




























Last Updated on enero 7, 2022
En este blog:
- Calidad de los datos – ¿Puede utilizar los datos que tiene?
- ¿Qué son las dimensiones de la calidad de los datos?
- ¿Cuántas dimensiones de calidad de datos hay?
- ¿Qué dimensiones de la calidad de los datos hay que utilizar?
- Automatización de la medición de la calidad de los datos con DataMatch Enterprise
«Al 84% de los directores generales les preocupa la calidad de los datos en los que basan sus decisiones».
2016 Global CEO Outlook, Forbes Insight y KPMG
Casi todos los procesos del mundo están en proceso de transformación digital. El valor de la información física se está depreciando y la información digital está recibiendo más atención y, por tanto, consumo. A medida que los procesos se digitalizan, se produce una gran afluencia en la generación y recopilación de datos. Los investigadores y especialistas en informática trabajan en la introducción de nuevas unidades de almacenamiento de datos, como el Zettabyte (10^21 bytes), el Yottabyte (10^24 bytes), el Brontobyte (10^27 bytes) y el Geopbyte (10^30 bytes).
Calidad de los datos – ¿Puede utilizar los datos que tiene?
La cosa se complica cuando llega el momento de utilizar los datos almacenados en fuentes dispares. La complicación número uno a la que se enfrenta un proceso de transformación digital es la de utilizar los datos y sus atributos de forma eficiente y para el fin previsto.
La norma ISO/IEC 25012 define la calidad de los datos como el grado en que los datos satisfacen los requisitos de su finalidad. Si los datos almacenados son incapaces de cumplir los requisitos de su organización, se dice que son de mala calidad; y el coste de la mala calidad de los datos está muy subestimado.
¿Qué son las dimensiones de la calidad de los datos?
Esta definición propuesta por la norma ISO implica que el significado de la calidad de los datos varía en función del uso que se quiera hacer de ellos. Por ejemplo, en algunos casos, la precisión de los datos es más importante que la exhaustividad de los mismos, mientras que en otros casos puede ocurrir lo contrario.
Este concepto introduce la idea de las dimensiones de la calidad de los datos, lo que significa simplemente que la calidad de los datos puede medirse de diferentes maneras. Las dimensiones de la calidad de los datos presentan una lista de métricas que pueden ayudar a evaluar la idoneidad de los datos para cualquier uso previsto.
¿Cuántas dimensiones de calidad de datos hay?
Algunos destacan seis dimensiones de la calidad de los datos, mientras que otros hablan de ocho o incluso diez dimensiones de la calidad de los datos. Desde el punto de vista técnico, todas las métricas de calidad de los datos se dividen en dos grandes categorías: la primera se refiere a las características intrínsecas de los datos, mientras que la segunda se refiere a sus características contextuales.
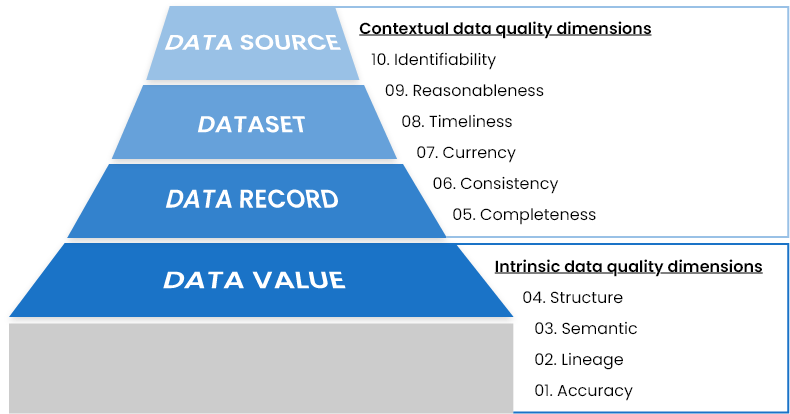
Dimensiones de la calidad de los datos correspondientes a la jerarquía de datos
La jerarquía de datos en cualquier organización comienza con un único valor de datos. Los valores de los datos de varios atributos se agrupan para una entidad u ocurrencia específica para formar un registro de datos. Los registros de datos múltiples (que representan múltiples ocurrencias del mismo tipo) se agrupan para formar un conjunto de datos. Estos conjuntos de datos pueden residir en cualquier fuente o aplicación para satisfacer las necesidades de una organización.
