




























Last Updated on febrero 9, 2022
En este blog, analizaremos en profundidad la concordancia difusa, el enfoque más utilizado para la deduplicación de datos y la vinculación de registros. Cubriremos:
- ¿Qué es el Fuzzy Matching?
- ¿Por qué las empresas necesitan la concordancia difusa?
- Ejemplo de un escenario de coincidencia difusa en el mundo real
- Técnicas de concordancia difusa
- Ventajas y desventajas de la concordancia difusa
- Cómo minimizar los falsos positivos y negativos
- Scripts de emparejamiento difuso frente a software de emparejamiento difuso: ¿Cuál es mejor?
- Cómo ejecutar Fuzzy Matching en DataMatch Enterprise
¿Qué es el Fuzzy Matching?
En lugar de marcar los registros como «coincidentes» o «no coincidentes», la concordancia difusa identifica la probabilidad de que dos registros sean realmente coincidentes en función de si coinciden o no en los distintos identificadores.
Los identificadores o parámetros que se eligen aquí y el peso que se asigna constituyen la base de la correspondencia difusa. Si los parámetros son demasiado amplios, se encontrarán más coincidencias, es cierto, pero también aumentarán invariablemente las posibilidades de «falsos positivos». Se trata de pares que el algoritmo o el software de concordancia difusa de su elección identifican como coincidentes, pero al revisarlos manualmente, descubrirá que su enfoque identificó un falso positivo.
Considere las cadenas «Kent» y «10th«. Aunque es evidente que no hay ninguna coincidencia, los algoritmos populares de coincidencia difusa siguen calificando estas dos cadenas de casi un 50% de similitud, basándose en el recuento de caracteres y la coincidencia fonética. Compruébelo usted mismo.
Los falsos positivos son uno de los mayores problemas de las coincidencias difusas. Cuanto más eficiente sea el sistema que utilices, menos falsos positivos habrá. Un sistema eficiente identificará:
- Acrónimos
- inversión del nombre
- variaciones de nombre
- grafías fonéticas
- errores ortográficos deliberados
- errores ortográficos involuntarios
- abreviaturas, por ejemplo, «Ltd» en lugar de «Limited».
- inserción/eliminación de signos de puntuación, espacios y caracteres especiales
- Diferentes grafías de los nombres, por ejemplo, «Elisabeth» o «Elizabeth», «Jon» en lugar de «John».
- nombres acortados, por ejemplo, «Elizabeth» coincide con «Betty», «Beth», «Elisa», «Elsa», «Beth», etc.
Y muchas otras variaciones.
¿Por qué las empresas necesitan la concordancia difusa?
Los estudios revelan que el 94% de las empresas admiten tener datos duplicados, y la mayoría de estos duplicados no son exactos y, por tanto, suelen pasar desapercibidos. El software de cotejo difuso le ayuda a establecer esas conexiones de forma automática mediante una sofisticada lógica de cotejo propia, independientemente de los errores ortográficos, los datos no estandarizados o la información incompleta.
Pero no se trata sólo de la deduplicación. Desde un punto de vista estratégico, el fuzzy matching entra en juego cuando se realiza la vinculación de registros o la resolución de entidades. En la sección anterior también hemos hablado brevemente de esto; el enfoque de coincidencia difusa es muy valioso cuando se crea una Fuente Única de la Verdad para el análisis empresarial o se construye una base para la Gestión de Datos Maestros (MDM), lo que ayuda a las organizaciones a integrar datos de docenas de fuentes diferentes en toda la empresa, al tiempo que garantiza la precisión y minimiza la revisión manual. Vea cómo un importante proveedor de servicios sanitarios pudo ahorrar cientos de horas de trabajo al año.
Estas son algunas de las formas en que se utiliza el fuzzy matching para mejorar el resultado final:
- Realice una visión única del cliente
- Trabaje con datos limpios en los que pueda confiar
- Preparar los datos para la inteligencia empresarial
- Mejore la precisión de sus datos para una mayor eficiencia operativa
- Enriquecer los datos para profundizar en la información
- Garantizar un mejor cumplimiento
- Afinar la segmentación de los clientes
- Mejorar la prevención del fraude
Más información sobre las ventajas de la concordancia difusa.
