





























Last Updated on janvier 7, 2022
Dans ce blog :
- Qualité des données – Pouvez-vous utiliser les données dont vous disposez ?
- Quelles sont les dimensions de la qualité des données ?
- Combien y a-t-il de dimensions de la qualité des données ?
- Quelles dimensions de la qualité des données utiliser ?
- Automatisation de la mesure de la qualité des données avec DataMatch Enterprise
« 84 % des PDG sont préoccupés par la qualité des données sur lesquelles ils fondent leurs décisions. »
2016 Global CEO Outlook, Forbes Insight et KPMG
Presque tous les processus dans le monde subissent une transformation numérique. La valeur de l’information physique se déprécie et l’information numérique retient davantage l’attention, et donc la consommation. La numérisation des processus s’accompagne d’une forte augmentation de la production et de la collecte de données. Les chercheurs et les spécialistes en informatique travaillent à l’introduction de nouvelles unités de stockage de données, telles que le Zettabyte (10^21 octets), le Yottabyte (10^24 octets), le Brontobyte (10^27 octets) et le Geopbyte (10^30 octets).
Qualité des données – Pouvez-vous utiliser les données dont vous disposez ?
La situation devient complexe lorsqu’il s’agit d’utiliser les données stockées dans des sources disparates. La principale difficulté rencontrée au cours d’un processus de transformation numérique consiste à utiliser les données et leurs attributs de manière efficace et aux fins prévues.
La norme ISO/IEC 25012 définit la qualité des données comme le degré auquel les données satisfont aux exigences de leur finalité. Si les données stockées ne sont pas en mesure de répondre aux exigences de l’organisation, on dit qu’elles sont de mauvaise qualité ; et le coût de la mauvaise qualité des données est fortement sous-estimé.
Quelles sont les dimensions de la qualité des données ?
Cette définition proposée par la norme ISO implique que la signification de la qualité des données varie en fonction de l’utilisation que l’on souhaite en faire. Par exemple, dans certains cas, la précision des données est plus importante que leur exhaustivité, alors que dans d’autres cas, c’est l’inverse.
Ce concept introduit l’idée de dimensions de la qualité des données – ce qui signifie simplement que la qualité des données peut être mesurée de différentes manières. Les dimensions de la qualité des données présentent une liste de mesures qui peuvent aider à évaluer l’aptitude des données pour toute utilisation prévue.
Combien y a-t-il de dimensions de la qualité des données ?
Certains mettent en avant six dimensions de la qualité des données, tandis que d’autres parlent de huit, voire de dix dimensions de qualité des données. Techniquement parlant, toutes les mesures de la qualité des données relèvent de deux grandes catégories : la première concerne les caractéristiques intrinsèques des données, tandis que la seconde porte sur leurs caractéristiques contextuelles.
Dimensions de la qualité des données correspondant à la hiérarchie des données
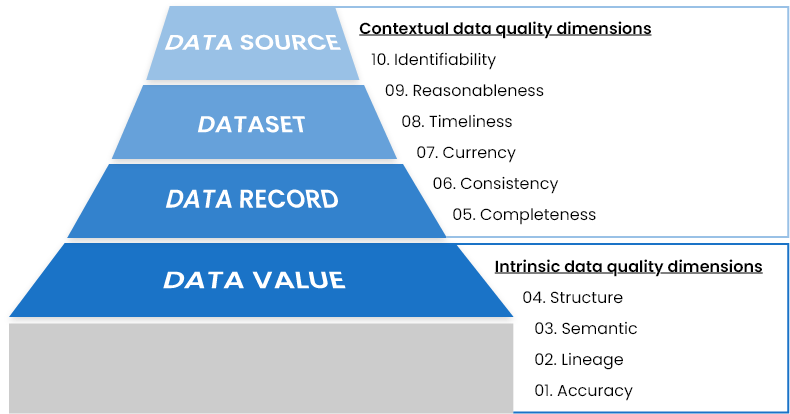
La hiérarchie des données dans toute organisation commence par une seule valeur de données. Les valeurs de données de divers attributs sont regroupées pour une entité ou une occurrence spécifique afin de former un enregistrement de données. Plusieurs enregistrements de données (représentant plusieurs occurrences du même type) sont regroupés pour former un ensemble de données. Ces ensembles de données peuvent résider dans n’importe quelle source ou application pour répondre aux besoins d’une organisation.