Las dimensiones de la calidad de los datos se comportan y se miden de forma diferente en cada nivel de la jerarquía de datos. Vea la siguiente imagen para entender cómo se evalúa la calidad de los datos en cada nivel.
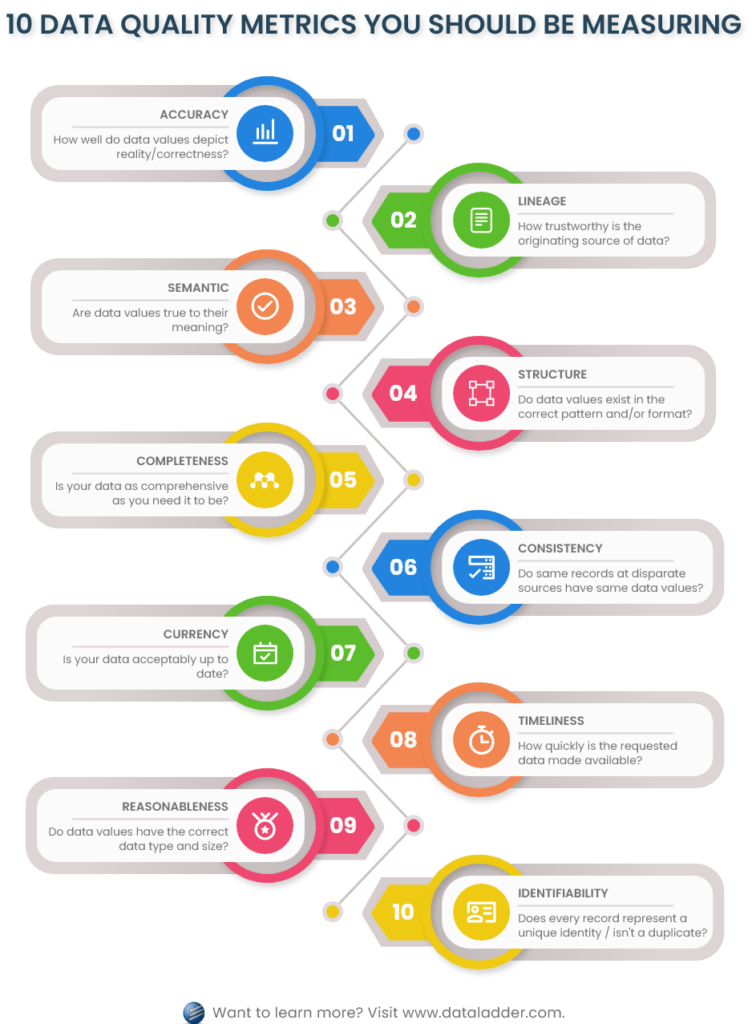
En este artículo, cubriremos estas diez dimensiones de calidad de datos que se dividen en dos categorías.
A. Dimensiones intrínsecas de la calidad de los datos
Estas dimensiones evalúan directamente el valor de los datos, a nivel granular; su significado, disponibilidad, dominio, estructura, formato y metadatos, etc. Estas dimensiones no tienen en cuenta el contexto en el que se almacenó el valor, como su relación con otros atributos o el conjunto de datos en el que reside.
Las siguientes cuatro dimensiones de la calidad de los datos pertenecen a la categoría intrínseca:
1. Precisión
¿EN QUÉ MEDIDA LOS VALORES DE LOS DATOS REPRESENTAN LA REALIDAD/CORRECCIÓN?
Laprecisión de los valores delos datos se mide verificándolos con una fuente conocida de información correcta. Esta medición podría ser compleja si hay múltiples fuentes que contienen la información correcta. En estos casos, hay que seleccionar el más inclusivo para su dominio, y calcular el grado de concordancia de cada valor de los datos con la fuente.
Ejemplo de valores de datos precisos
Considere una base de datos de empleados que contiene el número de contacto de los empleados como atributo. Un número de teléfono exacto es el que es correcto y existe en la realidad. Puede verificar todos los números de teléfono de su base de datos de empleados cotejándolos con una base de datos oficial que contenga una lista de números de teléfono válidos.