Ejemplo de un escenario de coincidencia difusa en el mundo real
El siguiente ejemplo muestra cómo las técnicas de vinculación de registros pueden utilizarse para detectar el fraude, el despilfarro o el abuso de los programas del gobierno federal. En este caso, se fusionaron dos bases de datos para obtener información que antes no estaba disponible en una sola base de datos.
Se cotejó una base de datos formada por registros de 40.000 pilotos de avión con licencia de la Administración Federal de Aviación (FAA) de EE.UU. y residentes en el norte de California con una base de datos formada por personas que reciben pagos por discapacidad de la Administración de la Seguridad Social. Cuarenta pilotos cuyos registros aparecieron en ambas bases de datos fueron detenidos.
Un fiscal de la Oficina del Fiscal de los Estados Unidos en Fresno, California, declaró, según un informe de AP:
«Probablemente hubo un ilícito penal». Los pilotos estaban mintiendo a la FAA o recibiendo beneficios indebidamente. Los pilotos afirmaban ser médicamente aptos para volar aviones. Sin embargo, es posible que hayan volado con enfermedades debilitantes que deberían haberlos mantenido en tierra, desde la esquizofrenia y el trastorno bipolar hasta la adicción a las drogas y el alcohol y las afecciones cardíacas».
Al menos doce de estas personas «tenían licencias comerciales o de transporte aéreo», según el informe. La FAA revocó 14 licencias de piloto. Se descubrió que los otros pilotos mentían sobre sus enfermedades para poder cobrar la Seguridad Social.
La calidad de la vinculación de los expedientes dependía en gran medida de la calidad de los nombres y direcciones de los pilotos con licencia dentro de los dos expedientes vinculados. La detección del fraude también dependía de la integridad y exactitud de la información de una base de datos concreta de la Administración de la Seguridad Social.
Vea cómo las empresas de su sector utilizan hoy la concordancia difusa.
Técnicas de concordancia difusa
Ahora ya sabe lo que es el fuzzy matching y las diferentes maneras en que puede utilizarlo para hacer crecer su negocio. La pregunta es, ¿cómo se implementan los procesos de emparejamiento difuso en su organización?
A continuación se presenta una lista de las distintas técnicas de concordancia difusa que se utilizan en la actualidad:
- Distancia de Levenshtein (o distancia de edición)
- Distancia Damerau-Levenshtein
- Distancia Jaro-Winkler
- Distancia del teclado
- Distancia Kullback-Leibler
- Índice de Jaccard
- Metáfono 3
- Nombre Variante
- Alineación de sílabas
- Acrónimo
Obtenga más información sobre los algoritmos de coincidencia difusa.
Ventajas y desventajas de la concordancia difusa
Dado que el emparejamiento difuso se basa en un enfoque probabilístico para la identificación de coincidencias, puede ofrecer una amplia gama de ventajas, como:
– Mayor precisión de las coincidencias: la coincidencia difusa resulta ser un método mucho más preciso para encontrar coincidencias entre dos o más conjuntos de datos. A diferencia de la concordancia determinista, que determina las coincidencias sobre una base de 0 o 1, la concordancia difusa puede detectar variaciones que se encuentran entre una base de 0 y 1 en un umbral de concordancia dado.
–Proporciona soluciones a datos complejos:la lógica difusa también permite a los usuarios encontrar coincidencias mediante la vinculación de registros que constan de ligeras variaciones en forma de errores de ortografía, mayúsculas y formato, valores nulos, etc., lo que la hace más adecuada para aplicaciones del mundo real en las que pueden producirse errores tipográficos, de sistema y otros errores de datos. Esto incluye también los datos dinámicos que se vuelven obsoletos o que deben actualizarse constantemente, como el cargo y la dirección de correo electrónico.
–Fácilmente configurable para efectuar falsos positivos: cuando el número de falsos positivos debe reducirse o aumentarse para adaptarse a las necesidades de la empresa, los usuarios pueden ajustar fácilmente el umbral de coincidencia para manipular los resultados o tener más coincidencias para la inspección manual. Esto ofrece a los usuarios una mayor flexibilidad a la hora de adaptar los algoritmos de lógica difusa a los requisitos específicos de coincidencia.
– Más adecuado para encontrar coincidencias sin un identificador único consistente: disponer de datos de identificación únicos, como el SSN o la fecha de nacimiento, es fundamental para encontrar coincidencias entre fuentes de datos dispares en el caso de las coincidencias deterministas. Sin embargo, utilizando un enfoque de análisis estadístico, la coincidencia difusa puede ayudar a encontrar duplicados incluso sin datos de identificación consistentes.