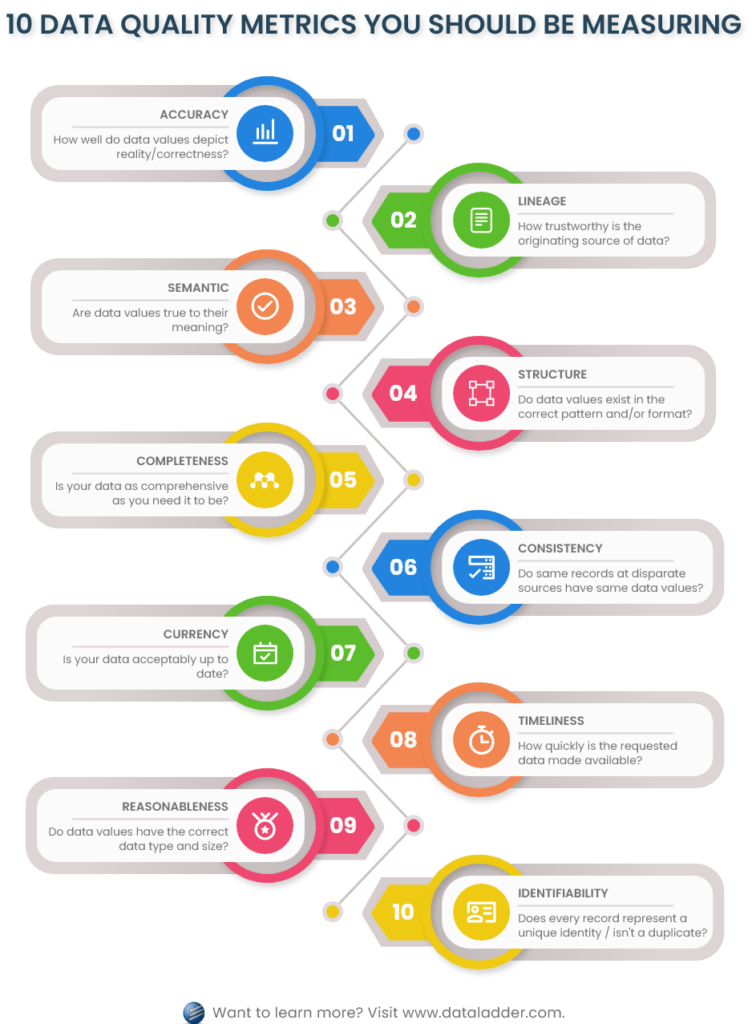
Les dimensions de la qualité des données se comportent et sont mesurées différemment à chaque niveau de la hiérarchie des données. Voir l’image suivante pour comprendre comment la qualité des données est évaluée à chaque niveau.
Dans cet article, nous allons couvrir ces dix dimensions de qualité des données qui sont divisées en deux catégories.
A. Dimensions intrinsèques de la qualité des données
Ces dimensions permettent d’apprécier et d’évaluer directement la valeur des données – au niveau granulaire ; leur signification, leur disponibilité, leur domaine, leur structure, leur format, leurs métadonnées, etc. Ces dimensions ne tiennent pas compte du contexte dans lequel la valeur a été stockée, comme sa relation avec d’autres attributs ou l’ensemble de données dans lequel elle réside.
Les quatre dimensions suivantes de la qualité des données relèvent de la catégorie intrinsèque :
1. Précision
DANS QUELLE MESURE LES VALEURS DES DONNÉES REPRÉSENTENT-ELLES LA RÉALITÉ/LA JUSTESSE ?
L’exactitude des valeurs desdonnées est mesurée en les vérifiant par rapport à une source connue d’informations correctes. Cette mesure peut être complexe si plusieurs sources contiennent des informations correctes. Dans ce cas, vous devez sélectionner celle qui correspond le mieux à votre domaine et calculer le degré de concordance de chaque valeur de données avec la source.
Exemple de valeurs de données précises
Considérons une base de données d’employés qui contient le numéro de contact des employés comme attribut. Un numéro de téléphone exact est celui qui est correct et qui existe dans la réalité. Vous pouvez vérifier tous les numéros de téléphone de votre base de données des employés en les comparant à une base de données officielle contenant une liste de numéros de téléphone valides.
2. Lignage
DANS QUELLE MESURE LA SOURCE D’ORIGINE DES VALEURS DES DONNÉES EST-ELLE FIABLE ?