2. Linaje
¿HASTA QUÉ PUNTO ES FIABLE LA FUENTE DE ORIGEN DE LOS VALORES DE LOS DATOS?
El linaje de los valores de los datos se verifica o comprueba validando la fuente de origen, y/o todas las fuentes que han actualizado la información a lo largo del tiempo. Se trata de una medida importante, ya que demuestra la fiabilidad de los datos captados y su evolución en el tiempo.
Ejemplo de linaje de valores de datos
En el ejemplo anterior, los números de contacto de los empleados son fiables si proceden de una fuente válida. Y la fuente más válida para este tipo de información es el propio empleado, ya que los datos se introducen la primera vez o se actualizan con el tiempo. Por otra parte, si los números de contacto se dedujeron de una guía telefónica pública, esta fuente de origen es definitivamente cuestionable y podría contener errores.
3. Semántica
¿LOS VALORES DE LOS DATOS SON FIELES A SU SIGNIFICADO?
Para garantizar la calidad de los datos, el valor de los mismos debe ser semánticamente correcto, lo que se refiere a su significado, especialmente en el contexto de la organización o el departamento en el que se utilizan. La información suele intercambiarse entre los distintos departamentos y procesos de una empresa. En estos casos, las partes interesadas y los usuarios de los datos deben estar de acuerdo con el significado de todos los atributos que intervienen en el conjunto de datos, para que puedan ser verificados semánticamente.
Ejemplo de valores de datos semánticamente correctos
Su base de datos de empleados puede tener dos atributos que almacenan los números de contacto de los empleados, a saber, Número de teléfono 1 y Número de teléfono 2. Una definición acordada de ambos atributos podría ser que el número de teléfono 1 es el número de móvil personal del empleado, mientras que el número de teléfono 2 es su número de teléfono residencial.
Es importante señalar que la medida de exactitud validará la existencia y la realidad de ambos números, pero la medida semántica garantizará que ambos números son fieles a su definición implícita, es decir, que el primero es un número de móvil, mientras que el segundo es un número de teléfono residencial.
4. Estructura
¿EXISTEN VALORES DE DATOS EN EL PATRÓN Y/O FORMATO CORRECTO?
El análisis estructural se refiere a la verificación de la representación de los valores de los datos, es decir, que los valores tengan un patrón y un formato válidos. Estas comprobaciones se realizan mejor y se aplican en la entrada y captura de datos, de modo que todos los datos entrantes se validan primero y, si es necesario, se transforman como es debido, antes de almacenarlos en la aplicación.
Ejemplo de valores de datos estructuralmente correctos
En el ejemplo anterior de base de datos de empleados, todos los valores de la columna de Número de teléfono 1 deben estar correctamente estructurados y formateados. Un ejemplo de número de teléfono mal estructurado es: 134556-7(9080. Aunque es posible que el número en sí mismo (sin el guión y el paréntesis adicionales) sea preciso y semánticamente correcto. Pero el formato y el patrón correctos del número deben ser:
+1-345-567-9080.
B. Dimensiones de la calidad de los datos contextuales
Estas dimensiones valoran y evalúan los datos en todo su contexto, por ejemplo, considerando todos los valores de los datos de un atributo juntos, o los valores de los datos agrupados en registros, etc. Estas dimensiones se centran en las relaciones entre los distintos componentes de los datos y su adecuación a las expectativas de calidad de los mismos.
Las siguientes seis dimensiones de la calidad de los datos pertenecen a la categoría contextual:
5. Completitud
¿SON SUS DATOS TAN COMPLETOS COMO NECESITA?
La exhaustividad define el grado en que se rellenan los valores de datos necesarios y no se dejan en blanco. Puede calcularse de forma vertical (a nivel de atributos) u horizontal (a nivel de registros). Normalmente, los campos se marcan como obligatorios/requeridos para garantizar la integridad de un conjunto de datos. Al calcular la exhaustividad, hay que tener en cuenta sus tres tipos diferentes para garantizar la exactitud de los resultados:
- Campo obligatorio que no puede dejarse vacío; por ejemplo, el DNI de un empleado.
