































Last Updated on December 9, 2025
In 2023, businesses lost an average of 31% of revenue due to bad data. It wasn’t the first time – poor data quality continues to plague organizations of all sizes across every industry. But the stakes are much higher in some. The finance sector is one of them. Imagine a bank approving a loan to a fraudster because its system couldn’t connect their multiple aliases, or missing red flags on compliance violations due to conflicting customer identities. These scenarios aren’t just hypothetical – they’re the real, costly consequences of unresolved name matching challenges.
Despite investing heavily in digital transformation, banks often fall short when it comes to managing customer identity data. This is where fuzzy name matching can be a game changer. A powerful tool for reconciling data discrepancies, fuzzy name matching can help financial institutions prevent frauds, streamline customer experiences, and also ensure compliance on their part.
The Banking Industry Landscape
Scope of Data
Banks manage an extraordinary volume of data originating from multiple channels, such as point-of-sale purchases, ATMs, online payments, and customer profile information. In addition, financial institutions must handle several layers and types of complex datasets related to payments, income, credit, loans, depreciation, account administration, anti-usury lending, and more. What makes it challenging is that much of this data (if not all) is usually stored in silos and organized around products rather than customers. This fragmented structure makes it challenging to achieve a unified, accurate view of customer identities, which is a critical requirement for informed decision-making and risk mitigation.
Banking Regulations
In addition to the challenges of data volume and complexity, banks are required to comply with a range of compliance regulations. These are mandated by the Federal Reserve Board, the Office of the Comptroller of the Currency and other authorities to ensure transparency and prevent fraud. Key regulations include:
- USA Patriot Act
- Anti-Money Laundering (AML)
- Know Your Customer (KYC)
- Counter Financing of Terrorism (CFT)
- Bank Secrecy Act (BSA) and the Currency and Foreign Transactions Reporting Act
And more.
Failure to comply with these regulations can result in heavy fines, reputational damage, and increased scrutiny from regulatory bodies.
Data Challenges
Over the years, banks have invested heavily in digital transformation, AI, and Big Data tools to become better equipped to deal with vast amounts of data they have. However, despite this, they face numerous challenges that hinder efficient data management. These include:
1. Outdated or Obsolete IT Infrastructure
Banks still rely heavily on legacy systems, so much so that research shows 45 out of top 50 banks use mainframe as their core platform. The challenges these outdated systems pose are further compounded by enterprises switching data between on-premise systems and cloud applications, as it places greater strain on data conversion and integration initiatives.
2. Unstructured Data
About 80% of banking data is unstructured. Unlike structured data that is stored in a relational format that is easier to access and work with, unstructured data is stored as NoSQL databases, Word documents, PDFs, and emails and is far more difficult to access, interpret, and analyze. As a result, a large chunk of data sits idle that can otherwise be tapped into to understand and anticipate changing customer preferences in real-time.
3. Lack of Technologies Suited for Cleaning Big Data
Banks use Hadoop open-source platform technologies such as HBase, HDFS, Spark and many more. However, ingesting data from all these systems along with that from SQL-based databases remains a challenge due to the presence of disparate siloed datasets and the difficulty in deduplicating and entity resolving billions of records.
Why Poor Data is a Major Obstacle for Banks
The phrase “data is the new oil” holds absolutely true for the finance industry. But for data to deliver its promised value, it must be accurate, consolidated, and up to date.
Banks are required to maintain comprehensive and up-to-date customer records for decades to meet compliance standards, particularly KYC, and to support use-cases like FICO credit scoring and predicting financial failure. over the span of decades. If not taken care of, this data can quickly become corrupt or obsolete.
Unfortunately, the data collected from banks is very likely to contain anomalies resulting from manual entry errors, system creating duplicates, outdated information and much more. Keeping this in view, it is vital for data professionals to have strategies in place to timely find and fix errors before it snowballs into major money laundering scandals and credit card fraud controversies.
Fuzzy Name Matching – What is it?
Fuzzy matching is a probabilistic matching algorithm designed to compare and link records based on similarity, even when they don’t match exactly. Unlike deterministic matching, which operates on a strict “yes” or “no” logic using unique identifiers like Social Security Numbers or addresses, fuzzy matching algorithms assess the likelihood of a match when unique identifiers are missing or inconsistent.
