







































DME allows you to prepare your data before deduping it, which involves advanced data profiling , cleansing, and standardization. With DME, you can execute the necessary steps to ensure deduplication accuracy, such as pattern recognition, word replacement, letter case transformation, and address standardization.
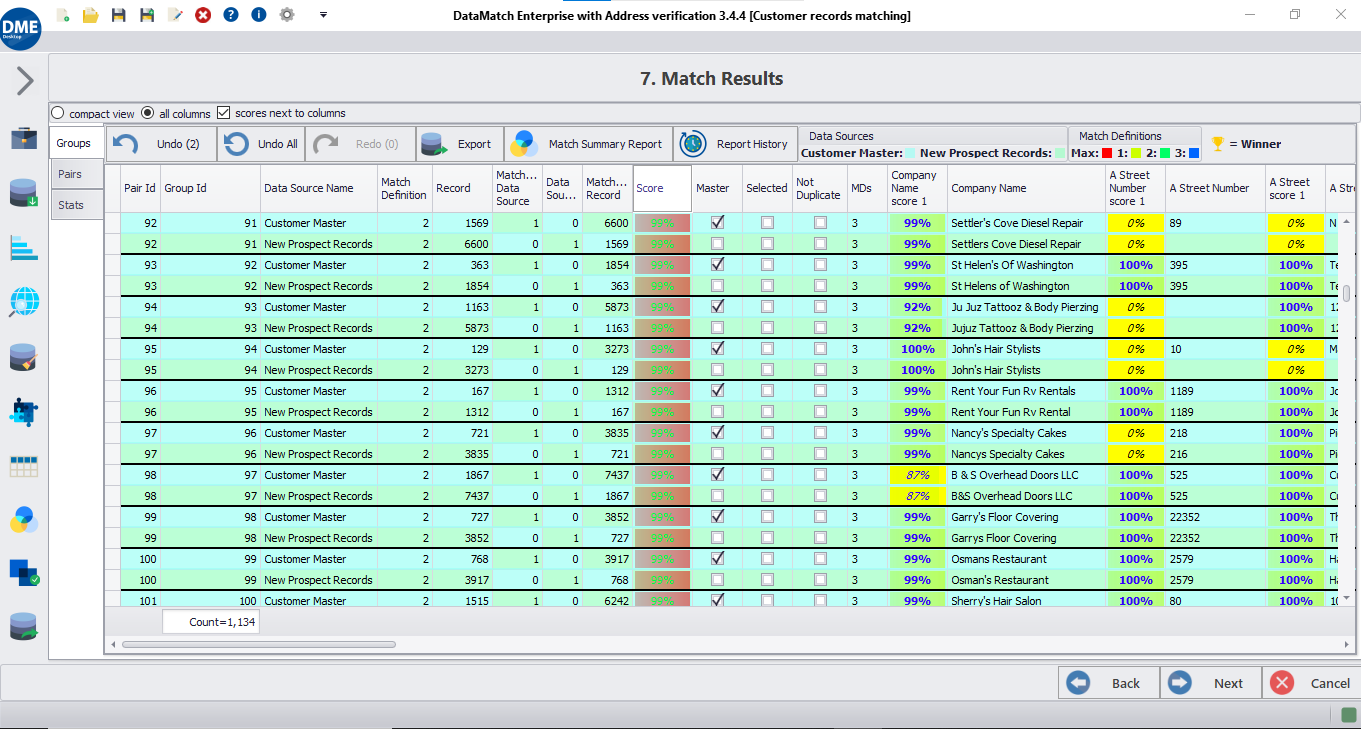
DME leverages advanced field and record matching techniques that consider misspellings, human typographical errors, and conventional variations in data values. DME can assess similarity between records right down to the character level. Moreover, advanced fuzzy matching techniques are also used to compare words and long sentences.

Data analysts

Business users

IT Professionals

Novice users


Merging Data from Multiple Sources – Challenges and Solutions

Deterministic vs. Probabilistic Matching: When to Choose Each Data Matching Type
Last Updated on July 30, 2026 Deterministic matching links two records only when specified fields agree exactly, like an identical account number. Probabilistic matching links
Best Data Deduplication Software for Enterprise Data: A Record-Level Comparison (2026)
Last Updated on July 30, 2026 Quick Verdict The best data deduplication software depends on where duplicate records exist, how many systems must be reconciled,
Deterministic vs. Probabilistic Matching: When to Choose Each Data Matching Type
Last Updated on July 30, 2026 Deterministic matching links two records only when specified fields agree exactly, like an identical account number. Probabilistic matching links
Best Data Deduplication Software for Enterprise Data: A Record-Level Comparison (2026)
Last Updated on July 30, 2026 Quick Verdict The best data deduplication software depends on where duplicate records exist, how many systems must be reconciled,
9 Best Fuzzy Matching Software for Data Teams in 2026
Last Updated on July 30, 2026 Quick Verdict The best fuzzy matching tool depends on the scale of the project, data sources, and technical resources