- Campo opcional que no tiene que ser necesariamente rellenado; por ejemplo, el campo de aficiones de un empleado.
- Campo inaplicable que resulta irrelevante según el contexto del registro, y debe dejarse en blanco; por ejemplo, Nombre del cónyuge para una persona no casada.
Ejemplo de datos completos
Un ejemplo de exhaustividad vertical es el cálculo del porcentaje de empleados para los que se proporciona el número de teléfono 1. Y el ejemplo de la exhaustividad horizontal consiste en calcular el porcentaje de información que está completa para un empleado concreto; por ejemplo, los datos de un empleado pueden estar completos en un 80%, cuando falta su número de contacto y su dirección residencial.
6. Consistencia
¿TIENEN LOS ALMACENES DE DATOS DISPARES LOS MISMOS VALORES DE DATOS PARA LOS MISMOS REGISTROS?
La coherencia comprueba si los valores de los datos almacenados para el mismo registro en fuentes dispares no presentan contradicciones y son exactamente iguales, tanto en términos de significado como de estructura y formato.
Los datos coherentes ayudan a realizar informes uniformes y precisos en todas las funciones y operaciones de su empresa. La coherencia no sólo se refiere a los significados de los valores de los datos, sino también a su representación; por ejemplo, cuando los valores no son aplicables o no están disponibles, deben utilizarse términos coherentes para representar la falta de disponibilidad de los datos en todas las fuentes.
Ejemplos de datos coherentes
La información de los empleados suele almacenarse en las aplicaciones de gestión de RRHH, pero la base de datos debe compartirse o replicarse también para otros departamentos, como el de nóminas o el financiero. Para garantizar la coherencia, todos los atributos almacenados en las bases de datos deben tener los mismos valores. De lo contrario, la diferencia en el número de cuenta bancaria u otros campos críticos puede convertirse en un gran problema.
7. Moneda
¿ESTÁN SUS DATOS ACEPTABLEMENTE ACTUALIZADOS?
La vigencia se refiere al grado de antigüedad de los atributos de los datos en el contexto de su uso. Esta medida ayuda a mantener la información actualizada y conforme al mundo actual, de modo que sus instantáneas de datos no tengan semanas o meses de antigüedad, lo que le llevaría a presentar y basar decisiones críticas en información obsoleta.
Para garantizar la actualidad de su conjunto de datos, puede establecer recordatorios para actualizar los datos, o establecer límites a la antigüedad de un atributo, garantizando que todos los valores se sometan a revisión y actualización en un tiempo determinado.
Ejemplo de datos actuales
La información de contacto de su empleado debe ser revisada oportunamente para comprobar si algo ha cambiado recientemente y debe ser actualizado en el sistema.
8. Puntualidad
¿CON QUÉ RAPIDEZ SE FACILITAN LOS DATOS SOLICITADOS?
La puntualidad mide el tiempo que se tarda en acceder a la información solicitada. Si sus solicitudes de datos tardan demasiado en terminar, puede ser que sus datos no estén bien organizados, relacionados, estructurados o formateados.
La puntualidad también mide la rapidez con la que la nueva información está disponible para su uso en todas las fuentes. Si su empresa emplea procesos complejos y lentos para almacenar los datos entrantes, los usuarios pueden acabar consultando y utilizando información antigua en algunos puntos.
Ejemplo de puntualidad
Para garantizar la puntualidad, puede comprobar el tiempo de respuesta de su base de datos de empleados. Además, también puede probar cuánto tarda la información actualizada en la aplicación de RRHH en replicarse en la aplicación de nóminas, etc.
9. Razonabilidad
¿LOS VALORES DE LOS DATOS TIENEN EL TIPO Y EL TAMAÑO CORRECTOS?
La razonabilidad mide el grado en que los valores de los datos tienen un tipo y un tamaño de datos razonables o comprensibles. Por ejemplo, es común almacenar números en un campo de cadena alfanumérica, pero la razonabilidad se asegurará de que si un atributo sólo almacena números, entonces debe ser de tipo numérico.
Además, la razonabilidad también impone un límite máximo y mínimo de caracteres en los atributos para que no haya cadenas inusualmente largas en la base de datos. La medida de razonabilidad reduce el espacio para los errores al imponer restricciones sobre el tipo de datos y el tamaño de un atributo.