Sin embargo, el emparejamiento difuso no está exento de limitaciones. Entre ellas se encuentran:
– Puede vincular incorrectamente entidades diferentes: a pesar de la configurabilidad disponible en la concordancia difusa, los altos falsos positivos debidos a la vinculación incorrecta de entidades aparentemente similares pero diferentes pueden llevar a gastar más tiempo en la comprobación manual de duplicados con identificadores únicos.
– Dificultad para escalar a través de grandes conjuntos de datos: la lógica difusa puede ser difícil de escalar a través de millones de puntos de datos, especialmente en el caso de fuentes de datos dispares.
– Puede requerir considerables pruebas para su validación: las reglas definidas en los algoritmos deben ser constantemente refinadas y probadas para asegurar que es capaz de ejecutar partidos con alta precisión.
Cómo minimizar los falsos positivos y negativos
En la sección anterior hemos hablado brevemente de los falsos positivos. Aunque dificultan el cotejo al añadir tiempo de revisión manual al proceso, no suponen un verdadero riesgo para la empresa, ya que el sistema marcará los falsos positivos en función de la puntuación global de cotejo. Veamos ahora los «falsos negativos». Esto se refiere a los partidos que el sistema pasa por alto por completo: no sólo una puntuación baja del partido, sino una ausencia de puntuación del partido. Esto supone un grave riesgo para la empresa, ya que los falsos negativos nunca se revisan porque nadie sabe que existen. Entre los factores que suelen dar lugar a falsos negativos se encuentran:
- Falta de datos relevantes
- Errores significativos en la introducción de datos
- Limitaciones del sistema
- El criterio de coincidencia es demasiado estrecho
- Nivel inadecuado de coincidencia difusa
El método más eficaz para minimizar tanto los falsos positivos como los negativos es perfilar y limpiar las fuentes de datos por separado antes de realizar el cotejo. Los principales proveedores de soluciones de cotejo de datos suelen incluir un perfilador de datos que proporciona rápidamente suficientes metadatos para construir un análisis de perfil convincente de la calidad de los datos, como los valores que faltan, la falta de estandarización o cualquier otra discrepancia en sus datos. Al perfilar sus datos, puede cuantificar rápidamente el alcance y la profundidad del proyecto principal, ya sea la gestión de datos maestros, la correspondencia, la limpieza, la deduplicación o la estandarización.
Una vez que haya perfilado sus datos, sabrá exactamente qué reglas de negocio aplicar para limpiar y estandarizar sus datos de la manera más eficiente. También podrá reconocer y rellenar rápidamente los valores que faltan, quizás comprando datos de terceros.
Unos datos más limpios y completos reducen significativamente los falsos positivos y negativos al aumentar la precisión de las coincidencias, ya que sus datos están estandarizados. Los algoritmos de concordancia difusa que se utilizan, los criterios de concordancia que se definen, el peso que se asigna a los distintos parámetros, la forma en que se combinan los distintos algoritmos y se asigna la prioridad… todos ellos son factores importantes para minimizar los falsos positivos y negativos. Pero nada de esto va a servir de mucho si no se han perfilado y limpiado los datos primero. Vea cómo DataMatch Enterprise ha ayudado a más de 4.000 clientes en más de 40 países a limpiar, desduplicar y vincular sus datos de forma eficiente.
Guiones de emparejamiento difuso frente a software de emparejamiento difuso: ¿Cuál es mejor?
Guiones de concordancia difusa
La lógica difusa puede aplicarse fácilmente a partir de scripts de codificación manual que están disponibles en varios lenguajes de programación y aplicaciones. Algunas de ellas son:
– Python: Las bibliotecas de Python, como FuzzyWuzzy, se pueden utilizar para ejecutar la coincidencia de cadenas de un método fácil e intuitivo. Usando el Tookit de Vinculación de Registros de Python, los usuarios pueden ejecutar varios métodos de indexación, incluyendo vecindad ordenada y bloqueo, e identificar duplicados usando FuzzyWuzzy. Aunque Python es fácil de usar, puede ser más lento a la hora de ejecutar partidos que otros métodos.