La lignée des valeurs des données est vérifiée ou testée en validant la source d’origine, et/ou toutes les sources qui ont mis à jour les informations au fil du temps. Il s’agit d’une mesure importante car elle prouve la fiabilité des données capturées, et leur évolution dans le temps.
Exemple de lignée de valeurs de données
Dans l’exemple ci-dessus, les numéros de contact des employés sont dignes de confiance s’ils proviennent d’une source valide. Et la source la plus valable pour ce type d’information est l’employé lui-même – que les données soient saisies la première fois ou mises à jour au fil du temps. Par ailleurs, si les numéros de contact ont été déduits d’un annuaire téléphonique public, cette source d’origine est certainement douteuse et peut potentiellement contenir des erreurs.
3. Sémantique
LES VALEURS DES DONNÉES SONT-ELLES FIDÈLES À LEUR SIGNIFICATION ?
Pour garantir la qualité des données, la valeur des données doit être sémantiquement correcte, c’est-à-dire liée à sa signification, notamment dans le contexte de l’organisation ou du service où elle est utilisée. Les informations sont généralement échangées entre les différents services et processus d’une entreprise. Dans ce cas, les parties prenantes et les utilisateurs des données doivent s’accorder sur la signification de tous les attributs impliqués dans l’ensemble de données, afin qu’ils puissent être vérifiés sémantiquement.
Exemple de valeurs de données sémantiquement correctes
Votre base de données des employés peut avoir deux attributs qui stockent les numéros de contact des employés, à savoir Numéro de téléphone 1 et Numéro de téléphone 2. Une définition convenue des deux attributs pourrait être que le numéro de téléphone 1 est le numéro de portable personnel de l’employé, tandis que le numéro de téléphone 2 est son numéro de téléphone résidentiel.
Il est important de noter que la mesure d’exactitude validera l’existence et la réalité de ces deux numéros, mais que la mesure sémantique garantira que ces deux numéros sont fidèles à leur définition implicite – c’est-à-dire que le premier est un numéro de portable, tandis que le second est un numéro de téléphone résidentiel.
4. Structure
LES VALEURS DES DONNÉES EXISTENT-ELLES DANS LE MODÈLE ET/OU LE FORMAT CORRECT ?
L’analyse structurelle consiste à vérifier la représentation des valeurs des données – c’est-à-dire que les valeurs ont un modèle et un format valides. Il est préférable que ces contrôles soient effectués et appliqués lors de la saisie et de l’enregistrement des données, de sorte que toutes les données entrantes soient d’abord validées et, si nécessaire, transformées avant d’être stockées dans l’application.
Exemple de valeurs de données structurellement correctes
Dans l’exemple ci-dessus de la base de données des employés, toutes les valeurs de la colonne du numéro de téléphone 1 doivent être correctement structurées et formatées. Un exemple de numéro de téléphone mal structuré est le suivant : 134556-7(9080. Il est toutefois possible que le chiffre lui-même (sans le trait d’union et les parenthèses supplémentaires) soit exact et sémantiquement correct. Mais le format et le modèle corrects du numéro devraient être :
+1-345-567-9080.
B. Dimensions contextuelles de la qualité des données
Ces dimensions apprécient et évaluent les données dans leur contexte global – par exemple, en considérant toutes les valeurs de données d’un attribut ensemble, ou les valeurs de données regroupées dans des enregistrements, etc. Ces dimensions se concentrent sur les relations entre les différents composants des données et leur adéquation aux attentes en matière de qualité des données.
Les six dimensions suivantes de la qualité des données relèvent de la catégorie contextuelle :
5. Complétude
VOS DONNÉES SONT-ELLES AUSSI COMPLÈTES QUE VOUS LE SOUHAITEZ ?
L’exhaustivité définit le degré auquel les valeurs de données nécessaires sont remplies et ne sont pas laissées en blanc. Elle peut être calculée verticalement (au niveau des attributs) ou horizontalement (au niveau des enregistrements). En général, les champs sont marqués comme obligatoires/exigés pour garantir l’exhaustivité d’un ensemble de données. Lors du calcul de l’exhaustivité, ses trois différents types doivent être pris en compte pour garantir l’exactitude des résultats :
- Champ obligatoire qui ne peut être laissé vide ; par exemple, l’identifiant national d’un employé.
- Champ facultatif qui ne doit pas nécessairement être rempli ; par exemple, le champ « Hobbies » d’un employé.