Ejemplo de razonabilidad
El campo Número de teléfono 1 -si se almacena sin guiones ni caracteres especiales- debe ser numérico y tener un límite máximo de caracteres para que no se añadan por error caracteres alfanuméricos adicionales.
10. Identificabilidad
¿REPRESENTA CADA REGISTRO UNA IDENTIDAD ÚNICA Y NO ES UN DUPLICADO?
La identificabilidad calcula el grado en que los registros de datos son identificables de forma única y no son duplicados entre sí.
Para garantizar la identificabilidad, se almacena en la base de datos un atributo de identificación única para cada registro. Pero en algunos casos, como el de las organizaciones sanitarias, la información personal identificable (PII) se elimina para proteger la confidencialidad del paciente. Aquí es donde puede ser necesario realizar técnicas de concordancia difusa para comparar, hacer coincidir y fusionar registros.
Ejemplo de identificabilidad
Un ejemplo de identificabilidad es imponer que cada nuevo registro en la base de datos de empleados debe contener un número de identificación de empleado único a través del cual serán identificados.
¿Qué dimensiones de la calidad de los datos hay que utilizar?
Repasamos las diez métricas de calidad de datos más utilizadas. Dado que cada empresa tiene su propio conjunto de requisitos y KPI, es posible que tenga que utilizar otras métricas o crear otras personalizadas. La selección de las dimensiones de la calidad de los datos depende de múltiples factores, como el sector en el que opera su empresa, la naturaleza de sus datos y el papel que desempeñan en el éxito de sus objetivos.
Dado que cada sector tiene sus propias reglas de datos, mecanismo de información y criterios de medición, se adopta un conjunto diferente de métricas de calidad de datos para satisfacer las necesidades de cada caso, por ejemplo, organismos gubernamentales, departamentos de finanzas y seguros, institutos de salud, ventas y marketing, comercio minorista o sistemas educativos, etc.
Automatización de la medición de la calidad de los datos con DataMatch Enterprise
Teniendo en cuenta lo compleja que puede ser la medición de la calidad de los datos, es un proceso que normalmente se espera que realicen los profesionales de la tecnología o de los datos. La falta de disponibilidad de capacidades avanzadas de elaboración de perfiles en una herramienta de calidad de datos de autoservicio es un reto al que se suele hacer frente.
Una herramienta de autoservicio para la calidad de los datos que pueda ofrecer una rápida visión de 360º de los datos e identificar anomalías básicas, como valores en blanco, tipos de datos de campo, patrones recurrentes y otras estadísticas descriptivas, es un requisito básico para cualquier iniciativa basada en datos. Data Ladder’s DataMatch Enterprise es una solución de calidad de datos totalmente potenciada que no sólo ofrece una evaluación de la calidad de los datos, sino que además realiza una limpieza, correspondencia y fusión de datos detallada.
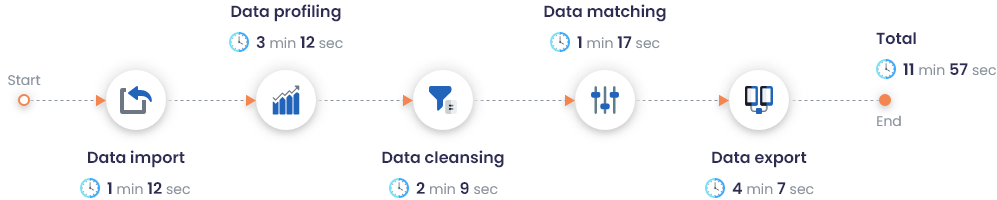
Rendimiento del ISD en un conjunto de datos de 2 millones de registros
Con DataMatch Enterprise, puede realizar comprobaciones rápidas de precisión, integridad y validación. En lugar de identificar y marcar manualmente las discrepancias presentes en su conjunto de datos; con el ISD, su equipo puede generar por sí solo un informe que etiquete y numere varias métricas de calidad de datos en sólo unos segundos, incluso con un tamaño de muestra tan grande como 2 millones de registros.