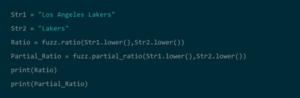
Fuente: DataCamp
– Java : Java incluye varios algoritmos de similitud de cadenas, como el paquete java-string-similarity, que consta de algoritmos como Levenshtein, índice de Jaccard y Jaro-Wrinkler. Alternativamente, el algoritmo de python FuzzyWuzzy puede ser utilizado dentro de Java para ejecutar coincidencias. A continuación, un ejemplo:

Fuente: GitHub
– Excel: El complemento Fuzzy Look-up se puede utilizar para ejecutar la correspondencia difusa entre dos conjuntos de datos. El complemento tiene una interfaz sencilla que incluye la opción de seleccionar las columnas de salida, así como el número de coincidencias y el umbral de similitud. Sin embargo, la funcionalidad también puede dar altos falsos positivos ya que puede no identificar correctamente los duplicados. Un ejemplo de ello es «ATT CORP» y «AT&T Inc.
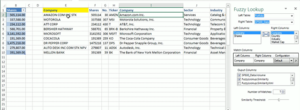
Fuente: Mr.Excel.com
Software de concordancia difusa
Por otro lado, el software de concordancia difusa está equipado con uno o varios algoritmos de lógica difusa, junto con la concordancia exacta y fonética, para identificar y concordar registros a través de millones de puntos de datos de fuentes de datos múltiples y dispares, incluyendo bases de datos relacionales, aplicaciones web y CRM.
Las herramientas de cotejo difuso vienen con funciones de calidad de datos preconfiguradas, como la elaboración de perfiles de datos y las transformaciones de limpieza y normalización de datos, para perfeccionar y mejorar eficazmente la precisión de las coincidencias entre dos o más conjuntos de datos.
A diferencia de los scripts de concordancia, estas herramientas son mucho más fáciles de desplegar y ejecutar los partidos gracias a una interfaz de apuntar y hacer clic.
¿Qué es mejor?
La elección de uno de los dos enfoques se reduce a los siguientes factores:
Tiempo
Los scripts de concordancia tienen la ventaja de ser fáciles de desplegar a conveniencia de los usuarios. Sin embargo, el constante perfeccionamiento y las pruebas necesarias para garantizar su eficacia, especialmente en cientos y miles de registros, pueden suponer semanas, si no meses, de trabajo. En situaciones en las que hay que encontrar duplicados y coincidencias con mayor rapidez para cumplir con los ajustados plazos de los proyectos, una herramienta de coincidencia difusa resulta mucho más fiable y conveniente para realizar coincidencias en conjuntos de datos muy grandes en un plazo de días o de unas pocas horas.
Coste
Los guiones de codificación manual son poco costosos en comparación con las herramientas de cotejo, siempre que el número de registros sea pequeño. Sin embargo, en el caso de conjuntos de datos compuestos por millones o miles de millones de registros, el coste de utilizar scripts puede superar con creces el de las herramientas de cotejo, teniendo en cuenta el tiempo y los recursos utilizados para atender a los
Escalabilidad
Los scripts de lógica difusa tienden a funcionar mejor para unos pocos miles de registros, en los que las variaciones de los datos no son demasiadas; de lo contrario, las reglas pueden fallar y requerir más refinamiento, lo que dificulta su escalabilidad.
Una herramienta de cotejo difuso que viene equipada con la capacidad de ejecutar cotejos con millones de puntos de datos en pocas horas, así como con capacidades de automatización por lotes y en tiempo real para minimizar las tareas repetitivas y las horas de trabajo.
Complejidad de los datos
Los usuarios pueden querer encontrar coincidencias o duplicados en unos cuantos miles de registros. En cambio, los organismos federales, las instituciones públicas y las empresas suelen tener conjuntos de datos no homogéneos procedentes de múltiples fuentes (Excel, CSV, bases de datos relacionales, datos de mainframe heredados y repositorios basados en Hadoop).
En cambio, en el caso de los scripts de codificación manual, los usuarios tienen que escribir múltiples y complejas reglas de lógica difusa para tener en cuenta la disparidad de los datos y sus anomalías, lo que resulta muy tedioso y requiere mucho tiempo.
Es fácil, rápido y está centrado en la creación de valor empresarial
Tradicionalmente, el fuzzy matching se ha considerado un arte complejo y arcano, en el que los costes de los proyectos suelen ser de cientos de miles de dólares, se tarda meses, si no años, en obtener un retorno de la inversión tangible, e incluso entonces, siguen existiendo problemas de seguridad, escalabilidad y precisión. Esto ya no es así con los modernos programas de calidad de datos. Basado en décadas de investigación y más de 4.000 implantaciones en más de 40 países, DataMatch Enterprise es una aplicación de limpieza de datos muy visual diseñada específicamente para resolver problemas de calidad de datos. La plataforma aprovecha múltiples algoritmos patentados y estándar para identificar variaciones fonéticas, difusas, con claves erróneas, abreviadas y específicas del dominio.