- Champ inapplicable qui devient non pertinent en fonction du contexte de l’enregistrement et qui doit être laissé vide ; par exemple, le nom du conjoint pour un individu non marié.
Exemple de données complètes
Un exemple d’exhaustivité verticale consiste à calculer le pourcentage d’employés pour lesquels le numéro de téléphone 1 est fourni. Et l’exemple d’exhaustivité horizontale consiste à calculer le pourcentage d’informations complètes pour un employé particulier ; par exemple, les données d’un employé peuvent être complètes à 80 %, mais il manque son numéro de contact et son adresse résidentielle.
6. Cohérence
DES MAGASINS DE DONNÉES DISPARATES ONT-ILS LES MÊMES VALEURS DE DONNÉES POUR LES MÊMES ENREGISTREMENTS ?
La cohérence vérifie si les valeurs des données stockées pour le même enregistrement dans des sources disparates sont exemptes de toute contradiction et sont exactement les mêmes, tant en termes de signification que de structure et de format.
Des données cohérentes permettent d’établir des rapports uniformes et précis pour toutes les fonctions et opérations de votre entreprise. La cohérence ne concerne pas seulement la signification des valeurs des données, mais aussi leur représentation ; par exemple, lorsque des valeurs ne sont pas applicables ou sont indisponibles, des termes cohérents doivent être utilisés pour représenter l’indisponibilité des données dans toutes les sources.
Exemples de données cohérentes
Les informations sur les employés sont généralement stockées dans les applications de gestion des RH, mais la base de données doit être partagée ou répliquée pour d’autres services, comme la paie ou les finances. Pour garantir la cohérence, tous les attributs stockés dans les bases de données doivent avoir les mêmes valeurs. Sinon, une différence dans le numéro de compte bancaire ou d’autres champs critiques de ce type peut devenir un énorme problème.
7. Monnaie
VOS DONNÉES SONT-ELLES RAISONNABLEMENT À JOUR ?
L’actualité concerne la mesure dans laquelle les attributs des données sont du bon âge dans le contexte de leur utilisation. Cette mesure permet de maintenir les informations à jour et en conformité avec le monde actuel, de sorte que vos instantanés de données ne datent pas de plusieurs semaines ou mois, ce qui vous conduirait à présenter et à fonder des décisions critiques sur des informations périmées.
Pour garantir l’actualité de votre ensemble de données, vous pouvez définir des rappels pour la mise à jour des données, ou fixer des limites à l’âge d’un attribut, afin de garantir que toutes les valeurs sont soumises à un examen et à une mise à jour dans un délai donné.
Exemple de données actuelles
Les coordonnées de votre employé doivent être revues régulièrement pour vérifier si quelque chose a été récemment modifié et doit être mis à jour dans le système.
8. Respect des délais
DANS QUEL DÉLAI LES DONNÉES DEMANDÉES SONT-ELLES MISES À DISPOSITION ?
La rapidité d’exécution mesure le temps nécessaire pour accéder à l’information demandée. Si vos requêtes de données prennent trop de temps pour aboutir, il se peut que vos données ne soient pas bien organisées, reliées, structurées ou formatées.
L’actualité mesure également la rapidité avec laquelle les nouvelles informations sont disponibles pour être utilisées dans toutes les sources. Si votre entreprise utilise des processus complexes et fastidieux pour stocker les données entrantes, les utilisateurs peuvent finir par interroger et utiliser d’anciennes informations à certains moments.
Exemple de respect des délais
Pour garantir la rapidité d’exécution, vous pouvez vérifier le temps de réponse de votre base de données des employés. En outre, vous pouvez également tester le temps nécessaire pour que les informations mises à jour dans l’application RH soient reproduites dans l’application de paie, et ainsi de suite.
9. Caractère raisonnable
LES VALEURS DES DONNÉES ONT-ELLES LE TYPE ET LA TAILLE CORRECTS ?
Le caractère raisonnable mesure la mesure dans laquelle les valeurs des données ont un type et une taille raisonnables ou compréhensibles. Par exemple, il est courant de stocker des nombres dans un champ de chaîne alphanumérique, mais la rationalité fera en sorte que si un attribut ne stocke que des nombres, il doit être de type numérique.
De plus, reasonability impose également une limite maximale et minimale de caractères aux attributs, de sorte qu’il n’y ait pas de chaînes de caractères inhabituellement longues dans la base de données. La mesure de raisonnabilité réduit l’espace pour les erreurs en appliquant des contraintes sur le type de données et la taille d’un attribut.