This approach is particularly effective for resolving different name matching challenges, which are common in banking systems. Customer names can appear in various forms in banks’ records due to:
- Misspellings or spelling variations
- Abbreviations
- Inconsistent first, middle, and last name format
- Nicknames
- Upper case and lower case differences
- Acronyms
- Leading and trailing spaces, etc.
These issues often lead to fragmented customer identities, where a single individual is represented by multiple records within a bank’s system. As a result:
- Customer Experience Declines: When customer data is scattered across multiple records, banks may collect data reflecting multiple customer journeys of the same individual and, as a result, struggle to provide seamless services.
- Operational Inefficiencies Increase: More time and resources are spent trying to reconcile customer account manually.
- Lost Revenue Opportunities: Inaccurate data can hinder cross-selling, upselling, and other growth initiatives or new business prospects, all of which eventually culminate as lost revenue opportunities.
Fuzzy name matching offers a robust solution to address these (and several other) challenges. By reconciling data inconsistencies, fuzzy matching techniques help banks improve customer satisfaction, streamline operations, and uncover new revenue opportunities.
For more information on this matching process, please read our Fuzzy Matching 101 Guide.
Fuzzy Name Matching for Banking Use-Cases
Fuzzy matching has numerous transformative applications in finance. It enables institutions to identify non-exact matches, eliminate duplicate records across big data applications, and resolve conflicting entity challenges across complex systems. This helps financial institutions (both large and small) to achieve various critical objectives such as:
1. Fraud Prevention
Fuzzy matching algorithms can detect discrepancies across multiple customer records to identify fraudsters who exploit system inconsistencies. For example, by reconciling multiple aliases, name variations, or possible spelling variations, banks can uncover wrongfully filed insurance claims and unauthorized account activities. This enables them to prevent damage to their corporate reputation by ensuring fraudulent behavior is flagged and addressed.
2. Credit Scoring
Banks can use fuzzy matching algorithms to consolidate customer data and generate accurate FICO credit scores. By identifying and linking disparate data points for the same individual, financial institutions can better assess creditworthiness, mitigate the risks of lending, and minimize losses from bad debts.
3. Loan Approval
Fuzzy name matching streamlines the process of loan approval by resolving fragmented customer identities. Techniques like record linkage and deduplication can help banks to select customers who are rightfully entitled to receiving a loan by creating unique IDs of customers and consolidating all scattered customer information under a single view. This also helps reduce delays caused by duplicate or incomplete records.
Is Fuzzy Name Matching Effective Enough?
While fuzzy name matching is a powerful tool, its probabilistic nature introduces a degree of inaccuracy and uncertainty. The algorithm’s reliance on similarity scoring introduces the risk of false positives (incorrect matches) or false negatives (missed matches). These inaccuracies can lead to inefficiencies, such as misidentifying customers or overlooking key connections within datasets.
A way to minimize these risks is to build a comprehensive data profile of your data sources before doing any kind of matching. At this stage, profiling the data can reveal the extent of faulty data that can be further cleansed to give a higher match score.
For a deeper dive into this critical step, please read our guide The Importance of Data Profiling for Data Management.
How DME Utilizes Fuzzy Name Matching for Banking Use-Cases
Data Ladder’s DataMatch Enterprise (DME) offers a data quality tool that makes use of enterprise-grade fuzzy name matching solution to help banks and insurance companies identify non-exact matches in both real-time and batch processing mode.
What sets DME apart from other solutions is its prebuilt nickname libraries and customizable algorithms. These features enhance accuracy by linking records with close name approximations and enabling users to assign weights and thresholds, thereby, reducing the likelihood of false positives and false negatives.
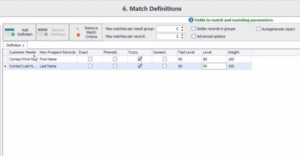
Flexible Matching Options
DME provides multiple matching levels – including fuzzy, phonetic, exact, and numeric – to give users precise control over the matching process. As shown above, you can adjust the threshold level to control how stringent you want the matching accuracy to be to minimize false positives and negatives and get optimal results for even the most complex data sets.
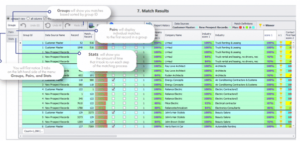
Delivering Golden Records
Once the matching is done, DME pairs the results according to each group along with the matching score to help organizations identify golden records – the most accurate and complete representation of an entity.
For more information on fuzzy name matching for banking industry, check out our finance and insurance solutions or download your free trial to get started today.

How best in class fuzzy matching solutions work: Combining established and proprietary algorithms