El rendimiento de DataMatch Enterprise en un conjunto de datos que contiene 2M de registros se registró de la siguiente manera:
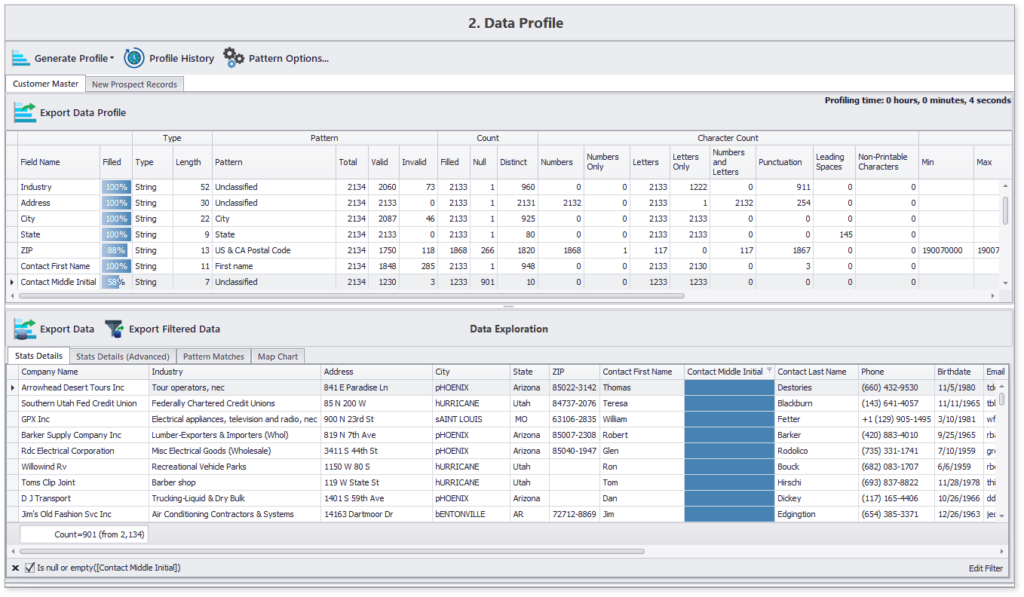
Generación y filtrado de perfiles de calidad de datos detallados
A continuación se muestra un perfil de muestra generado con el ISD en menos de 10 segundos para unos 2000 registros:
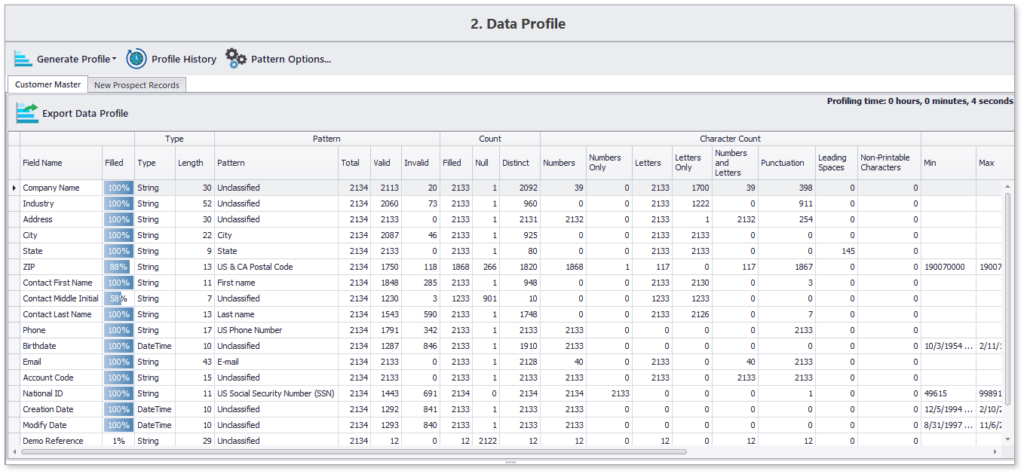
Este conciso perfil de datos destaca los detalles del contenido y la estructura de todos los atributos de datos elegidos. Además, también se puede navegar hacia aspectos específicos, como la lista de aquellos registros del 12% a los que les falta el segundo nombre del contacto.
Para saber más sobre cómo nuestra solución puede ayudarle a resolver sus problemas de calidad de datos, regístrese para una prueba gratuita hoy mismo o concierte una demostración con uno de nuestros expertos.