Exemple de caractère raisonnable
Le champ Numéro de téléphone 1 – s’il est enregistré sans les traits d’union et les caractères spéciaux – doit être défini comme numérique et comporter une limite maximale de caractères afin que des caractères alphanumériques supplémentaires ne soient pas ajoutés par erreur.
10. Identifiabilité
CHAQUE ENREGISTREMENT REPRÉSENTE-T-IL UNE IDENTITÉ UNIQUE ET N’EST-IL PAS UN DOUBLON ?
L’identifiabilité calcule le degré auquel les enregistrements de données sont identifiables de manière unique et ne sont pas des doublons les uns des autres.
Pour garantir l’identifiabilité, un attribut d’identification unique est stocké dans la base de données pour chaque enregistrement. Mais dans certains cas, comme celui des organismes de santé, les informations personnelles identifiables (PII) sont supprimées pour préserver la confidentialité des patients. C’est là que vous pouvez avoir besoin d’utiliser des techniques de rapprochement floues pour comparer, rapprocher et fusionner des enregistrements.
Exemple d’identifiabilité
Un exemple d’identifiabilité consiste à exiger que chaque nouvel enregistrement dans la base de données des employés contienne un numéro d’identification unique qui permettra de les identifier.
Quelles dimensions de la qualité des données utiliser ?
Nous avons passé en revue les dix mesures de qualité des données les plus couramment utilisées. Chaque entreprise ayant ses propres exigences et indicateurs de performance clés, vous devrez peut-être utiliser d’autres indicateurs ou en créer de nouveaux. La sélection des dimensions de la qualité des données dépend de multiples facteurs, tels que le secteur d’activité de votre entreprise, la nature de vos données et le rôle qu’elles jouent dans la réussite de vos objectifs.
Étant donné que chaque secteur d’activité a ses propres règles en matière de données, son propre mécanisme d’établissement de rapports et ses propres critères de mesure, un ensemble différent de mesures de la qualité des données est adopté pour répondre aux besoins de chaque cas, par exemple les agences gouvernementales, les départements des finances et des assurances, les instituts de soins de santé, les ventes et le marketing, le commerce de détail ou les systèmes éducatifs, etc.
Automatisation de la mesure de la qualité des données avec DataMatch Enterprise
Compte tenu de la complexité de la mesure de la qualité des données, il s’agit d’un processus que l’on attend généralement de la part de professionnels compétents en matière de technologie ou de données. La non-disponibilité de capacités de profilage avancées dans un outil de qualité des données en libre-service est un défi communément rencontré.
Un outil de qualité des données en libre-service capable de produire une vue rapide à 360° des données et d’identifier les anomalies de base, telles que les valeurs vides, les types de données des champs, les modèles récurrents et d’autres statistiques descriptives, est une exigence de base pour toute initiative axée sur les données. DataMatch Enterprise de Data Ladder est une solution de qualité des données entièrement optimisée qui ne se contente pas d’offrir une évaluation de la qualité des données, mais procède à un nettoyage, une mise en correspondance et une fusion détaillés des données.
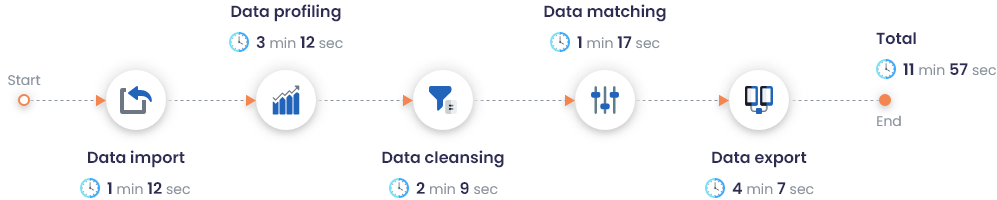
Performance de DME sur un jeu de données de 2M d’enregistrements
Avec DataMatch Enterprise, vous pouvez effectuer rapidement des contrôles d’exactitude, d’exhaustivité et de validation. Au lieu d’identifier et de marquer manuellement les divergences présentes dans votre ensemble de données, votre équipe peut, à elle seule, générer un rapport qui étiquette et numérote les différentes mesures de qualité des données en quelques secondes seulement, même avec un échantillon de 2 millions d’enregistrements.
