o para identificar y minimizar las pérdidas por deudas incobrables.
- Aprobación de préstamos: lavinculación y deduplicación de registros puede ayudar a los bancos a seleccionar a los clientes que tienen derecho a recibir un préstamo mediante la creación de identificaciones únicas de los clientes y la consolidación de toda la información dispersa de los clientes en una sola vista.
¿Es suficientemente eficaz la concordancia de nombres difusa?
Dada la naturaleza probabilística de sus algoritmos de emparejamiento, el emparejamiento difuso tiene un grado de inexactitud e incertidumbre. Dependiendo de la fuerza del algoritmo de coincidencia, la lógica difusa puede acabar produciendo coincidencias incorrectas (falsos positivos) o no encontrar coincidencias correctas (falsos negativos).
Una forma de minimizarlos es crear un perfil de datos completo de sus fuentes de datos antes de realizar cualquier tipo de cotejo. En esta fase, el perfil de los datos puede revelar el alcance de los datos defectuosos que pueden limpiarse más para obtener una mayor puntuación de coincidencia. Para más información, lea: La importancia de la elaboración de perfiles de datos para la gestión de datos.
Cómo utiliza el ISD la concordancia difusa de nombres para casos de uso bancario
DataMatch Enterprise (DME) de Data Ladder ofrece una herramienta de calidad de datos que utiliza una solución de correspondencia de nombres difusa de nivel empresarial para ayudar a los bancos y las compañías de seguros a encontrar coincidencias no exactas tanto en tiempo real como en modo batch.
A diferencia de otras herramientas de concordancia difusa, el ISD viene con bibliotecas de apodos preconstruidas para ayudar a enlazar registros con aproximaciones de nombres cercanas para una mayor precisión de concordancia y asignar niveles y pesos para minimizar los falsos positivos y los falsos negativos.
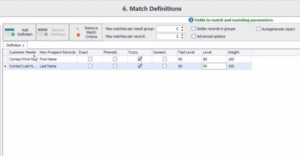
Como se muestra arriba, en los niveles del ISD se puede seleccionar entre coincidencias difusas, fonéticas, exactas y numéricas y cambiar el nivel de umbral para controlar el grado de exigencia de la precisión de la coincidencia para minimizar los falsos positivos y negativos.
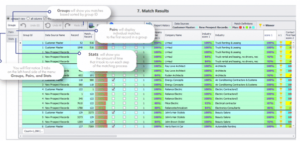
Una vez realizado el cotejo, todos los resultados se emparejan según cada grupo junto con la puntuación de cotejo para ayudar a identificar los registros dorados.
Para obtener más información sobre la concordancia de nombres difusa para el sector bancario, consulte nuestras soluciones de finanzas y seguros o descargue la prueba para empezar hoy mismo.

Cómo funcionan las mejores soluciones de concordancia difusa de su clase: Combinando algoritmos establecidos y propios
Inicie su prueba gratuita hoy mismo