Construya configuraciones escalables para la deduplicación y la vinculación de registros, la supresión, la mejora, la extracción y la estandarización de datos empresariales y de clientes, y cree una única fuente de verdad para maximizar el impacto de sus datos en toda la empresa.
Cómo ejecutarlo en DataMatch Enterprise
Ejecutar el fuzzy matching en DataMatch Enterprise es un proceso sencillo, paso a paso, que comprende lo siguiente:
- Importación de datos
- Perfilado de datos
- Depuración y normalización de datos
- Configuración del partido
- Definiciones de los partidos y
- Resultados de los partidos
En primer lugar, importamos los conjuntos de datos que utilizaremos para encontrar coincidencias y utilizamos la opción de vista previa de datos para echar un vistazo a los registros. En nuestro ejemplo, son «Maestro de clientes» y «Nuevos registros de clientes potenciales», como se muestra a continuación.
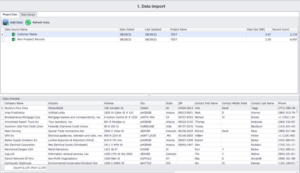
En segundo lugar, pasamos al módulo de perfil de datos para identificar todo tipo de anomalías en los datos estadísticos, errores y posibles áreas problemáticas que habría que arreglar o perfeccionar antes de pasar a cualquier cotejo.
Como se muestra a continuación, el conjunto de datos de nuevos registros de clientes potenciales se perfila en términos de registros válidos e inválidos, valores nulos, distintos, sólo números, sólo letras, espacios iniciales, errores de puntuación y mucho más.
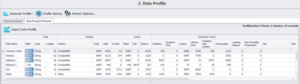
Una vez que hemos elaborado el perfil, pasamos al módulo de limpieza y normalización de datos, en el que corregimos los errores de codificación, eliminamos los espacios iniciales y finales, sustituimos los ceros por os y viceversa y analizamos campos como el nombre y la dirección en varios incrementos más pequeños.
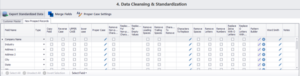
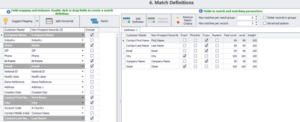
Después de refinar nuestros datos, seleccionamos el tipo de configuración de coincidencia que necesitamos para nuestra actividad de coincidencia: Todos, Entre, Dentro o Ninguno. Para nuestro ejemplo, seleccionaremos Entre para encontrar coincidencias sólo en los dos conjuntos de datos.

En Match Definitions, seleccionaremos la definición de coincidencia o los criterios de coincidencia y ‘Fuzzy’ (dependiendo de nuestro caso de uso) como establecer el nivel de umbral de coincidencia en ’90’ y utilizar la coincidencia ‘Exacta’ para los campos Ciudad y Estado y luego hacer clic en ‘Match’.
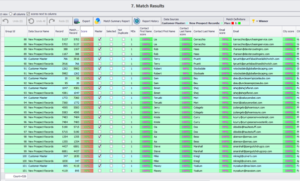
Según nuestra definición de coincidencia, el conjunto de datos y el grado de depuración y estandarización, obtenemos 526 coincidencias, cada una de ellas con una puntuación de coincidencia correspondiente desde el 100% y por debajo. Si necesitamos más falsos positivos para inspeccionarlos manualmente, los usuarios pueden volver a bajar el nivel del umbral fácilmente.
Para más información sobre cómo puede implementar la concordancia difusa en DataMatch Enterprise para su caso de uso empresarial,
contacte con nosotros hoy mismo.

Cómo funcionan las mejores soluciones de concordancia difusa de su clase: Combinando algoritmos establecidos y propios
Descargar
Las empresas necesitan las mejores herramientas para procesar estos datos y darles sentido. Este libro blanco explorará los desafíos de la correspondencia, cómo funcionan los diferentes tipos de algoritmos de correspondencia y cómo el mejor software utiliza estos algoritmos para lograr los objetivos de correspondencia de datos.