Les performances de DataMatch Enterprise sur un jeu de données contenant 2M d’enregistrements ont été enregistrées comme suit :
Génération et filtrage de profils détaillés de qualité des données
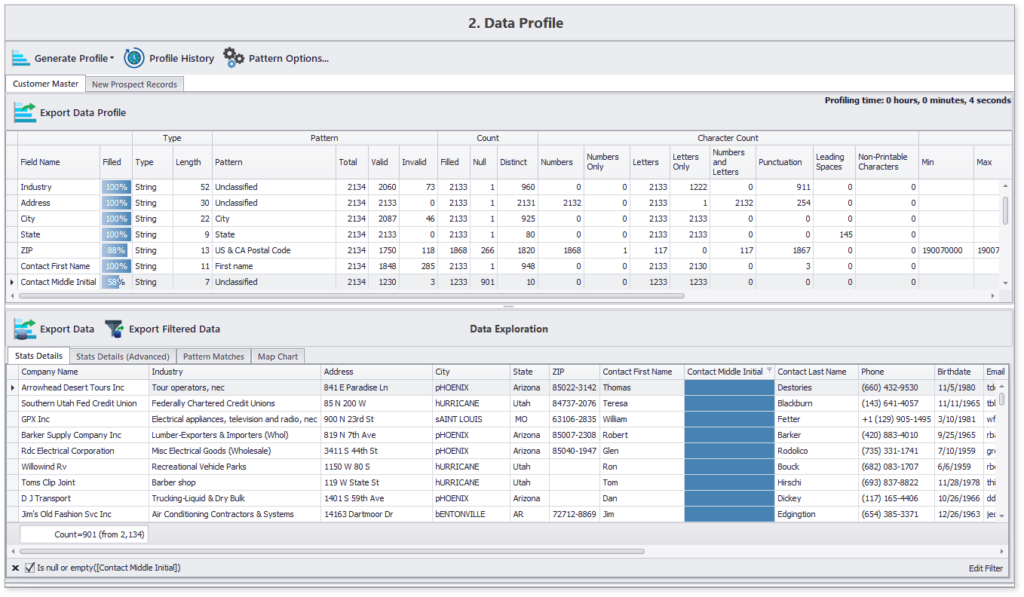
Voici un exemple de profil généré à l’aide de DME en moins de 10 secondes pour environ 2000 enregistrements :
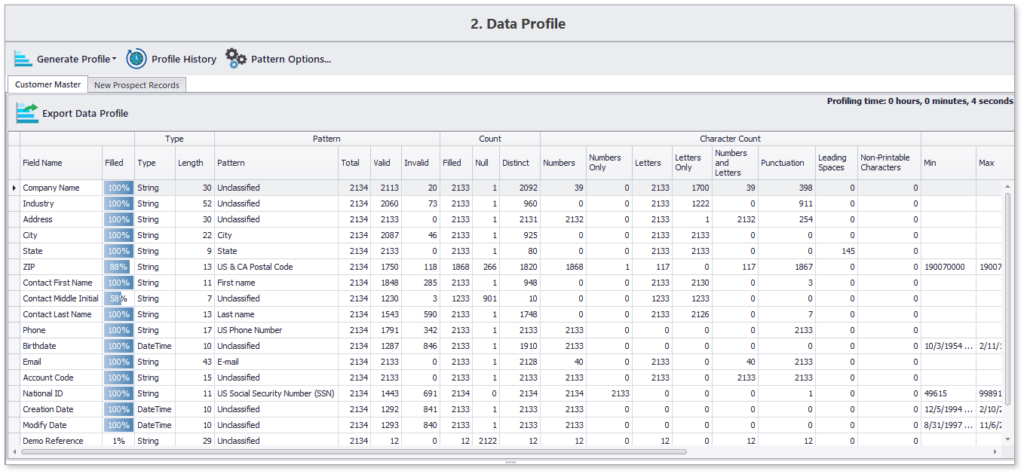
Ce profil de données concis met en évidence les détails du contenu et de la structure de tous les attributs de données choisis. En outre, vous pouvez également naviguer vers des éléments spécifiques, tels que la liste des 12% d’enregistrements auxquels il manque le deuxième prénom du contact.
Pour en savoir plus sur la façon dont notre solution peut vous aider à résoudre vos problèmes de qualité des données, inscrivez-vous à un essai gratuit dès aujourd’hui ou organisez une démonstration avec l’un de nos experts.



